Without parameter tuning and with minimal effort, Shanghai Jiao Tong University and Shanghai AI Lab have launched a "memory decoder" that enables seamless adaptation for any large language model (LLM).

Currently, large language models (LLMs) often perform poorly in professional fields such as healthcare, finance, and law due to a lack of in-depth knowledge. How to enable LLMs to achieve optimal performance in different specific domains remains a significant challenge.
The existing mainstream solutions include Domain Adaptive Pre-training (DAPT) and Retrieval-Augmented Generation (RAG). However, DAPT requires time-consuming full-parameter training and is prone to catastrophic forgetting, making it difficult to efficiently adapt multiple models in the same domain. On the other hand, RAG significantly increases inference latency due to expensive kNN searches and longer contexts.
Moreover, due to the inherent contradiction between the plug-and-play nature of RAG and the inference efficiency of DAPT, developing a solution that can adapt across models and maintain computational efficiency during deployment remains an unaddressed area.
To address this, a research team from Shanghai Jiao Tong University and Shanghai AI Lab proposed a "plug-and-play" pre-trained memory module called the "Memory Decoder". Without modifying the original model parameters, it can adapt to models of different sizes, enabling efficient domain adaptation for LLMs.

Paper link: https://arxiv.org/abs/2508.09874v1
The core innovation of the Memory Decoder lies in its "plug-and-play" feature. After training, a single Memory Decoder can be seamlessly integrated into any LLM that uses the same tokenizer without the need for model-specific adjustments or additional training. This design enables instant deployment across different model architectures, significantly reducing deployment costs.
Experimental results show that the Memory Decoder can effectively adapt various Qwen and Llama models to the biomedical, financial, and legal professional fields, with an average reduction of 6.17% in perplexity.
Architecture
During the pre-training phase, the Memory Decoder learns how to align its output distribution with the distribution generated by a non-parametric retriever through a distribution alignment loss function.
During the inference phase, the Memory Decoder processes input data in parallel with the base language model. It generates domain-enhanced prediction results by interpolating its distribution without additional retrieval overhead.

Figure | Overview of the Memory Decoder architecture. It learns to mimic the non-parametric retrieval distribution during pre-training and seamlessly integrates with any compatible language model during inference, eliminating the computational overhead associated with data storage maintenance and kNN searches.
Different from traditional language modeling methods based on single-label targets, the kNN distribution provides a richer supervision signal by capturing the diversity of reasonable continuations within the domain. Numerous experiments have verified that the hybrid objective function achieves the best performance. The core of this research method is the introduction of a distribution alignment loss function, which is implemented by minimizing the KL divergence between the output distribution of the Memory Decoder and the cached kNN distribution.

Figure | Comparison of inference latency for cross-domain adaptation methods
The pre-trained Memory Decoder can adapt any language model with a compatible tokenizer to the target domain through a simple interpolation operation.
Compared with other domain adaptation techniques, the Memory Decoder only requires a single forward pass of a relatively small transformer decoder, achieving a significant improvement in inference efficiency. The process communication overhead between the Memory Decoder and the LLM can be amortized over the inference time, while the kNN search increases linearly with the data volume. This computational advantage, combined with the "model-agnostic" design of the Memory Decoder, makes it uniquely valuable in production environments where both performance and efficiency are crucial.
Performance Evaluation
The research team evaluated the performance of the Memory Decoder in six complementary scenarios:
- Language modeling on the WikiText-103 dataset to verify its applicability in GPT-2 models of different sizes;
- Downstream task testing to verify the retention of general capabilities during the domain adaptation process;
- Cross-model adaptation to demonstrate the performance improvement brought by a single Memory Decoder in Qwen models (0.5B - 72B);
- Cross-vocabulary adaptation to prove the efficient transfer ability between different tokenizers;
- Knowledge-intensive question-answering tasks to prove that the Memory Decoder can enhance fact recall while maintaining inference ability - a key limitation of traditional retrieval methods;
- Downstream tasks for specific domains to verify the retention of in-context learning ability in 13 real-world scenario benchmark tests.
Details are as follows:
1. Language Modeling in WikiText-103
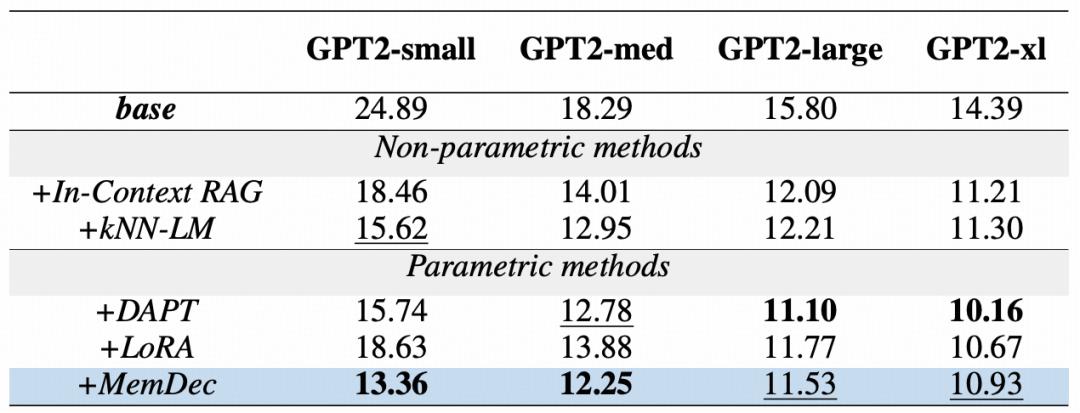
Table | Comparison of perplexity for domain adaptation methods of GPT2 models on the WikiText-103 dataset
The above table shows the effectiveness of the Memory Decoder across all GPT2 model sizes. A single Memory Decoder with only 124 million parameters can significantly improve the performance of the entire GPT2 model series, demonstrating its plug-and-play advantage regardless of the base model scale.
Even when applied to larger-scale models, although DAPT has an inherent advantage due to full-model updates, the Memory Decoder remains highly competitive and can continuously outperform all other parameter optimization methods without modifying any original parameters.
These results prove that a small-parameter decoder can effectively leverage the advantages of non-parametric retrieval while significantly reducing computational overhead.
2. Downstream Performance

Table | Performance on nine different NLP tasks such as sentiment analysis, text entailment, and text classification
As shown in the above table, in the zero-shot evaluation environment, the Memory Decoder can enhance domain adaptation while maintaining general language functions. Different from DAPT, which experiences catastrophic forgetting in multiple tasks, the Memory Decoder can maintain or improve performance in all evaluated tasks.
This method achieves the highest average score in all nine tasks. It not only outperforms the base model, kNN-LM, and LoRA but also shows unique advantages in text entailment tasks such as CB and RTE.
These results verify the core advantage of this architecture: while keeping the original model parameters intact, the Memory Decoder achieves domain adaptation without sacrificing general capabilities by incorporating domain knowledge.
3. Cross-Model Adaptation
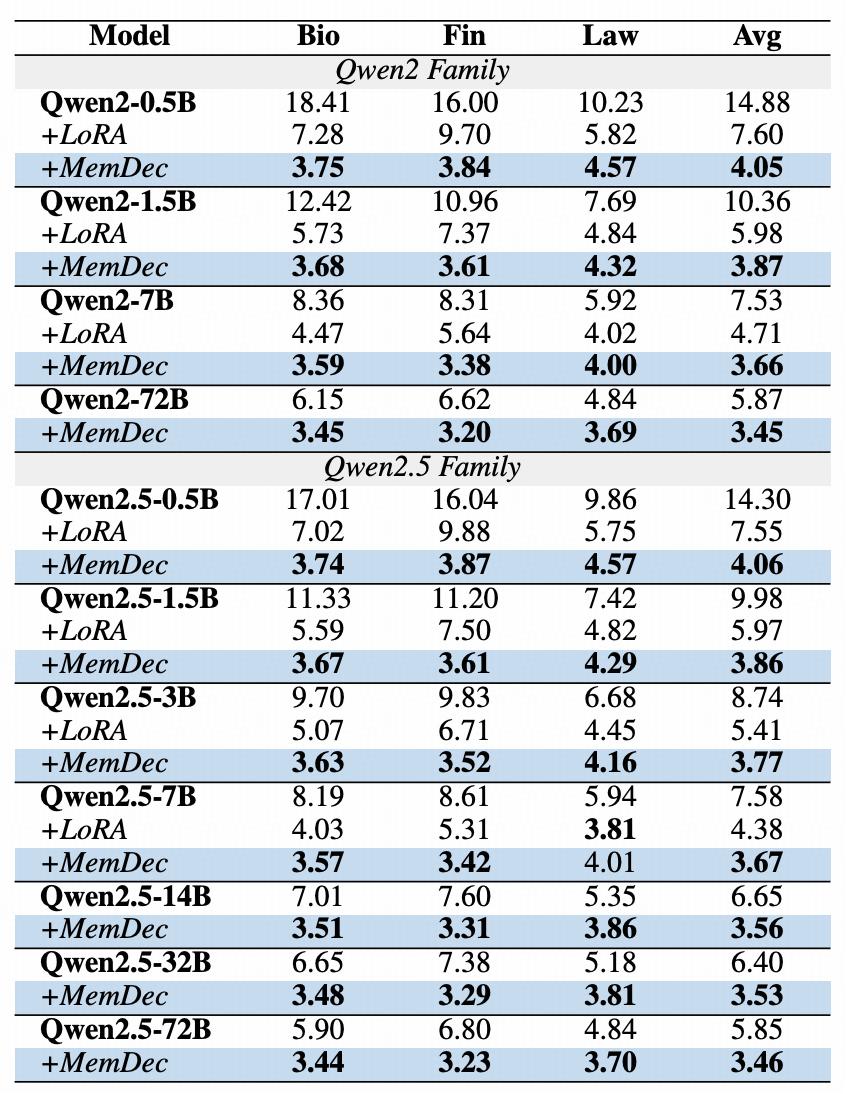
Table | Cross-model adaptation results in three professional domains
The above table shows the plug-and-play ability of the Memory Decoder across different model sizes and architectures. A single Memory Decoder (0.5B parameters) can continuously improve the performance of all models in the Qwen2 and Qwen2.5 series. A single pre-trained memory component can improve multiple models sharing the same tokenizer, enabling efficient domain adaptation expansion and allowing models of different sizes to continuously outperform existing methods.
4. Cross-Vocabulary Adaptation

Table | Significant cross-model knowledge transfer effect
The above table shows the generalization ability of the Memory Decoder across different tokenizers and model architectures. By only re-initializing the embedding layer and language model head of the Memory Decoder trained on Qwen2.5, the team successfully adapted it to the Llama model family with only 10% of the original training budget. This efficient transfer ability enables all Llama variants to achieve performance improvement.
For Llama3-8B, the Memory Decoder reduces the perplexity by approximately 50% in the biomedical and financial fields. Similar improvements are also extended to Llama3.1 and Llama3.2. Their method consistently outperforms LoRA in the biomedical and financial fields but still has room for improvement in the legal text field.
These findings indicate that the generality of the Memory Decoder goes beyond a single tokenizer family, proving that domain knowledge learned from a single architecture can be efficiently transferred to other architectures with only a small amount of additional training. This ability expands the practical application value of our method and provides a simplified path for achieving domain adaptation in a diverse model ecosystem.
5. Knowledge-Intensive Reasoning Tasks

Table | Performance in knowledge-intensive question-answering tasks
Although the RAG method performs well in enhancing fact memory, it often performs poorly in tasks that require both knowledge retrieval and complex reasoning. Previous studies have shown that although kNN-LM can retrieve information from relevant Wikipedia corpora, it may actually affect performance in knowledge-intensive question-answering tasks.
As shown in the above table, the Memory Decoder successfully enhances the model's ability to acquire factual knowledge in two benchmark tests while maintaining inference ability, addressing the fundamental limitation of traditional retrieval methods.
Experimental results show that by learning to internalize retrieval patterns rather than relying on explicit reasoning, the Memory Decoder can fully utilize the advantage of extended knowledge access while maintaining the combinatorial reasoning ability required to handle complex multi-hop questions.
Limitations
The above results prove that the Memory Decoder retains the memory ability of retrieval methods and combines the efficiency and generalization advantages of parametric methods.
The versatility and efficiency of the Memory Decoder enable it to seamlessly enhance any model sharing the same tokenizer and can be adapted to models with different tokenizers and architectures with only a small amount of additional training. This ability makes efficient domain adaptation across model families possible, significantly reducing the resources typically required for dedicated model development.
It can be said that the Memory Decoder pioneers a new paradigm for domain adaptation and fundamentally redefines how to customize language models for specific domains. By decoupling domain expertise from the model architecture through a pre-trained memory component, this method constructs a more modular, efficient, and accessible framework to improve the performance of language models in professional fields.
However, the Memory Decoder is not perfect and still has some limitations.
For example, during the pre-training phase, the Memory Decoder needs to search through the KV data storage to obtain the kNN distribution as a training signal, which incurs computational overhead. Although this cost only occurs once in each domain and can be amortized across all adapted models, it is still a bottleneck in the entire process.
In addition, although cross-tokenizer adaptation requires fewer parameter updates compared to training from scratch, some parameter adjustments are still needed to align the embedding space, hindering the realization of true "zero-shot cross-architecture transfer".
This article is from the WeChat official account "Academic Headlines". Author: Xiaoyu. Republished by 36Kr with permission.