With only 0.27B parameters, Google has open - sourced Gemma 3, the smallest in its history, which can run on mobile phones and consumes less than 1% of battery power for 25 conversations.

According to a report from ZDONGXI on August 15th, today, Google launched the smallest open - source Gemma 3 model in history, a lightweight model with 270 million parameters. Its underlying design aims at fine - tuning for specific tasks and has powerful instruction - following and text capabilities.
In the instruction execution ability test, as shown in the IFEval benchmark test, Gemma 3 270M outperformed the larger Qwen2.5 0.5B Instruct and was comparable to Llama 3.2 1B in terms of capabilities.
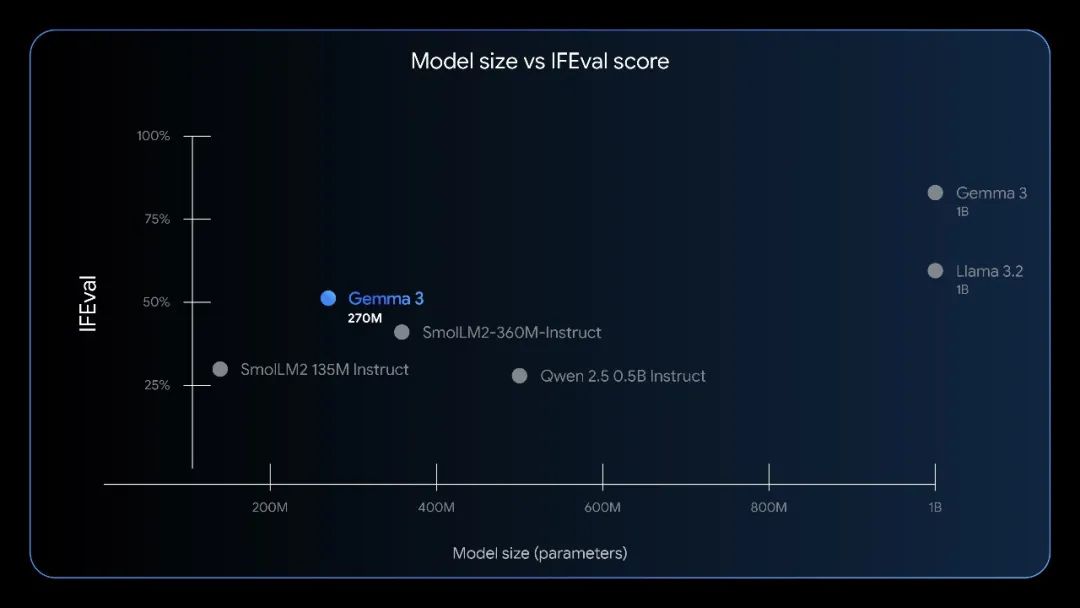
Gemma 3 270M can reach or even exceed the capabilities of large models in some specific tasks. The size and performance of this model make it very suitable for offline, web - based creative tasks. For example, Google announced a case where it used Gemma 3 270M to power a bedtime story generator web application using Transformers.js, and wonderful bedtime stories can be generated through simple check - marking.
The core capabilities of Gemma 3 270M are as follows:
1. Lightweight and powerful architecture. This model has a total of 270 million parameters. Due to the large vocabulary, there are 170 million embedding parameters and 100 million Transformer module parameters. Thanks to the large vocabulary of 256k tokens, the model can handle specific and rare tokens, making it an excellent base model for further fine - tuning in specific domains and languages.
2. Extreme energy efficiency. One of the major advantages of this model is its low power consumption. Internal tests on the Pixel 9 Pro SoC show that the INT4 quantized model only consumes 0.75% of the battery power in 25 conversations, making it Google's most energy - efficient Gemma model.
3. Instruction following. The model was released simultaneously with an instruction - fine - tuned version and a pre - trained checkpoint. Although the model is not designed for complex conversation use cases, its basic instruction - following ability is excellent and can respond to general instructions "out of the box".
4. Quantization for production. The model provides Quantization - Aware Trained (QAT) checkpoints, supporting operation with INT4 precision with minimal performance loss, which is crucial for deployment on resource - constrained devices (such as mobile phones and edge devices).
In other words, if users have a high - volume, well - defined task, need to be cost - conscious, require rapid iteration and deployment, or have privacy protection requirements, they are suitable to choose Gemma 3 270M.
Hugging Face address: https://huggingface.co/collections/google/gemma - 3 - release - 67c6c6f89c4f76621268bb6d
Conclusion: Lightweight models unleash edge - side intelligence
Previously, Google's Gemma open - source model accelerated its iteration: first, Gemma 3 and Gemma 3 QAT, suitable for single - cloud and desktop accelerators, were released, followed by the launch of Gemma 3n, which directly introduced powerful real - time multimodal AI to edge devices. The launch of Gemma 3 270M fills the lightweight model segment.
Lightweight models are breaking the superstition of parameters. There has long been an inherent perception in the field of large models that "parameter scale determines performance". Gemma 3 270M demonstrates the instruction - following ability of small models and the power after fine - tuning. Starting with lightweight and powerful models, users can build production systems that are streamlined, fast, and have significantly reduced operating costs.
This article is from the WeChat public account “ZDONGXI” (ID: zhidxcom), written by Li Shuiqing and published by 36Kr with authorization.