ByteDance suddenly open-sourced Seed-OSS. Its 512K context length is four times that of the mainstream, and its inference ability has set a new record.
ByteDance unexpectedly open-sourced a large model, debuting with Seed-OSS-36B, which has 36 billion parameters.

The naming convention of Seed-OSS clearly echoes the GPT-OSS series previously released by OpenAI.
Similar to OpenAI's open-source strategy, ByteDance didn't directly open-source its core commercial model, Doubao. Instead, it created a version specifically for the open-source community based on its internal technology.
The Seed team at ByteDance officially released this series of models on Hugging Face and GitHub, adopting the Apache-2.0 open-source license, which allows for free use in academic research and commercial deployment.
512K Context Window and Flexible Control of Thinking Budget
The most eye-catching feature of Seed-OSS is its native 512K ultra-long context.
Currently, the context window of mainstream open-source models, such as DeepSeek V3.1, is 128K, while Seed-OSS quadruples that.
Moreover, this 512K context was built during the pre-training phase, not artificially extended through methods like interpolation later.
This means that Seed-OSS can easily handle professional scenarios that require processing large amounts of information, such as legal document review, long report analysis, and understanding complex codebases.
In addition, Seed-OSS introduced the "Thinking Budget" mechanism.
By setting a token limit, you can control the depth of the model's thinking. For example, if you set a budget of 512 tokens, the model will work like this during the inference process: Copy
Okay, let me solve this problem step by step. The problem states... I've used 129 tokens and have 383 tokens left. Using the power rule, we can... I've used 258 tokens and have 254 tokens left. Additionally, remember... I've exhausted the token budget and will now give the answer.
For simple tasks, you can set a smaller budget to make the model respond quickly. For complex mathematical reasoning or code generation, you can allocate a larger budget to allow it to think more thoroughly.

ByteDance recommends using integer multiples of 512 (such as 512, 1K, 2K, 4K, 8K, or 16K) because the model has been extensively trained in these intervals.
In terms of the model architecture, Seed-OSS adopts a mature and stable design:
It is a dense model with 36 billion parameters (not a MoE model), using RoPE positional encoding, GQA attention mechanism, RMSNorm normalization, and the SwiGLU activation function. The entire model has 64 layers, a hidden layer dimension of 5120, and a vocabulary size of 155K.

Considering that synthetic instruction data may affect post-training research, the ByteDance Seed team provides two versions of the base model: one includes synthetic instruction data (with stronger performance), and the other does not (purer), offering more options for the research community.
Open-Source SOTA in Multiple Benchmark Tests
So, how does this model perform in practice?
In terms of knowledge understanding, Seed-OSS-36B-Base scored 65.1 on MMLU-Pro, surpassing the 58.5 of Qwen2.5-32B-Base of the same scale. It also achieved a high score of 82.1 on TriviaQA.
It scored 87.7 on the BBH benchmark test for reasoning ability, refreshing the record for open-source models. In terms of mathematical ability, it scored 90.8 on GSM8K and 81.7 on MATH.
Seed-OSS also has excellent code capabilities, scoring 76.8 on HumanEval and 80.6 on MBPP.

The instruction-tuned version, Seed-OSS-36B-Instruct, scored 91.7 on the AIME24 math competition questions, second only to OpenAI's OSS-20B.
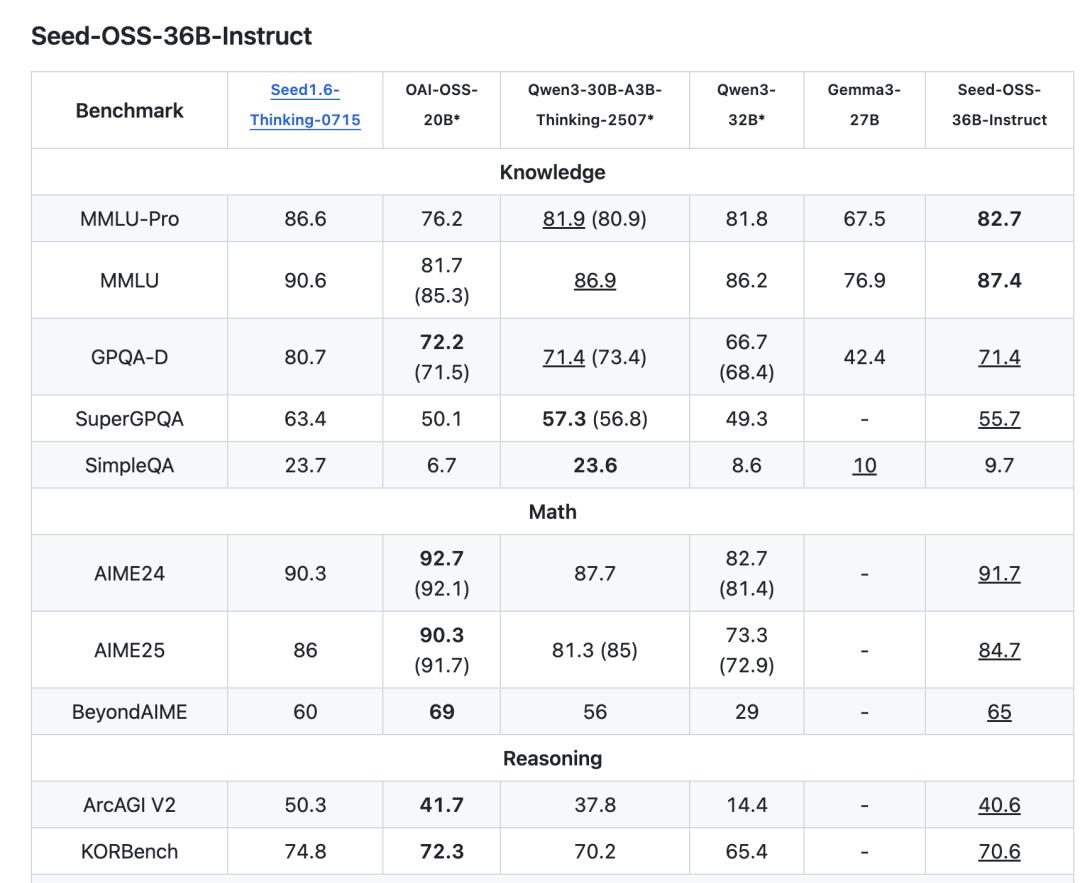
Moreover, these results were achieved with only 12T tokens of training data. In contrast, many models of the same scale were trained with over 15T of data.
ByteDance Seed Team's Open-Source Landscape
The ByteDance Seed team was established in 2023, aiming to "build the most advanced AI foundation models in the industry." Its research directions cover multiple cutting-edge fields, including large language models, multi-modalities, and AI infrastructure.
Over the past year or so, the team has successively open-sourced several influential projects, although most were models in niche areas rather than the more attention-grabbing base language models.
In May this year, they released Seed-Coder, an 8B-scale code generation model. Its biggest innovation is allowing the LLM to manage and filter training data by itself, significantly improving code generation capabilities.
Subsequently, they launched BAGEL, a unified multi-modal model that can handle text, images, and videos simultaneously, truly achieving "anything can be input and output."
Even earlier, they released Seed Diffusion, an experimental language model based on discrete state diffusion technology that achieves extremely high inference speeds in code generation tasks.
To support the training of these models, the team also open-sourced VeOmni, a PyTorch-native full-modal distributed training framework.
Recently, they also developed Seed LiveInterpret, an end-to-end simultaneous interpretation model that not only has high translation accuracy and low latency but can also replicate the speaker's voice characteristics.
With the open-source release of Seed-OSS, the domestic open-source base model family has gained another powerful member.
GitHub:
https://github.com/ByteDance-Seed/seed-oss
HuggingFace:
https://huggingface.co/collections/ByteDance-Seed/seed-oss-68a609f4201e788db05b5dcd
This article is from the WeChat official account "QbitAI". Author: Meng Chen. Republished by 36Kr with permission.