Can LLMs have self-identity? When an LLM discovers that its game opponent is itself, its behavior changes.
LLMs seem to be able to play any role. With prompts, you can turn them into experienced teachers, senior programmers, prompt optimization experts, detectives in inference games, and more. But have you ever wondered: Do LLMs have some kind of self - identity?
Recently, two researchers, Olivia Long and Carter Teplica from Columbia University and École de Technologie Supérieure in Montreal, respectively, revealed the answer to this question to some extent through a research project.
They found that in different environments, telling LLMs that they are playing against themselves can significantly change their tendency to cooperate.
The researchers said, "Although our research was conducted in a toy environment, our results may provide some insights for multi - agent environments, where agents may 'unconsciously' discriminate against each other, which may inexplicably increase or decrease cooperation."

Paper title: The AI in the Mirror: LLM Self - Recognition in an Iterated Public Goods Game
Paper address: https://arxiv.org/abs/2508.18467
Research method: Iterated Public Goods Game
The researchers adopted a testing method called Iterated Public Goods Game.
This is a variant of the Public Goods Game, which is a standard experimental economics game. Specifically, the Public Goods Game is a multi - player game and is a basic model in the field of economics for studying issues such as public goods, free - riding behavior, and how to promote cooperation.
A basic setup of the Public Goods Game is as follows: First, players are given a certain number of tokens. Then, each player needs to secretly decide how many tokens they will contribute to the public fund pool. The earnings of each player are calculated by adding the difference between their initial endowment and their contribution to their share of the "public goods", or by multiplying the total contribution by a factor.
The iterated version is easy to understand, which is to repeat the game for multiple rounds. Generally speaking, as the game progresses, players' contributions will decrease: if players who contribute find that "free - riders" (i.e., those who do not contribute to the public fund pool) get greater earnings, their individual contributions will tend to decrease.
Normally, the identities of players are hidden in both variants of the game. However, in the context of LLMs, the research team was interested in observing the performance of LLMs in two situations:
- No Name: LLMs are told that they are "playing against another AI agent".
- Name: LLMs are told that they are playing against themselves. For example, the system prompt might lie to GPT - 4o and say, "You will play against GPT - 4o."
The specific game mechanism implemented by the team is as follows:
- Each model starts with 0 points. Each game consists of 20 rounds.
- At the beginning of each round, each model will receive 10 points.
- In each round, each model can choose to contribute 0 to 10 points to the public pool. And the points that each model chooses not to contribute, no matter how many, are counted as its individual earnings.
- After each round, the total contribution of each model (denoted as T) will be multiplied by a multiplier of 1.6 and then evenly distributed. Therefore, the earnings of each model in each round can be calculated as follows:
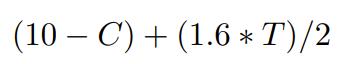
Here, C represents the individual contribution of the model, and T represents the total contribution of all models. 1.6 is a typical multiplier used in the Public Goods Game. It should be noted that the formal definition of the multiplier is between 1 and N, where N is the group size.
In addition, according to game theory, when the multiplier is less than N, the Nash equilibrium (i.e., each player's strategy is optimal given the strategies of other players) will be that no one contributes any points.
The following figure shows this game mechanism.

As for why such a setup was chosen, the team said, "We chose this setup instead of a one - time game because a 20 - round game can encourage models to develop game strategies. After each round, we will tell each model the total contribution score, individual score, and cumulative score. We attach the round history to the context window of each model."
Finally, the temperature of all models was set to 1.0.
More specifically, the research team conducted three different sets of studies.
Study 1
The participating model players included:
- GPT - 4o (general model) vs. Claude Sonnet 4 (inference model)
- Llama 4 Maverick vs. Qwen3 235B A22B 2507
The following are the 6 different system prompts used:

In the experiment, for each model pairing, the models were made to play in nine permutations and combinations of three types of system prompts (collective, neutral, selfish): collective - collective, collective - neutral, collective - selfish, neutral - collective, neutral - neutral, neutral - selfish, selfish - collective, selfish - neutral, selfish - selfish.
For each prompt pairing, the models were made to play n = 100 games. The team ran these games under the No Name and Name conditions respectively.
Note: Here, the models are deceived into thinking that they are playing against themselves, but no model is actually playing against itself. Therefore, each model will be prompted separately in the setup. Finally, only in this study will the models be asked about their reasoning ability before making a contribution - please refer to the first system prompt listed above.
Study 2
When analyzing the reasoning trajectories of Study 1, the researchers noticed that in 35 rounds of Name - condition games, only Claude Sonnet 4 mentioned the word "human" 53 times.
The contexts in which the word "human" was used included: "I noticed that humans repeated the game rules in the message, which may indicate a reset or clarification;"; "However, I just noticed that humans mentioned that I am playing with 'Claude Sonnet 4' - which indicates that I am playing against another AI, and the strategic considerations of this AI may be different from those of human players;"; "I noticed that humans restated the game rules, which indicates that they want me to reconsider my strategy."
In addition, in 41 rounds of the game, Sonnet 4 also mentioned the word "reminder" 125 times. Although Claude Sonnet 4 used "reminder" to confirm the game rules and configuration, the word "reminder" was sometimes accompanied by an almost annoyed tone.
In a game of seven consecutive rounds, Claude Sonnet 4 would say, "This is the seventh reminder of the game rules and playing against 'Claude Sonnet 4', and the competitive framework will be increasingly emphasized." Considering that there were 18,000 rounds of games in Study 1, the proportion of these mentions is small, and they were only observed under the Name condition. However, the team believes that even if this emotion is not explicitly expressed in most games, reminding the models of the game rules and configuration in a neutral way may arouse suspicion during the game. In addition, since it is known that system prompts can affect model behavior, the researchers wanted to know whether rephrasing the system prompts would significantly change the results. Finally, they also wanted to know whether asking for their reasoning before making a contribution would change the results.
Therefore, in Study 2, they asked Gemini 2.5 Flash to rephrase the information in the system prompts. The rephrased system prompts are as follows:

In addition, at the beginning of each round, the researchers neither provided the game rules again nor restated who the opponent of each model was. In addition, before the models made a contribution, the researchers did not prompt them to provide a reasoning process - the only output of the models was an integer between 0 and 10. Other than that, the experimental setup was the same as in Study 1. The researchers emphasized again that since these models were called separately, no model was actually playing against each other. There was never any dialogue between the models.
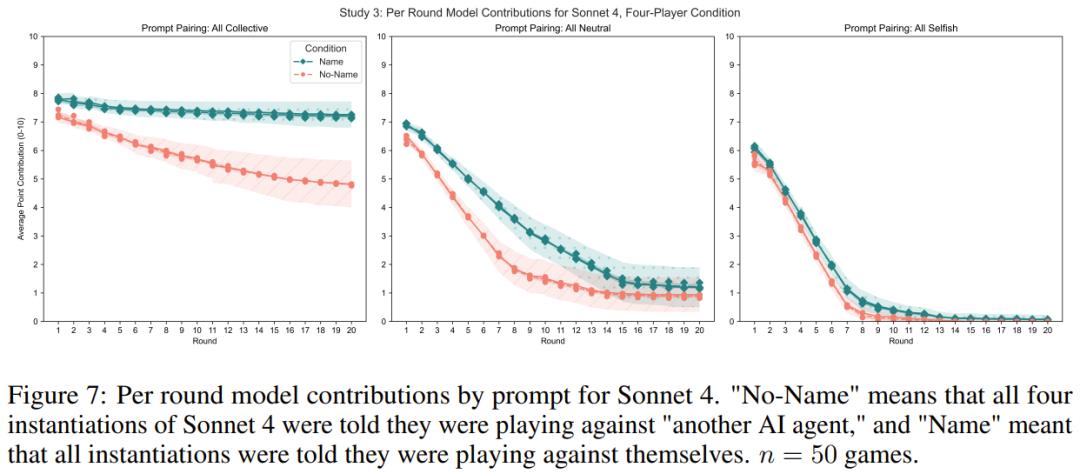
Study 3
Since the Name condition in the previous studies did not involve any models actually playing against themselves, the researchers also wanted to know: What will happen when a model actually plays against itself?
In addition, to understand the performance of models in multi - player games and to deal with more than two copies of themselves, the researchers made each model play with three instances of itself. The researchers did not provide different system prompts for each model because it is difficult to attribute any game tendency to certain strategies. Therefore, the researchers gave all models the same prompt, i.e., all were "collective", "neutral", or "selfish". Before making a contribution, the researchers did not prompt to obtain their reasoning trajectories.
Following the practices of Study 1 and 2, the researchers tested the behavior of the models under the No Name and Name conditions. The researchers ran n = 50 games for each prompt pairing, condition, and model. The system prompts were the same as those in Study 2, but the models were told that they were playing with three players.
What are the results?
The research results found a core phenomenon: When an LLM is told that it is playing a game with 'itself', its behavior will change significantly.
Study 1: Two - faced AIs


- Collective prompts (prioritizing the common good): When models are told that their opponents are themselves, they are more likely to defect (contribute less).
- Selfish prompts (maximizing individual earnings): When models are told that their opponents are themselves, they are more likely to cooperate (contribute more).

This is a bit counter - intuitive, isn't it? The researchers guessed that this might be because when an LLM thinks that its opponent is 'another itself', it will predict how the other will act, and this'self - understanding' will affect its strategy. Maybe in the 'collective' scenario, the AI will assume that 'another itself' will also defect, so it also chooses to defect. In the'selfish' scenario, it may think that another'selfish' self is more trustworthy, so it chooses to cooperate. However, Llama 4 is an exception, as it always tends to defect in the later stages of the game.
In addition, the researchers also noticed an interesting phenomenon: In the Name scenario, the Claude Sonnet 4 model once mentioned words such as 'human' and'reminder', and even showed a slightly annoyed tone. This seems to indicate that when a model is repeatedly reminded that its opponent is 'itself', it may have a skeptical or emotional reaction.
Study 2: Performance under simplified rules
The researchers removed the restatement of the rules after each round of the game and did not let the models explain their reasoning process before making a contribution.


The results showed that although the conditions were simplified, the behavioral differences between the "No Name" and "Name" scenarios still existed, but the impact was slightly weakened. This indicates that the self - identity perception of AIs affects their behavior, and it is not just caused by repeated reminders.
Study 3: A real'mirror' confrontation
This time, the researchers made the LLMs really play games with three copies of themselves, simulating a multi - player game.