In a nutshell, the performance soars by 49%. Works from the University of Maryland, MIT, etc.: Prompts are the ultimate weapon for large models.
Prompts are the hidden ace up AI's sleeve! Research from top institutions like the University of Maryland and MIT proves that half of the prompts are the key to a 49% surge in AI performance.
Improving AI performance depends half on the model and half on the prompts.

Recently, institutions including the University of Maryland, MIT, and Stanford jointly verified that model upgrades only contribute 50% to performance improvement. The other half comes from optimizing user prompts.
They call this "prompt adaptation."

Paper link: https://arxiv.org/pdf/2407.14333v5
To this end, they had DALL - E 2 and DALL - E 3 compete. 1,893 "contestants" tried to reproduce target images with one of three randomly assigned models in 10 attempts.
Surprisingly, DALL - E 3's image similarity was significantly better than DALL - E 2's.
Among them, the model upgrade itself only contributed 51% of the performance, and the remaining 49% was entirely due to the optimized prompts of the subjects.

The key is that people without a technical background can also use prompts to make the DALL - E 3 model generate better pictures.

Greg Brockman, the president of OpenAI, also believes that "to fully unleash the potential of the model, some special skills are indeed needed."
He suggests that developers manage "Prompt libraries" and continuously explore the boundaries of the model.

In other words, your prompt level determines whether AI can go from "bronze" to "king."
Don't wait for GPT - 6! It's better to "tune" your prompts
The effectiveness of GenAI depends not only on the technology itself but also on whether high - quality input instructions can be designed.
In 2023, after ChatGPT became popular, the world witnessed a boom in "prompt engineering."
Although the new "context engineering" has become a hot topic this year, "prompt engineering" is still very popular.

However, despite the consensus, prompt design as a dynamic practice still lacks in - depth research.
Most prompt libraries and tutorials treat effective prompts as "reusable finished products," but they may fail when used in new templates.
This brings some practical problems: Can prompt strategies be migrated across model versions? Or must they be continuously adjusted to adapt to changes in model behavior?
To this end, the research team proposed the measurable behavioral mechanism of "prompt adaptation" to explain how user input evolves with technological progress.
They conceptualize it as a "dynamic complementary ability" and believe that this ability is crucial for fully releasing the economic value of large models.
To evaluate the impact of prompt adaptation on model performance, the team used pre - registered online experimental data from the Prolific platform, inviting a total of 1,893 participants.
Each subject was randomly assigned one of three models with different performance levels: DALL - E 2, DALL - E 3, or DALL - E 3 with automatic prompt optimization.

In addition to model assignment, each participant was independently assigned one of 15 target images. These images were selected from three categories: commercial marketing, graphic design, and architectural photography.
The experiment clearly informed participants that the model had no memory function - each new prompt was processed independently, without inheriting information from previous attempts.
Each person needed to submit at least 10 prompts to reproduce the target image as closely as possible through the model. The best - performing participants would receive high - value bonuses.
After the task, participants were required to fill out a demographic survey covering age, gender, education level, occupation, and self - rated abilities in creative writing, programming, and generative AI.
Random assignment, 10 generations
The core outcome measure of the experiment was the similarity between each image generated by the participants and the specified target image.
This measure was quantified by the cosine similarity of CLIP embedding vectors.
Since the output of the generative model is random, the same prompt may produce different images in different attempts.
To control this variability, the researchers generated 10 images for each prompt and calculated their cosine similarities with the target image respectively. Then, they took the average of these 10 similarity scores as the expected quality score of the prompt.
Replay analysis: Is it the model or the prompt?
Another core goal of the experiment was to clarify how much of the improvement in image reproduction performance comes from a more powerful model and how much comes from prompt optimization.
According to the conceptual framework, when the model is upgraded from ability level θ1 to a higher level θ2, the total improvement in output quality can be expressed as:
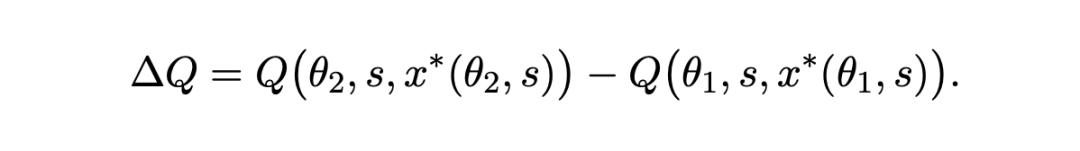
The researchers decomposed this change into two parts:
1. Model effect: The performance improvement obtained by applying the same prompt to a better model;
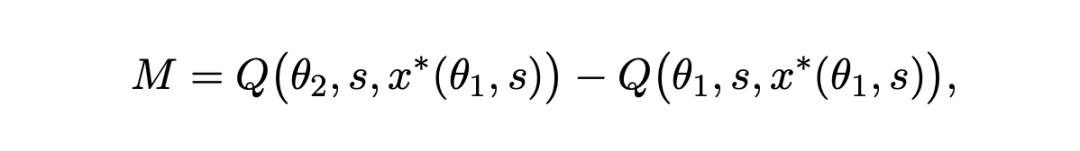
2. Prompt effect: The additional improvement brought about by adjusting the prompt to fully leverage the advantages of a more powerful model.
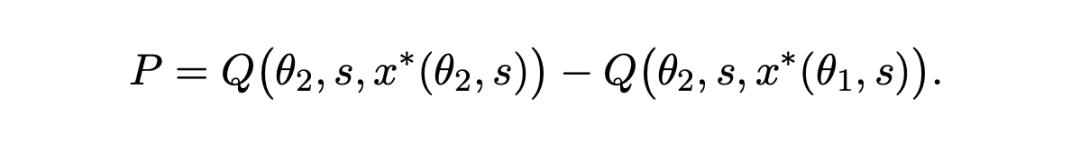
To empirically evaluate these two components, the researchers conducted additional analyses on the prompts of participants in the DALL - E 2 and DALL - E 3 (original version) experimental groups.
The specific method was to resubmit the original prompts submitted by the participants during the experiment to their originally assigned model and another model, and generate new images respectively.
· Isolate the model effect
For the prompts (x*(θ1,s)) written by DALL - E 2 participants, the team evaluated them on both the DALL - E 2 and DALL - E 3 models, obtaining the measured values of Q[θ1s,x*(θ1,s)] and Q[θ2,s,x*(θ_1,s)] respectively.
This comparison can isolate the model effect: that is, the improvement in output quality obtained only by upgrading the model with a fixed prompt.
· Compare the prompt effect
To evaluate the prompt effect, the authors also compared the following two sets of data:
1. The quality of DALL - E 2 prompts replayed on DALL - E 3 (i.e., the estimated value of Q[θ2,s,x*(θ1,s)])
2. The quality of prompts written by DALL - E 3 participants specifically for the model on the same model (i.e., the estimated value of Q[θ2,s,x*(θ2,s)])
This difference precisely reflects the additional improvement in the model itself when users adjust the prompts.
So, what are the specific results of this experiment?
Prompts unlock half of DALL - E 3's powerful image - generation ability
In the experiment, the research team mainly explored three questions:
(i) Does accessing a more powerful model (DALL - E 3) improve user performance;
(ii) How do users rewrite or optimize their prompts when using a more powerful model;
(iii) How much of the overall performance improvement should be attributed to model improvement and how much to the adaptive adjustment of prompts.
Model upgrade is the core
First, the team verified whether participants using DALL - E 3 performed better than those using DALL - E 2.
As shown in Figure 1 below, all the findings are summarized.
A shows three groups of representative target images, each group containing three images extracted from the two models.
The middle row shows the generated results with the cosine similarity to the target image closest to the average of all participants. The upper (lower) row shows images with a similarity to the target image about one average treatment effect (ATE) higher (lower) than the mean.
In 10 necessary prompt attempts, the cosine similarity between the images generated by participants using DALL - E 3 and the target images was on average 0.0164 higher.
This improvement is equivalent to 0.19 standard deviations, as shown in Figure 1 B below.
Moreover, this advantage persisted throughout the 10 attempts. Therefore, it is undeniable that model upgrades will definitely lead to significant performance improvements compared to previous generations.

Moreover, there were significant differences in the dynamic prompt behaviors of participants between the two models:
Figure C shows that the average prompt text of DALL - E 3 users was 24% longer than that of DALL - E 2 users, and this gap gradually widened with the number of attempts.
They were more likely to reuse or optimize previous prompts, indicating that after discovering that the model could handle complex instructions, they would adopt more exploratory strategies.
In addition, part - of - speech analysis confirmed that the increased vocabulary provided substantial descriptive information rather than redundant content:
The proportions of nouns and adjectives (the two most descriptive parts of speech) were basically the same between the two models (48% in the DALL - E 3 group vs. 49% in the DALL - E 2 group, p = 0.215).
This shows that the lengthening of the prompt text reflects the enrichment of semantic information rather than meaningless verbosity.
51% model, 49% prompt
The researchers observed differences in prompt behaviors, indicating that users would actively adapt to the capabilities of the assigned model.
How much of the overall performance improvement of DALL - E 3 users comes from the enhanced technical capabilities of the model, and how much is due to users rewriting prompts according to these capabilities?
To answer this question, the researchers used the replay analysis method described above to empirically separate these two effects.
Model effect
The original prompts written by DALL - E 2 participants were evaluated on both DALL - E 2 and DALL - E 3.
The results showed that the cosine similarity increased by 0.0084 (p < 10^-8) when the same prompt was run on DALL - E 3, accounting for 51% of the total performance difference between the two groups.
Prompt effect
The original prompts of DALL - E 2 participants were compared with the prompts written by DALL - E 3 participants (both evaluated on DALL - E 3).
The results showed that this effect contributed the remaining 48% of the improvement, corresponding to an increase in cosine similarity of 0.0079 (p = 0.024).

Total treatment effect
The total treatment effect was 0