Embodied agents actively confront adversarial attacks. A Tsinghua University team proposes an active defense framework.
Facing adversarial attacks, embodied agents can not only defend passively but also take the initiative!
Inspired by the human visual system, the team led by Zhu Jun from Tsinghua University proposed an active defense framework REIN - EAD driven by reinforcement learning in TPMAI 2025.
This framework enables agents to learn to "take a second look", enhancing the perceptual robustness in adversarial scenarios.

Adversarial attacks have become a major threat to the safety and reliability of visual perception systems. Such attacks manipulate the prediction results of deep neural networks by placing carefully designed disturbing objects (such as adversarial patches and 3D adversarial objects) in three - dimensional physical scenes.
In safety - critical fields such as face recognition and autonomous driving, the consequences of such vulnerabilities are particularly severe. Incorrect predictions may seriously damage the system's safety.
However, most existing defense methods rely on attack priors and achieve "passive defense" against harmful images through means such as adversarial training or input purification. They ignore the rich information that can be obtained through interaction with the environment, and their effectiveness decays rapidly when encountering unknown or adaptive attacks.
In contrast, the human visual system is more flexible. It can naturally reduce the uncertainty of instantaneous perception through active exploration and error correction.
Similarly, the core of REIN - EAD lies in using environmental interaction and strategy exploration to continuously observe and cyclically predict the target, optimizing the immediate accuracy while considering the long - term prediction entropy and alleviating the hallucinations caused by adversarial attacks.
In particular, this framework introduces a reward shaping mechanism based on uncertainty, which can achieve efficient strategy updates without relying on a differentiable environment and support robust training in physical environments.
Experimental verification shows that REIN - EAD significantly reduces the attack success rate in multiple tasks while maintaining the standard accuracy of the model. It also performs excellently when facing unknown attacks and adaptive attacks, demonstrating strong generalization ability.
Main Contributions
(1) Propose the REIN - EAD model, integrating the perception and strategy modules to simulate the motion vision mechanism
The paper designs an active defense framework REIN - EAD that combines a perception module and a strategy module. Drawing on the way the human brain supports motion vision, the model can continuously observe, explore, and reconstruct its understanding of the scene in a dynamic environment.
REIN - EAD constructs a robust environmental representation with temporal consistency by integrating current and historical observations, thereby enhancing the system's ability to identify and adapt to potential threats.
(2) Introduce a reinforcement learning method based on cumulative information exploration to optimize the active strategy
To improve the strategy learning ability of REIN - EAD, the paper proposes a reinforcement learning algorithm based on cumulative information exploration. It optimizes the multi - step exploration path through guided dense rewards and introduces an uncertainty - aware mechanism to drive informative exploration.
This method strengthens the consistent exploration behavior over time and eliminates the dependence on differentiable environment modeling through the reinforcement learning paradigm. It enables the system to actively identify potentially high - risk areas and dynamically adjust its behavior strategy, significantly improving the effectiveness of observation data and the system's safety.
(3) Propose the Offline Adversarial Patch Approximation (OAPA) technique to achieve efficient and highly generalizable defense capabilities
To address the challenge of the huge computational cost of adversarial training in 3D environments, the paper proposes the OAPA technique. Through offline approximation of the adversarial patch manifold, a universal defense mechanism independent of the opponent's information is constructed.
OAPA significantly reduces the training cost and has robust defense capabilities in unknown or adaptive attack scenarios, providing a practical and efficient solution for active defense in 3D environments.
(4) Achieve superior performance in multiple tasks and environments, demonstrating excellent generalization and adaptation abilities
The paper conducts a systematic evaluation in multiple standard adversarial test environments and tasks. The experimental results show that REIN - EAD performs significantly better than existing passive defense methods in resisting various unknown and adaptive attacks.
Its excellent generalization ability and adaptability to complex real - world scenarios further verify the application potential of the proposed method in safety - critical systems.
Methods and Theories
REIN - EAD Framework
REIN - EAD is an adversarial defense framework that simulates the active perception and reaction abilities of humans in dynamic environments. As shown in the figure below, through the collaboration of the perception module and the strategy module, the system has the ability to actively interact with the environment, iteratively collect information, and enhance its own robustness.
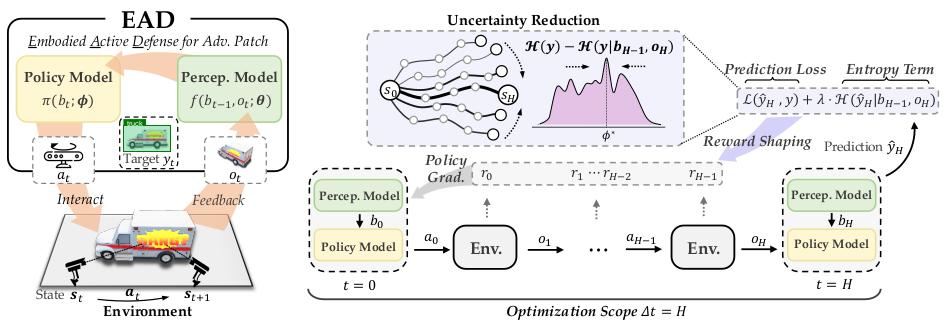
△ Figure 1: REIN - EAD Framework
REIN - EAD consists of two core recurrent neural modules, inspired by the brain structure that supports the human active visual system:
Perception Model is responsible for synthesizing the current observation and the previous internal belief state at each time step to generate an enhanced representation of the environmental state and predict the current scene label accordingly. This model fully utilizes the sequential information obtained through interaction with the environment through a recurrent structure, thereby achieving a robust understanding of complex visual inputs;
Strategy Model generates an action signal for controlling the next perception behavior based on the internal environmental understanding constructed by the perception model, that is, it decides from which perspective and in what way to continue collecting information, thereby strategically guiding the visual system to perform goal - driven active perception tasks.
Through the closed - loop linkage of the perception model and the strategy model, REIN - EAD realizes the "perception - decision - action" integration in the adversarial defense process:
It selects the long - term optimal interaction action at each moment and continuously corrects its internal representation according to the environmental feedback, enabling the model to obtain the most informative observation feedback from multi - step interactions.
This active defense mechanism breaks through the bottlenecks of traditional static defense strategies in terms of robustness and adaptability, significantly improving the system's recognition and response abilities when facing unknown attacks.
Reinforcement Learning Strategy Based on Cumulative Information Exploration
The paper extends the Partially Observable Markov Decision Process (POMDP) framework to formally describe the interaction between the REIN - EAD framework and the environment.
The interaction process in the scenario is represented by.
Here represent the state, action, and observation spaces respectively. The state transition in the scenario follows the Markov property.
Due to the partial observability of the environment, the agent cannot directly access the state but receives an observation value sampled from the observation function.
The prediction process of REIN - EAD is continuous observation and cyclic prediction under multi - step conditions. Perception and action are cyclically dependent - perception guides action, and action in turn obtains better perception.
Intuitively, the EAD framework under multi - step conditions can be optimized through an RNN - style training method. However, the team has proven the drawbacks of this approach.
First, the paper proves through theoretical analysis that the RNN - style training method is essentially a greedy exploration strategy:
This greedy exploration strategy may cause EAD to adopt a locally optimal strategy, making it difficult to continuously benefit from multi - step exploration.
△ Figure 2: Greedy information exploration may lead to repeated exploration
Second, back - propagating gradients along time steps requires the state transition function and the observation function to be differentiable, which is not satisfied in real - world environments and common simulation engines (such as UE).
Finally, back - propagating gradients under multi - step conditions requires constructing a very long gradient chain, which may lead to gradient vanishing/explosion and bring huge memory overhead.
To address the sub - optimality of the greedy strategy and improve the performance of REIN - EAD, the paper introduces the definition of cumulative information exploration:
and multi - step cumulative interaction objective:
Here, is the exploration trajectory, represents the prediction loss at time step, and as a regularization term, represents the label prediction entropy at time step, preventing the agent from making high - entropy predictions with adversarial characteristics.
The multi - step cumulative interaction objective includes an objective term for minimizing the prediction loss and a regularization term for penalizing high - entropy predictions. Through a series of interactions with the environment, the strategy is optimized within steps, minimizing the long - term uncertainty of the target variable rather than focusing only on single steps.
This objective minimizes the uncertainty of the target variable through a series of actions and observations, combining the prediction loss and the entropy regularization term to encourage the agent to reach an informative and robust cognitive state, thereby being robust to adversarial perturbations.
The paper proves the consistency between the proposed multi - step cumulative interaction objective and the definition of cumulative information exploration and further analyzes the performance superiority of the cumulative information strategy compared with the greedy information strategy.
To further eliminate the dependence on a differentiable training environment and reduce the instability of gradient optimization, the paper proposes a reinforcement strategy learning method that combines uncertainty - oriented reward shaping.
Uncertainty - oriented reward shaping provides dense rewards at each step, prompting the strategy to seek new observation results as feedback from the environment. It solves the sparsity problem of only obtaining rewards at the end of the episode in the multi - step cumulative interaction objective, alleviates the challenge of exploration - exploitation allocation, and promotes faster convergence and more effective learning.
The paper also proves the equivalence of this reward shaping and the multi - step cumulative interaction objective (see the paper for details).
For the reinforcement learning backbone, the paper uses Proximal Policy Optimization (PPO), which has good learning efficiency and convergence stability, to achieve stable strategy updates by limiting the size of the strategy.

Offline Adversarial Patch Approximation Technique
The paper also proposes Offline Adversarial Patch Approximation (OAPA) to address the computational cost of adversarial training in 3D environments.
The calculation of adversarial patches usually requires internal maximization iterations, which is not only computationally expensive but may also cause the defense to overfit to specific attack strategies, thus hindering the model's ability to generalize in unknown attacks.
To improve sampling efficiency while maintaining adversarial agnosticism, the paper introduces OAPA before training the REIN - EAD model. A set of alternative patches are obtained through offline approximation of the adversarial patch manifold by performing projected gradient ascent on the visual backbone in advance.
Experimental results show that performing this offline approximate maximization allows the REIN - EAD model to learn compact and expressive adversarial features, enabling it to effectively defend against unknown attacks.
In addition, since this maximization process occurs only once before training, it greatly improves the training efficiency, making it more competitive compared with traditional adversarial training.
Experiments and Results
The paper uses a series of white - box, black - box, and adaptive attack methods in pixel space and latent variable space on multiple tasks such as face recognition, 3D object classification, and object detection. The results show that REIN - EAD outperforms baseline defenses such as SAC, PZ, and DOA in all three tasks (Tables 1, 3, 4).
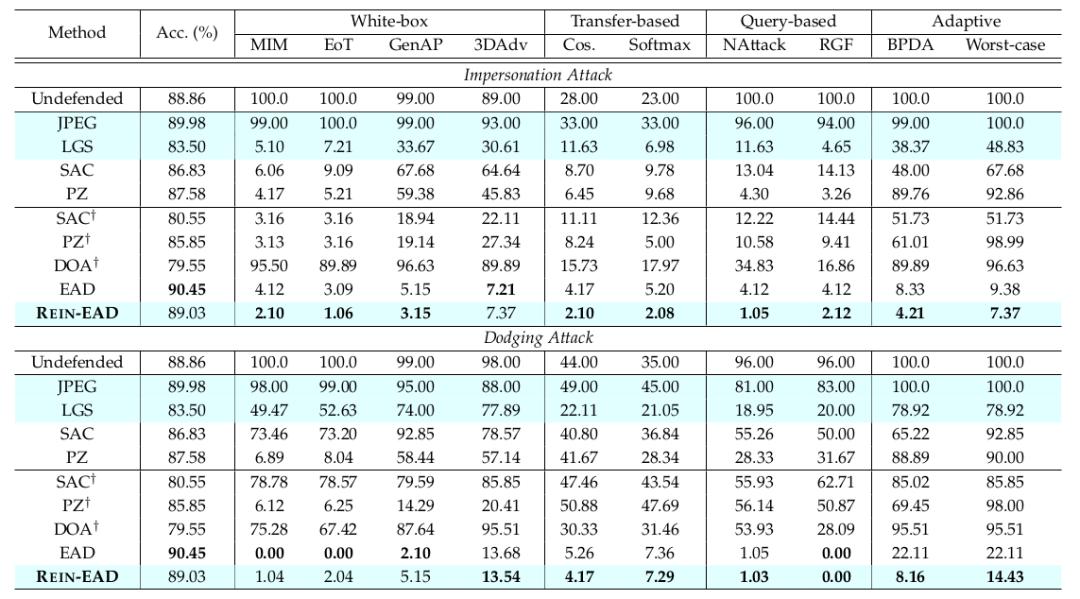
△ Table 1: Results under two attack targets of escape and impersonation in the face recognition task
In the face recognition task, the IResNet50 model is improved through the REIN - EAD framework, and the EG3D differentiable renderer is used to achieve differentiable 3D reconstruction of the CelebA - 3D dataset for a fair comparison between the cumulative exploration - based REIN - EAD and the greedy exploration - based EAD in the ICLR 2024 work.
The effectiveness of cumulative information exploration and OAPA is respectively proven through ablation of each component (Tables 1, 2, Figure 3).
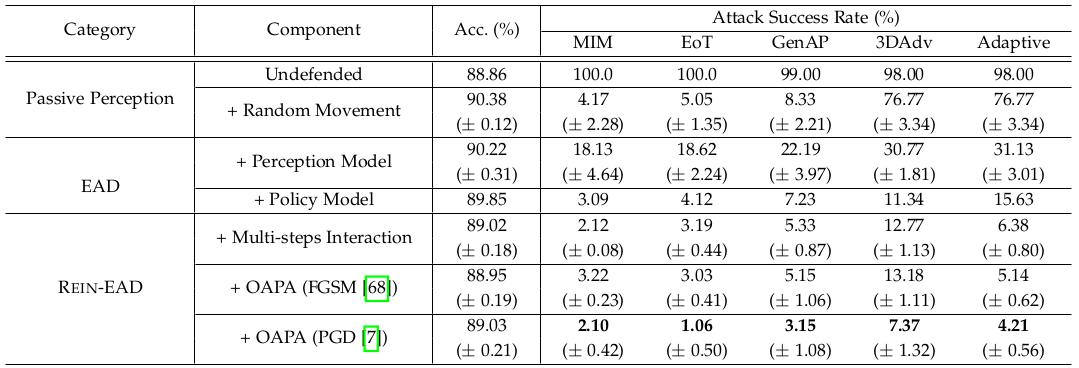
△ Table 2: Ablation results of the REIN - EAD module in the face recognition task

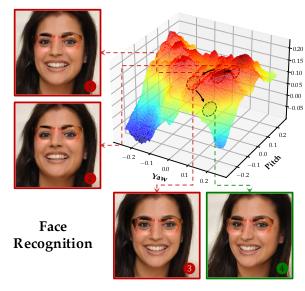
△ Figure 3: Visualization example of REIN - EAD in the face recognition experiment
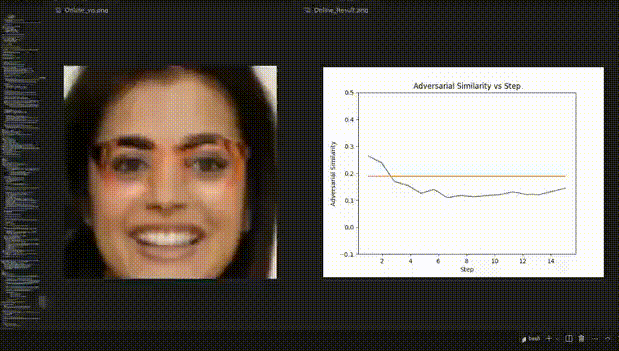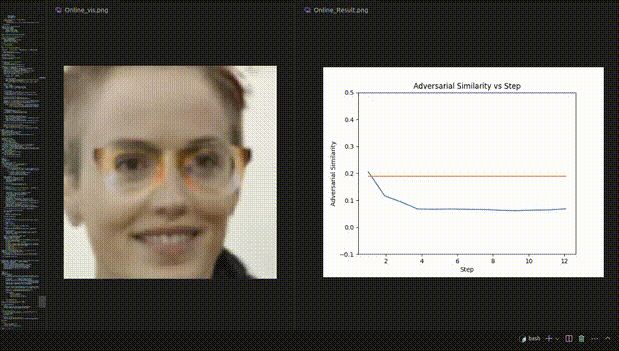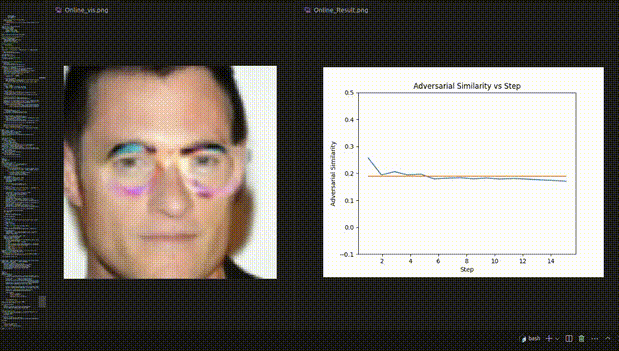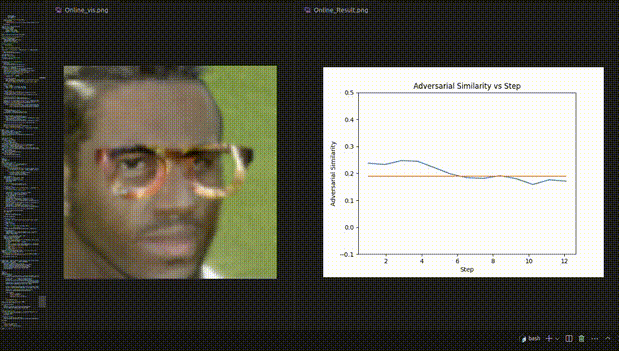
Visualization dynamic example of the face recognition experiment
In the object classification task, the Swin - S model is improved through the REIN - EAD framework, and Pytorch3D is used to perform differentiable rendering on the OmniObject3D 3D scanned object dataset to evaluate the generality of REIN - EAD in the image classification task in a 3D environment (Table 3).
Although REIN - EAD may be deceived by adversarial patches and make incorrect predictions in the early steps, it makes correct self - corrections in the subsequent steps (Figure 4).
