ByteDance hat plötzlich Seed-OSS als Open-Source-Projekt freigegeben. Der 512K-Kontext übertrifft die Länge der gängigen Lösungen um das Vierfache, und die Inferenzfähigkeit setzt neue Rekorde.
ByteDance hat plötzlich ein großes Open-Source-Modell vorgestellt, und es ist das Seed-OSS-36B mit beeindruckenden 36 Milliarden Parametern.

Die Benennung des Seed-OSS-Modells bezieht sich offensichtlich auf die GPT-OSS-Serie, die zuvor von OpenAI veröffentlicht wurde.
Ähnlich wie OpenAI hat ByteDance nicht direkt das kommerzielle Kernmodell Doubao Open-Source gemacht, sondern ein spezielles Modell für die Open-Source-Community basierend auf internen Technologien entwickelt.
Das Seed-Team von ByteDance hat diese Modellserie offiziell auf Hugging Face und GitHub veröffentlicht. Es folgt der Apache-2.0 Open-Source-Lizenz und kann kostenlos für akademische Forschung und kommerzielle Implementierungen genutzt werden.
512K Kontextfenster und flexible Steuerung des Denkbudgets
Die beeindruckendste Eigenschaft des Seed-OSS ist sicherlich das native 512K lange Kontextfenster.
Die derzeit gängigen Open-Source-Modelle wie DeepSeek V3.1 haben ein Kontextfenster von 128K, während das Seed-OSS-Fenster viermal so groß ist.
Darüber hinaus wurde dieses 512K-Fenster bereits während der Vorhersagephase festgelegt und nicht später durch Interpolation oder andere Methoden aufgebauscht.
Das bedeutet, dass das Seed-OSS in professionellen Szenarien, die eine Verarbeitung von riesigen Datenmengen erfordern, wie die Prüfung von Rechtsdokumenten, die Analyse von langen Berichten oder das Verständnis komplexer Codebibliotheken, hervorragend abschneiden kann.
Zusätzlich hat das Seed-OSS einen „Denkbudget“ (Thinking Budget)-Mechanismus eingeführt.
Indem Sie eine bestimmte Anzahl von Tokens festlegen, können Sie die Tiefe der Denkprozesse des Modells steuern. Wenn Sie beispielsweise ein Budget von 512 Tokens festlegen, arbeitet das Modell während der Inferenz wie folgt: Kopieren
Okay, lassen Sie mich dieses Problem Schritt für Schritt lösen. Die Aufgabe besagt... Ich habe bereits 129 Tokens verwendet, es bleiben noch 383 Tokens. Mit der Potenzregel können wir... Ich habe bereits 258 Tokens verwendet, es bleiben noch 254 Tokens. Übrigens, denken Sie daran... Ich habe mein Token-Budget aufgebraucht und gebe jetzt die Antwort.
Für einfache Aufgaben können Sie ein kleineres Budget festlegen, damit das Modell schnell reagieren kann. Für komplexe mathematische Schlussfolgerungen oder Codegenerierung können Sie ein höheres Budget festlegen, damit das Modell gründlicher nachdenken kann.

ByteDance empfiehlt die Verwendung von Vielfachen von 512 (z. B. 512, 1K, 2K, 4K, 8K oder 16K), da das Modell in diesen Intervallen intensiv trainiert wurde.
Beim Modellaufbau hat das Seed-OSS ein bewährtes und stabiles Design gewählt:
Ein dichtes Modell mit 36 Milliarden Parametern (kein MoE), das RoPE-Positionskodierung, GQA-Attentionsmechanismus, RMSNorm-Normalisierung und die SwiGLU-Aktivierungsfunktion verwendet. Das gesamte Modell hat 64 Schichten, eine versteckte Schichtdimension von 5120 und eine Vokabulargröße von 155K.

Angesichts der Tatsache, dass synthetische Befehlsdaten die Nachfolgerecherche beeinflussen können, bietet das Byte-Seed-Team zwei Versionen des Basis-Modells an: eine mit synthetischen Befehlsdaten (leistungsstärker) und eine ohne (reiner), um der Forschungsgemeinschaft mehr Auswahlmöglichkeiten zu geben.
Mehrere Benchmark-Tests: Open-Source-SOTA
Wie performt das Modell in der Praxis?
Beim Verständnis von Wissen hat das Seed-OSS-36B-Base auf der MMLU-Pro 65,1 Punkte erreicht, was die 58,5 Punkte des gleichgroßen Qwen2.5-32B-Base übertrifft. Auf der TriviaQA hat es sogar 82,1 Punkte erzielt.
Im BBH-Benchmark-Test für Schlussfolgerungsfähigkeiten hat es 87,7 Punkte erreicht und damit den Rekord der Open-Source-Modelle aufgebrochen. Bei der mathematischen Fähigkeit hat es 90,8 Punkte auf der GSM8K und 81,7 Punkte auf der MATH erreicht.
Das Seed-OSS hat auch eine beeindruckende Codefähigkeit. Es hat 76,8 Punkte auf der HumanEval und 80,6 Punkte auf der MBPP erreicht.

Die instruktionsfeingestellte Version Seed-OSS-36B-Instruct hat bei den Aufgaben des AIME24-Mathematikwettbewerbs 91,7 Punkte erreicht, nur hinter dem OpenAI-OSS-20B.
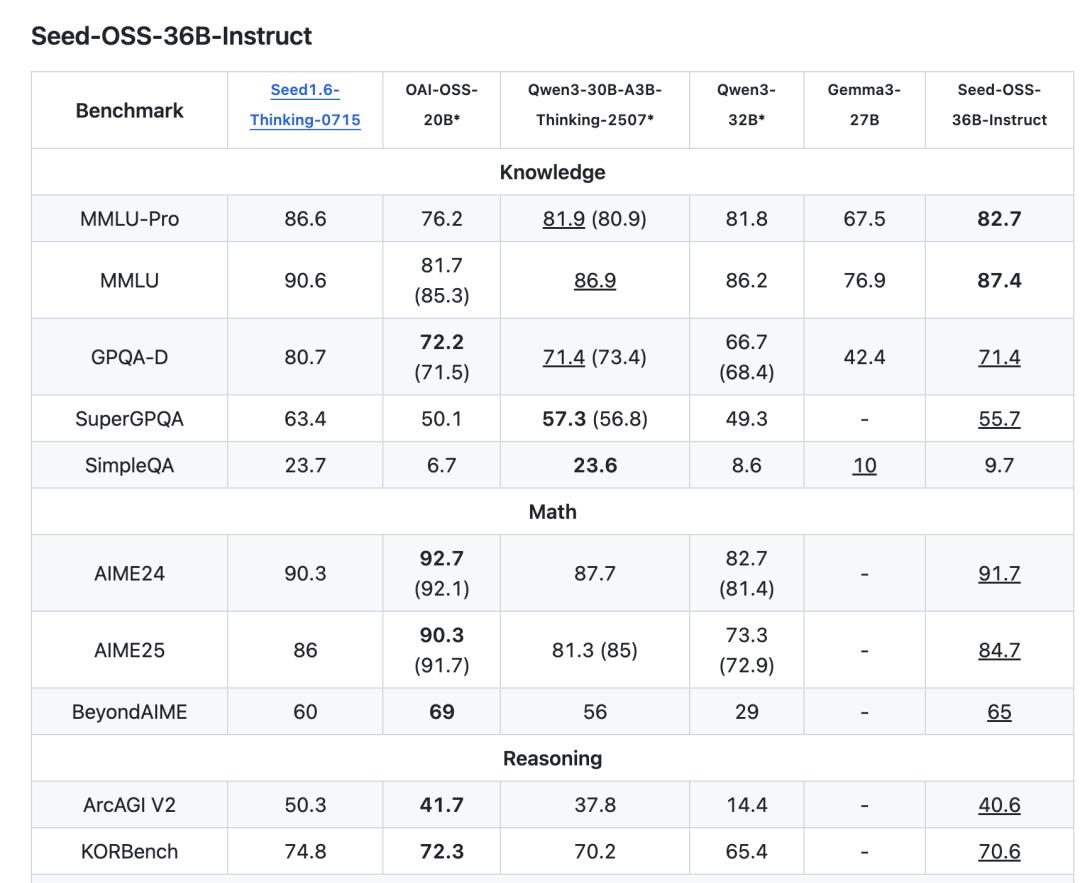
Und diese Ergebnisse wurden mit nur 12T Tokens erzielt. Im Vergleich dazu verwenden viele Modelle gleicher Größe über 15T Trainingsdaten.
Das Open-Source-Portfolio des Byte-Seed-Teams
Das Byte-Seed-Team wurde 2023 gegründet und hat sich das Ziel gesetzt, „die fortschrittlichsten künstlichen Intelligenz-Basis-Modelle der Branche zu entwickeln“. Seine Forschungsrichtungen umfassen verschiedene führende Bereiche wie große Sprachmodelle, Multimodalität und KI-Infrastruktur.
Im Laufe des letzten Jahres und mehr haben sie mehrere einflussreiche Projekte Open-Source gemacht, jedoch waren es meist Modelle für spezielle Bereiche und nicht die beachteten Basis-Sprachmodelle.
Im Mai dieses Jahres haben sie das Seed-Coder veröffentlicht, ein Codegenerierungsmodell mit 8B Parametern. Die größte Innovation besteht darin, dass das LLM die Trainingsdaten selbst verwaltet und filtert, was die Codegenerierungsfähigkeit erheblich verbessert.
Anschließend haben sie das BAGEL vorgestellt, ein einheitliches Multimodal-Modell, das gleichzeitig Text, Bilder und Videos verarbeiten kann und so tatsächlich „alles als Eingabe und Ausgabe“ ermöglicht.
Noch früher haben sie das Seed Diffusion veröffentlicht, ein experimentelles Sprachmodell basierend auf diskreten Zustandsdiffusionstechniken, das bei der Codegenerierung eine extrem hohe Inferenzgeschwindigkeit erreicht.
Um die Trainings dieser Modelle zu unterstützen, hat das Team auch das VeOmni Open-Source gemacht, ein PyTorch-natives, ganzheitliches Multimodal-Verteilungs-Trainingsframework.
Kürzlich haben sie auch ein Seed LiveInterpret end-to-end-Simultandübersetzungsmodell entwickelt, das nicht nur eine hohe Übersetzungsgenauigkeit und eine geringe Latenz aufweist, sondern auch die Stimmmerkmaler des Sprechers nachahmen kann.
Mit der Veröffentlichung des Seed-OSS ist ein weiteres starkes Mitglied in die Gruppe der chinesischen Open-Source-Basis-Modelle gekommen.
GitHub:
https://github.com/ByteDance-Seed/seed-oss
HuggingFace:
https://huggingface.co/collections/ByteDance-Seed/seed-oss-68a609f4201e788db05b5dcd
Dieser Artikel stammt aus dem WeChat-Account „Quantum Bit“, Autor: Meng Chen. 36Kr hat die Veröffentlichung mit Genehmigung vorgenommen.