Ohne Parameteranpassung und mit wenig Aufwand hat die Shanghai Jiao Tong Universität und das Shanghai KI-Labor ein "Gedächtnisdekoder" vorgestellt, der jeder Large Language Model (LLM) nahtlos anpassen kann.

Derzeit zeigen große Sprachmodelle (LLM) in Fachbereichen wie Medizin, Finanzwesen und Recht häufig schlechte Leistungen, da ihnen tiefergehende Fachkenntnisse fehlen. Es bleibt eine große Herausforderung, wie man LLM in verschiedenen spezifischen Bereichen optimal einsetzen kann.
Die gängigen Lösungsansätze umfassen bereichsadaptive Vortraining (DAPT) und abrufgestützte Generierung (RAG). Allerdings erfordert DAPT zeitaufwändiges Training aller Parameter und birgt die Gefahr von katastrophischem Vergessen, was es schwierig macht, mehrere Modelle effizient in demselben Bereich anzupassen. RAG erhöht zudem die Inferenzverzögerung erheblich aufgrund des teuren kNN-Suchverfahrens und längerer Kontexte.
Außerdem besteht ein inhärenter Widerspruch zwischen der Plug-and-Play-Eigenschaft von RAG und der Inferenzeffizienz von DAPT. Die Entwicklung einer Lösung, die sowohl auf verschiedene Modelle anwendbar ist als auch bei der Implementierung rechenleistungseffizient bleibt, ist noch ein weites Feld der Forschung.
Deshalb hat ein Forschungsteam der Shanghai Jiao Tong Universität und des Shanghai AI Lab ein "Plug-and-Play"-Vortrainingsgedächtnis-Modul vorgeschlagen - den "Memory Decoder". Ohne die Parameter des ursprünglichen Modells ändern zu müssen, kann es auf Modelle verschiedener Größen angepasst werden und ermöglicht so eine effiziente Bereichsadaptation von LLM.

Link zur Publikation: https://arxiv.org/abs/2508.09874v1
Das Kerninnovation des Memory Decoders liegt in seiner "Plug-and-Play"-Eigenschaft. Nach dem Training kann ein einzelner Memory Decoder nahtlos in jedes LLM integriert werden, das denselben Tokenizer verwendet, ohne dass es spezifischer Anpassungen oder zusätzlichen Trainings bedarf. Diese Konzeption ermöglicht eine sofortige Implementierung über verschiedene Modellarchitekturen hinweg und senkt die Implementierungskosten erheblich.
Experimentelle Ergebnisse zeigen, dass der Memory Decoder verschiedene Qwen- und Llama-Modelle effektiv auf biomedizinische, finanzielle und rechtliche Fachbereiche anpassen kann, wobei die Perplexität im Durchschnitt um 6,17 % sinkt.
Architektur
Während des Vortrainings lernt der Memory Decoder mithilfe einer Verteilungsausrichtungsverlustfunktion, seine Ausgabeverteilung mit der vom nicht-parametrischen Retriever erzeugten Verteilung auszurichten.
Während der Inferenz verarbeitet der Memory Decoder die Eingabedaten parallel zum Basissprachmodell. Durch Interpolation seiner Verteilung erzeugt er bereichsgestärkte Vorhersagen, ohne zusätzliche Abrufkosten zu verursachen.

Abbildung | Überblick über die Memory Decoder-Architektur. Während des Vortrainings lernt es, die nicht-parametrische Abrufverteilung zu imitieren. Während der Inferenz integriert es sich nahtlos in jedes kompatible Sprachmodell, wodurch die Rechenkosten für Datenspeicherung und kNN-Suche eliminiert werden.
Im Gegensatz zu herkömmlichen sprachmodellierenden Ansätzen, die auf einzelnen Labels basieren, bietet die kNN-Verteilung reichhaltigere Überwachungssignale, indem sie die Vielfalt von sinnvollen Fortsetzungen im Bereich erfasst. Zahlreiche Experimente bestätigen, dass die gemischte Zielfunktion die besten Ergebnisse liefert. Der Kern dieses Forschungsansatzes besteht in der Einführung einer Verteilungsausrichtungsverlustfunktion, die durch Minimierung der KL-Divergenz zwischen der Ausgabeverteilung des Memory Decoders und der zwischengespeicherten kNN-Verteilung implementiert wird.

Abbildung | Vergleich der Inferenzverzögerungen von bereichsadaptiven Methoden
Der vortrainierte Memory Decoder kann durch einfache Interpolation jedes Sprachmodell mit einem kompatiblen Tokenizer auf den Zielbereich anpassen.
Im Vergleich zu anderen bereichsadaptiven Techniken erfordert der Memory Decoder nur eine einzige Vorwärtsauswertung eines relativ kleinen Transformer-Decoders, was eine deutliche Verbesserung der Inferenzeffizienz bedeutet. Die Kommunikationskosten zwischen Memory Decoder und LLM können durch längere Inferenzzeiten verteilt werden, während die kNN-Suche linear mit der Datenmenge ansteigt. Diese Rechenleistungsvorteile in Kombination mit der "modellunabhängigen" Gestaltung des Memory Decoders machen es zu einem wertvollen Werkzeug in Produktionsumgebungen, in denen sowohl Leistung als auch Effizienz von entscheidender Bedeutung sind.
Leistungsbewertung
Das Forschungsteam hat die Leistung des Memory Decoders in sechs komplementären Szenarien bewertet:
- Sprachmodellierung auf dem WikiText-103-Datensatz, um seine Anwendbarkeit in GPT-2-Modellen verschiedener Größen zu überprüfen;
- Tests von Downstream-Aufgaben, um zu überprüfen, ob die allgemeinen Fähigkeiten während des Bereichsadaptionsprozesses erhalten bleiben;
- Quer-Modell-Adaptation, um die Leistungssteigerung zu zeigen, die ein einzelner Memory Decoder in Qwen-Modellen (0,5B - 72B) bringt;
- Quer-Vokabular-Adaptation, um die effiziente Übertragungsfähigkeit zwischen verschiedenen Tokenizern zu beweisen;
- wissensintensive Fragestellungen, um zu beweisen, dass der Memory Decoder die Inferenzfähigkeit erhält und gleichzeitig die Tatsachenerinnerung verbessern kann - ein wesentlicher Nachteil herkömmlicher Abrufmethoden;
- Downstream-Aufgaben für spezifische Bereiche, um die Aufrechterhaltung der Kontextlernfähigkeit in 13 echten Szenarien zu überprüfen.
Im Einzelnen:
1. Sprachmodellierung in WikiText-103
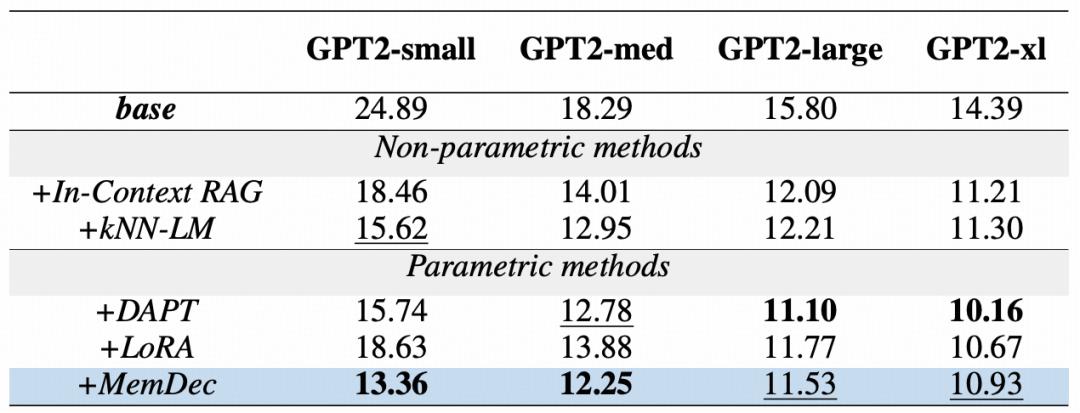
Tabelle | Vergleich der Perplexität von Bereichsadaptionsmethoden für GPT2-Modelle auf dem WikiText-103-Datensatz
Die obige Tabelle zeigt die Effektivität des Memory Decoders für alle GPT2-Modellgrößen. Ein einzelner Memory Decoder mit nur 124 Millionen Parametern kann die Leistung der gesamten GPT2-Modellreihe erheblich verbessern, was die Vorteile seiner Plug-and-Play-Eigenschaft unterstreicht - unabhängig von der Größe des Basismodells.
Selbst wenn es auf größere Modelle angewendet wird, bleibt der Memory Decoder trotz des inhärenten Vorteils von DAPT, das alle Modellparameter aktualisiert, wettbewerbsfähig und übertrifft kontinuierlich alle anderen Parameteroptimierungsmethoden, ohne dass die ursprünglichen Parameter geändert werden müssen.
Diese Ergebnisse bestätigen, dass ein Decoder mit wenigen Parametern die Vorteile des nicht-parametrischen Abrufs nutzen kann und gleichzeitig die Rechenkosten erheblich reduziert.
2. Leistung in Downstream-Aufgaben

Tabelle | Leistung in neun verschiedenen NLP-Aufgaben wie Sentimentanalyse, Textentailment und Textklassifikation
Wie die obige Tabelle zeigt, kann der Memory Decoder in einer Null-Shot-Evaluierung die Bereichsadaptation verbessern und gleichzeitig die allgemeinen Sprachfähigkeiten erhalten. Im Gegensatz zu DAPT, das in mehreren Aufgaben katastrophisches Vergessen zeigt, kann der Memory Decoder in allen evaluierten Aufgaben die Leistung beibehalten oder verbessern.
Dieser Ansatz erzielt in allen neun Aufgaben die höchsten Durchschnittswerte. Er übertrifft nicht nur das Basismodell, kNN-LM und LoRA, sondern zeigt auch besondere Vorteile in Textentailment-Aufgaben wie CB und RTE.
Diese Ergebnisse bestätigen die Kernvorteile dieser Architektur: Der Memory Decoder ermöglicht eine Bereichsadaptation ohne Einbußen an allgemeinen Fähigkeiten, indem er Fachwissen integriert, ohne die ursprünglichen Modellparameter zu ändern.
3. Quer-Modell-Adaptation
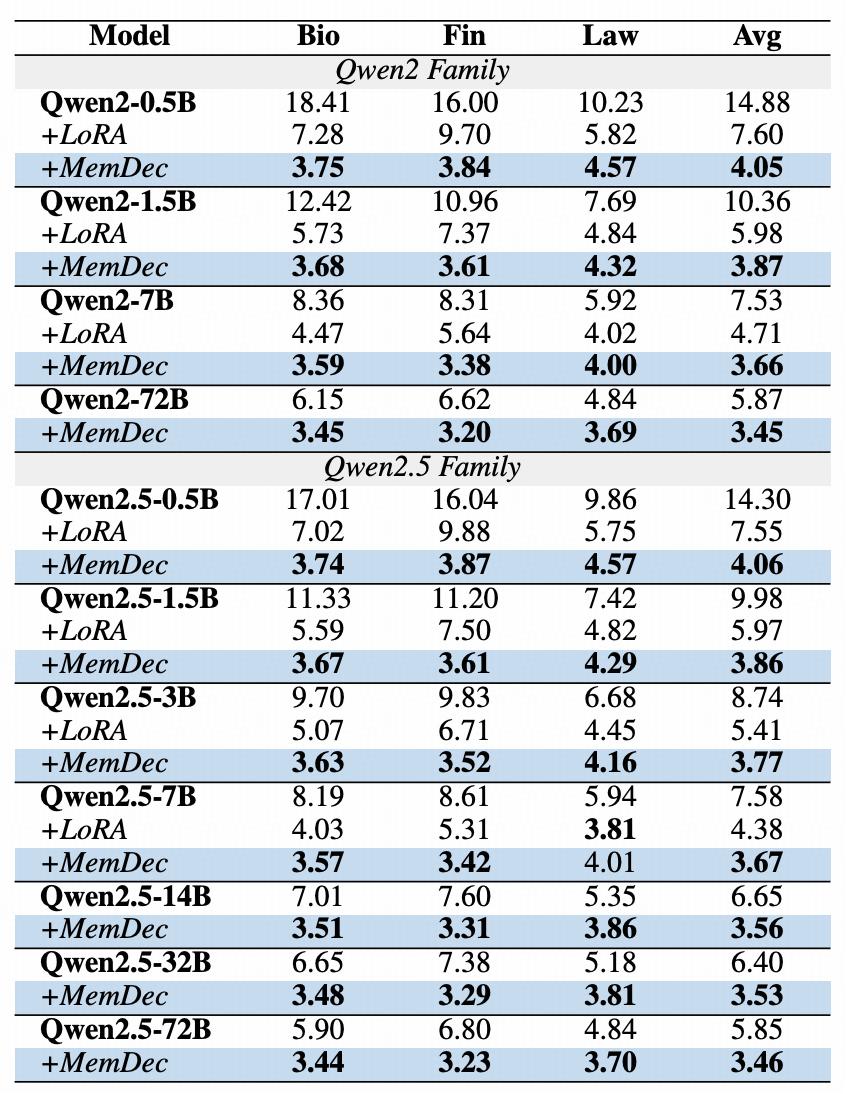
Tabelle | Ergebnisse der Quer-Modell-Adaptation in drei Fachbereichen
Die obige Tabelle zeigt die Plug-and-Play-Fähigkeit des Memory Decoders für Modelle verschiedener Größen und Architekturen. Ein einzelner Memory Decoder (0,5B Parameter) kann die Leistung aller Modelle in der Qwen2- und Qwen2.5-Reihe kontinuierlich verbessern. Ein einzelnes vortrainiertes Gedächtnisbauteil kann mehrere Modelle, die denselben Tokenizer teilen, verbessern und ermöglicht so eine effiziente Erweiterung der Bereichsadaptation. Dadurch können Modelle verschiedener Größen kontinuierlich die bestehenden Methoden übertreffen.
4. Quer-Vokabular-Adaptation

Tabelle | Signifikante Übertragung von Wissen zwischen Modellen
Die obige Tabelle zeigt die Generalisierungsfähigkeit des Memory Decoders für verschiedene Tokenizer und Modellarchitekturen. Indem das Team nur die Einbettungsschicht und den Sprachmodellkopf des auf Qwen2.5 trainierten Memory Decoders neu initialisiert hat, konnte es ihn erfolgreich auf die Llama-Modellfamilie anpassen, und zwar mit nur 10 % des ursprünglichen Trainingsbudgets. Diese effiziente Übertragungsfähigkeit hat zu einer Leistungssteigerung in allen Llama-Varianten geführt.
Für Llama3-8B hat der Memory Decoder die Perplexität in den biomedizinischen und finanziellen Bereichen um etwa 50 % gesenkt. Ähnliche Verbesserungen wurden auch in Llama3.1 und Llama3.2 erzielt. Die Methode übertrifft LoRA in den biomedizinischen und finanziellen Bereichen, aber es besteht noch Verbesserungspotenzial im Bereich rechtlicher Texte.
Diese Erkenntnisse zeigen, dass die Universalität des Memory Decoders über eine einzelne Tokenizer-Familie hinausgeht. Sie beweisen, dass Fachwissen, das aus einer einzigen Architektur gelernt wurde, effizient auf andere Architekturen übertragen werden kann, und zwar mit nur wenig zusätzlichem Training. Diese Fähigkeit erweitert den praktischen Nutzen unserer Methode und bietet einen vereinfachten Weg zur Bereichsadaptation in einem vielfältigen Modellökosystem.
5. Wissensintensive Inferenzaufgaben

Tabelle | Leistung in wissensintensiven Fragestellungen
Obwohl die RAG-Methode bei der Verbesserung des Faktengedächtnisses gut abschneidet, zeigt sie in Aufgaben, die sowohl Wissensabruf als auch komplexe Inferenz erfordern, oft schlechte Ergebnisse. Frühere Studien haben gezeigt, dass kNN-LM, obwohl es Informationen aus dem relevanten Wikipedia-Corpus abrufen kann, die Leistung in wissensintensiven Fragestellungen möglicherweise beeinträchtigen kann.
Wie die obige Tabelle zeigt, hat der Memory Decoder in zwei Benchmark-Tests die Fähigkeit des Modells, faktisches Wissen zu erlangen, verbessert und gleichzeitig die Inferenzfähigkeit beibehalten. Dadurch werden die grundlegenden Grenzen herkömmlicher Abrufmethoden überwunden.
Die experimentellen Ergebnisse zeigen, dass der Memory Decoder die kombinatorische Inferenzfähigkeit, die für die Bearbeitung komplexer Mehr-Hop-Fragen erforderlich ist, beibehält und gleichzeitig die