Mit einem Satz: Die Leistung steigt um 49 %. Werke von der Universität of Maryland und dem MIT: Prompts sind die ultimative Waffe für große Sprachmodelle.
Prompting ist die versteckte Trumpkarte von KI! Studien von Spitzeninstituten wie der Universität von Maryland und MIT belegen, dass die Hälfte der Prompts der Schlüssel ist, um die Leistung von KI um 49 % zu steigern.
Die Verbesserung der KI-Leistung hängt zur Hälfte von dem Modell und zur Hälfte von den Prompts ab.

Kürzlich haben Institutionen wie die Universität von Maryland, MIT und Stanford gemeinsam bestätigt, dass die Leistungserhöhung durch die Modell-Upgrade nur 50 % ausmacht, während die andere Hälfte der Verbesserung auf die Optimierung der Benutzer-Prompts zurückzuführen ist.
Sie nennen dies „Prompt-Anpassung“ (prompt adaptation).

Link zur Studie: https://arxiv.org/pdf/2407.14333v5
Dafür ließen sie DALL - E 2 und DALL - E 3 in einem Wettbewerb antreten. 1.893 „Teilnehmer“ sollten in 10 Versuchen mit einer der drei zufällig zugewiesenen Modelle das Zielbild reproduzieren.
Überraschenderweise war die Bildähnlichkeit von DALL - E 3 deutlich besser als die von DALL - E 2.
Dabei trug das Modell-Upgrade selbst nur 51 % zur Leistungserhöhung bei, der verbleibende 49 % waren vollständig auf die optimierten Prompts der Teilnehmer zurückzuführen.

Das Wichtigste ist, dass auch Personen ohne technischen Hintergrund durch die Optimierung von Prompts DALL - E 3 dazu bringen können, bessere Bilder zu generieren.

Greg Brockman, der Präsident von OpenAI, ist ebenfalls der Meinung, dass „um das volle Potenzial des Modells auszuschöpfen, tatsächlich einige spezielle Techniken erforderlich sind“.
Er rät den Entwicklern, ein „Prompt - Repository“ zu verwalten und ständig die Grenzen des Modells zu erkunden.

Mit anderen Worten, das Niveau Ihrer Prompts bestimmt, ob die KI von einem „Bronze - Spieler“ zu einem „König“ werden kann.
Warten Sie nicht auf GPT - 6! Besser „trainieren“ Sie Ihre Prompts
Die Effektivität von Generativer KI hängt nicht nur von der Technologie selbst ab, sondern auch davon, ob hochwertige Eingabeanweisungen entworfen werden können.
Nach dem Ruhm von ChatGPT im Jahr 2023 hat die Welt eine Welle der „Prompt - Engineering“ erlebt.
Ob,wohl die neue „Kontext - Engineering“ dieses Jahr im Mittelpunkt steht, ist die „Prompt - Engineering“ immer noch sehr beliebt.

Trotz des Konsenses fehlt es bei der Prompt-Entwicklung als dynamischer Praxis an einer tiefgehenden Untersuchung.
Die meisten Prompt-Repositories und Tutorials betrachten effektive Prompts als „wiederverwendbare Fertigprodukte“, aber sie können in neuen Vorlagen wirkungslos werden.
Dies bringt einige praktische Probleme mit sich: Kann die Prompt-Strategie auf andere Modellversionen übertragen werden? Oder muss sie ständig angepasst werden, um sich an die Verhaltensänderungen des Modells anzupassen?
Dafür hat das Forschungsunternehmen einen messbaren Verhaltensmechanismus namens „Prompt - Anpassung“ vorgeschlagen, um zu erklären, wie die Benutzer-Eingaben sich mit dem Fortschritt der Technologie entwickeln.
Sie konzeptualisieren dies als eine „dynamische komplementäre Fähigkeit“ und halten diese Fähigkeit für von entscheidender Bedeutung, um den wirtschaftlichen Wert von großen Modellen voll auszuschöpfen.
Um die Auswirkungen der Prompt - Anpassung auf die Modellleistung zu bewerten, hat das Team Daten aus einem vorregistrierten Online - Experiment auf der Prolific - Plattform verwendet und insgesamt 1.893 Teilnehmer eingeladen.
Jeder Teilnehmer wurde zufällig einem der drei Modelle mit unterschiedlicher Leistung zugewiesen: DALL - E 2, DALL - E 3 oder DALL - E 3 mit automatischer Prompt - Optimierung.

Außer der Modell-Zuweisung wurde jedem Teilnehmer auch unabhängig eines von 15 Zielbildern zugewiesen. Diese Bilder stammen aus den drei Kategorien kommerzieller Marketing, Grafikdesign und Architekturfotografie.
Den Teilnehmern wurde klar mitgeteilt, dass das Modell keine Gedächtnisfunktion hat - jeder neue Prompt wird unabhängig behandelt und erbt keine Informationen aus früheren Versuchen.
Jeder musste mindestens 10 Prompts einreichen, um das Zielbild so gut wie möglich mit dem Modell zu reproduzieren. Die besten Teilnehmer würden mit hohen Preisen belohnt.
Nach dem Abschluss der Aufgabe mussten die Teilnehmer eine Bevölkerungsstatistikumfrage ausfüllen, die Alter, Geschlecht, Bildungsniveau, Beruf und die selbst eingeschätzte Fähigkeit in kreativem Schreiben, Programmieren und generativer KI abdeckt.
Zufällige Zuweisung, 10 Generierungen
Der zentrale Ergebnisindikator des Experiments war die Ähnlichkeit zwischen jedem von den Teilnehmern generierten Bild und dem angegebenen Zielbild.
Dieser Indikator wurde durch die Kosinus-Ähnlichkeit der CLIP-Eingebettungsvektoren quantifiziert.
Da die Ausgabe von generativen Modellen zufällig ist, kann der gleiche Prompt in verschiedenen Versuchen unterschiedliche Bilder erzeugen.
Um diese Variabilität zu kontrollieren, haben die Forscher für jeden Prompt 10 Bilder generiert und jeweils ihre Kosinus - Ähnlichkeit mit dem Zielbild berechnet. Anschließend wurde der Durchschnitt dieser 10 Ähnlichkeitswerte als erwarteter Qualitätswert für diesen Prompt genommen.
Wiedergabeanalyse: Modell oder Prompt?
Ein weiteres zentrales Ziel des Experiments war es, zu klären, wie viel der Verbesserung der Bildreproduktionsleistung auf ein stärkeres Modell und wie viel auf die Optimierung der Prompts zurückzuführen ist?
Nach der Formulierung des Konzeptrahmens kann die Gesamtverbesserung der Ausgabequalität, wenn das Modell von der Fähigkeitsstufe θ1 auf die höhere Stufe θ2 aktualisiert wird, wie folgt ausgedrückt werden:
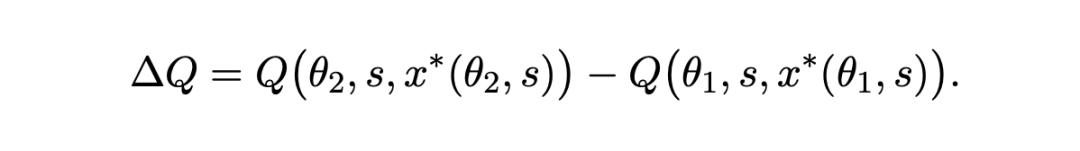
Die Forscher haben diese Veränderung in zwei Teile aufgeteilt:
1. Modelleffekt: Die Leistungserhöhung, die durch die Anwendung desselben Prompts auf ein besseres Modell erzielt wird;
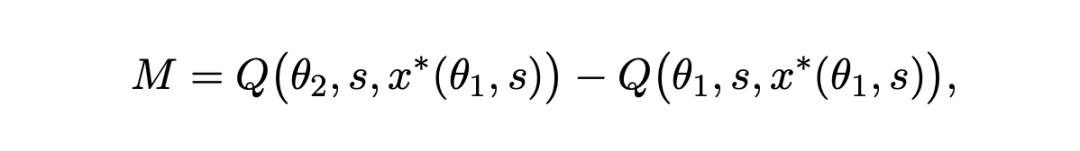
2. Prompt-Effekt: Die zusätzliche Verbesserung, die durch die Anpassung des Prompts, um die Vorteile eines stärkeren Modells voll auszunutzen, erzielt wird.
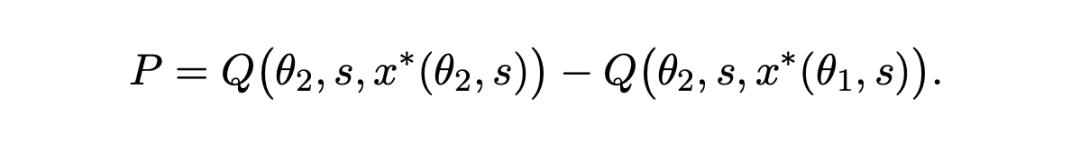
Um diese beiden Komponenten empirisch zu bewerten, haben die Forscher eine zusätzliche Analyse der Prompts von den Teilnehmern in den Experimentalgruppen von DALL - E 2 und DALL - E 3 (Originalversion) durchgeführt.
Die genaue Methode war, die ursprünglichen Prompts, die die Teilnehmer während des Experiments eingereicht hatten, erneut an das ursprünglich zugewiesene Modell und an das andere Modell zu senden und jeweils neue Bilder zu generieren.
· Trennung des Modelleffekts
Für die Prompts (x*(θ1,s)), die von den Teilnehmern von DALL - E 2 geschrieben wurden, hat das Team sowohl auf dem DALL - E 2 - als auch auf dem DALL - E 3 - Modell eine Bewertung durchgeführt und jeweils die gemessenen Werte von Q[θ1s,x*(θ1,s)] und Q[θ2,s,x*(θ_1,s)] erhalten.
Dieser Vergleich kann den Modelleffekt trennen: d. h. die Verbesserung der Ausgabequalität, die nur durch die Upgrade des Modells bei festem Prompt erzielt wird.
· Vergleich des Prompt-Effekts
Um den Prompt - Effekt zu bewerten, haben die Autoren auch die folgenden beiden Datensätze verglichen:
1. Die Qualität der Wiedergabe der DALL - E 2 - Prompts auf DALL - E 3 (d. h. der geschätzte Wert von Q[θ2,s,x*(θ1,s)])
2. Die Qualität der Prompts, die die Teilnehmer von DALL - E 3 speziell für das Modell geschrieben haben, auf demselben Modell (d. h. der geschätzte Wert von Q[θ2,s,x*(θ2,s)])
Dieser Unterschied spiegelt genau die zusätzliche Verbesserung des Modells wider, die die Benutzer durch die Anpassung der Prompts erzielen.
Wie waren die genauen Ergebnisse dieses Experiments?
Die starke Bildgenerationsfähigkeit von DALL - E 3 wird zur Hälfte durch die Prompts freigeschaltet
Im Experiment hat das Forschungsunternehmen hauptsächlich drei Fragen untersucht:
(i) Kann die Anbindung an ein stärkeres Modell (DALL - E 3) die Leistung der Benutzer verbessern;
(ii) Wie ändern oder optimieren die Benutzer ihre Prompts, wenn sie ein stärkeres Modell verwenden;
(iii) Wie viel der gesamten Leistungserhöhung sollte auf die Modellverbesserung und wie viel auf die adaptive Anpassung der Prompts zurückgeführt werden.
Modell-Upgrade ist der Kern
Zunächst hat das Team überprüft, ob die Teilnehmer, die DALL - E 3 verwenden, besser abschneiden als die Teilnehmer, die DALL - E 2 verwenden?
Wie in Abbildung 1 unten gezeigt, sind alle Ergebnisse,zusammengefasst.
A zeigt drei repräsentative Gruppen von Zielbildern, wobei jede Gruppe drei Bilder aus beiden Modellen enthält.
Die mittlere Zeile zeigt die Generationsergebnisse, deren Kosinus - Ähnlichkeit mit dem Zielbild am nächsten an dem Durchschnittswert aller Teilnehmer liegt. Die obere (untere) Zeile zeigt Bilder, deren Ähnlichkeit um etwa einen durchschnittlichen Behandlungseffekt (ATE) höher (niedriger) als der Mittelwert ist.
Bei 10 erforderlichen Prompt - Versuchen war die durchschnittliche Kosinus - Ähnlichkeit der von den Teilnehmern, die DALL - E 3 verwendeten, generierten Bilder mit dem Zielbild um 0.0164 höher.
Diese Verbesserung entspricht 0.19 Standardabweichungen, wie in Abbildung 1 B gezeigt.
Außerdem bestand dieser Vorteil in allen 10 Versuchen. Daher ist unbestreitbar, dass das Modell - Upgrade eine signifikante Leistungserhöhung im Vergleich zur Vorgängerversion bringt.

Außerdem bestanden signifikante Unterschiede im dynamischen Prompt - Verhalten der Teilnehmer zwischen den beiden Modellen:
Abbildung C