Embodied Agent greift aktiv gegen Angriffe an und eine Forschergruppe der Tsinghua-Universität stellt ein aktives Verteidigungsframework vor.
Angesichts von Angriffen kann ein eingebetteter Agent nicht nur passiv reagieren, sondern auch aktiv vorgehen!
Unter Inspiration des menschlichen visuellen Systems hat das Team von Zhu Jun aus Tsinghua-Universität im TPMAI 2025 einen von Reinforcement Learning angetriebenen aktiven Verteidigungsrahmen namens REIN - EAD vorgeschlagen.
Dieser Rahmen ermöglicht es dem Agenten, das "Zweite - Sehen" zu lernen und somit die Robustheit der Wahrnehmung in Angriffsszenarien zu verbessern.

Angriffe haben sich als erhebliche Bedrohung für die Sicherheit und Zuverlässigkeit von visuellen Wahrnehmungssystemen erwiesen. Solche Angriffe manipulieren die Vorhersagen von tiefen neuronalen Netzwerken, indem sie in dreidimensionalen physikalischen Szenarien sorgfältig gestaltete Störobjekte (wie Angriffspatches und dreidimensionale Angriffsobjekte) platzieren.
In sicherheitskritischen Bereichen wie Gesichtserkennung und automatisiertem Fahren sind die Folgen solcher Schwachstellen besonders gravierend. Fehlvorhersagen können die Systemssicherheit erheblich beeinträchtigen.
Die meisten bestehenden Verteidigungsansätze verlassen sich jedoch auf Angriffsvorwissen und erreichen eine "passive Verteidigung" gegen schädliche Bilder durch Angriffstraining oder Eingangspurifikation. Dabei wird die reichhaltige Information, die durch die Interaktion mit der Umwelt gewonnen werden kann, ignoriert. Bei unbekannten oder adaptiven Angriffen sinkt die Wirksamkeit dieser Ansätze schnell.
Im Gegensatz dazu ist das menschliche visuelle System flexibler und kann die Unsicherheit der Momentanwahrnehmung durch aktive Exploration und Fehlerkorrektur natürlich verringern.
Ähnlich wie das menschliche System liegt der Kern von REIN - EAD darin, durch die Interaktion mit der Umwelt und die Strategieexploration das Ziel kontinuierlich zu beobachten und zyklisch vorherzusagen, um die sofortige Genauigkeit zu optimieren und gleichzeitig die langfristige Vorhersageentropie zu berücksichtigen und die Halluzinationen, die durch Angriffe verursacht werden, zu lindern.
Insbesondere führt dieser Rahmen einen auf Unsicherheit basierten Belohnungsformungsmechanismus ein, der eine effiziente Strategieaktualisierung ermöglicht, ohne sich auf differenzierbare Umgebungen zu verlassen, und ein robustes Training in der physikalischen Umwelt unterstützt.
Experimentelle Ergebnisse zeigen, dass REIN - EAD in mehreren Aufgaben die Angriffserfolgsrate erheblich verringert und gleichzeitig die Standardgenauigkeit des Modells beibehält. Es zeigt sich auch bei unbekannten und adaptiven Angriffen ausgezeichnet und weist eine starke Generalisierungsfähigkeit auf.
Hauptbeiträge
(1) Vorschlag des REIN - EAD - Modells, das das Wahrnehmungs - und Strategiemodul integriert, um den Mechanismus der Bewegungsvision zu simulieren
Die Studie entwirft einen aktiven Verteidigungsrahmen namens REIN - EAD, der das Wahrnehmungsmodul und das Strategiemodul kombiniert. Inspiriert von der Funktionsweise des menschlichen Gehirns, das die Bewegungsvision unterstützt, kann das Modell in einer dynamischen Umwelt kontinuierlich beobachten, erkunden und seine Vorstellung der Szene neu aufbauen.
REIN - EAD baut eine zeitlich konsistente und robuste Umweltrepräsentation durch die Integration der aktuellen und historischen Beobachtungen auf, um die Fähigkeit des Systems zur Erkennung und Anpassung an potenzielle Bedrohungen zu verbessern.
(2) Einführung einer auf kumulativer Informationsexploration basierten Reinforcement - Learning - Methode zur Optimierung der aktiven Strategie
Um die Strategielernfähigkeit von REIN - EAD zu verbessern, schlägt die Studie einen auf kumulativer Informationsexploration basierten Reinforcement - Learning - Algorithmus vor. Dieser Algorithmus optimiert den mehrschrittigen Erkundungsweg durch geführte dichte Belohnungen und führt einen Unsicherheitswahrnehmungsmechanismus ein, um die informative Exploration anzutreiben.
Diese Methode stärkt die zeitliche konsistente Erkundungsaktivität und beseitigt durch das Reinforcement - Learning - Paradigma die Abhängigkeit von der Modellierung differenzierbarer Umgebungen. Dadurch kann das System potenzielle Hochrisikogebiete aktiv erkennen und seine Verhaltensstrategie dynamisch anpassen, was die Effektivität der Beobachtungsdaten und die Systemssicherheit erheblich verbessert.
(3) Vorschlag der Offline - Angriffspatch - Approximationstechnik (OAPA) zur Erzielung einer effizienten und stark generalisierenden Verteidigungsfähigkeit
Angesichts der hohen Rechenkosten des Angriffstrainings in 3D - Umgebungen schlägt die Studie die OAPA - Technik vor. Durch die Offline - Approximation des Angriffspatch - Manifolds wird ein universeller Verteidigungsmechanismus aufgebaut, der nicht auf Informationen über den Gegner angewiesen ist.
OAPA senkt die Trainingskosten erheblich und weist eine robuste Verteidigungsfähigkeit in unbekannten oder adaptiven Angriffsszenarien auf. Es bietet eine praktische und effiziente Lösung für die aktive Verteidigung in dreidimensionalen Umgebungen.
(4) Erzielung hervorragender Leistung in mehreren Aufgaben und Umgebungen, die eine ausgezeichnete Generalisierungs - und Anpassungsfähigkeit zeigt
Die Studie führt eine systematische Evaluierung in mehreren Standard - Angriffstestumgebungen und Aufgaben durch. Die experimentellen Ergebnisse zeigen, dass REIN - EAD bei der Abwehr verschiedener unbekannter und adaptiver Angriffe eine deutlich bessere Leistung als bestehende passive Verteidigungsansätze aufweist.
Seine hervorragende Generalisierungsfähigkeit und die Anpassungsfähigkeit an komplexe reale Weltumgebungen bestätigen weiter das Anwendungspotenzial der hier vorgestellten Methode in sicherheitskritischen Systemen.
Methode und Theorie
REIN - EAD - Rahmen
REIN - EAD ist ein Angriffsverteidigungsrahmen, der die Fähigkeit des Menschen zur aktiven Wahrnehmung und Reaktion in einer dynamischen Umwelt simuliert. Dieser Rahmen (wie in der folgenden Abbildung gezeigt) ermöglicht es dem System, durch die Zusammenarbeit des Wahrnehmungsmoduls und des Strategiemoduls aktiv mit der Umwelt zu interagieren, Informationen iterativ zu sammeln und seine eigene Robustheit zu stärken.
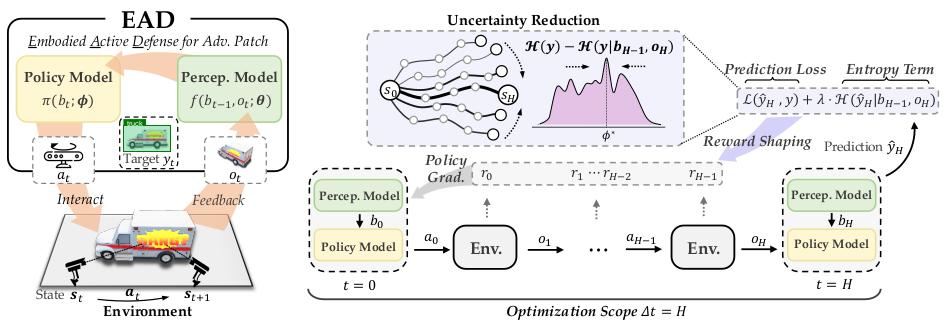
△Abbildung 1: REIN - EAD - Rahmen
REIN - EAD besteht aus zwei zentralen rekurrenten neuronalen Modulen, die von der Gehirnstruktur inspiriert sind, die das aktive visuelle System des Menschen unterstützt:
Das Wahrnehmungsmodell ist für die Synthese der aktuellen Beobachtung und des internen Glaubenszustands des vorherigen Schritts in jedem Zeitschritt verantwortlich. Es erzeugt eine verbesserte Repräsentation des Umweltzustands und prognostiziert daraus das aktuelle Szenenlabel. Durch die rekurrente Struktur nutzt dieses Modell die sequentielle Information, die durch die Interaktion mit der Umwelt gewonnen wird, um eine robuste Vorstellung von komplexen visuellen Eingängen zu erreichen;
Das Strategiemodell erzeugt auf der Grundlage des internen Umweltverständnisses, das vom Wahrnehmungsmodell aufgebaut wird, ein Handlungssignal, um die nächste Wahrnehmungsaktion zu steuern. Das heißt, es entscheidet, aus welchem Blickwinkel und auf welche Weise die Information weiterhin gesammelt werden soll, um das visuelle System strategisch zu einem zielgerichteten aktiven Wahrnehmungstask zu führen.
Durch die geschlossene Kopplung des Wahrnehmungsmodells und des Strategiemodells erreicht REIN - EAD die "Integration von Wahrnehmung - Entscheidung - Handlung" im Angriffsverteidigungsprozess:
Es wählt in jedem Moment die langfristig optimale Interaktionshandlung aus und korrigiert seine interne Repräsentation ständig basierend auf der Umweltrückmeldung, sodass das Modell die informativste Beobachtungsrückmeldung aus der mehrschrittigen Interaktion gewinnen kann.
Dieser aktive Verteidigungsmechanismus überwindet die Engpässe traditioneller statischer Verteidigungsstrategien in Bezug auf Robustheit und Anpassungsfähigkeit und verbessert erheblich die Fähigkeit des Systems zur Erkennung und Reaktion auf unbekannte Angriffe.
Reinforcement - Learning - Strategie auf der Grundlage kumulativer Informationsexploration
Die Studie erweitert den Rahmen des teilweise beobachtbaren Markov - Entscheidungsprozesses (POMDP), um die Interaktion zwischen dem REIN - EAD - Rahmen und der Umwelt formal zu beschreiben.
Der Interaktionsprozess in einem Szenario wird mit dargestellt.
Hier repräsentieren den Zustands-, Handlungs- und Beobachtungsraum. Der Zustandsübergang in einem Szenario folgt der Markov - Eigenschaft.
Aufgrund der teilweisen Beobachtbarkeit der Umwelt kann der Agent den Zustand nicht direkt zugreifen, sondern erhält Beobachtungswerte, die aus der Beobachtungsfunktion gesampelt werden.
Der Vorhersageprozess von REIN - EAD ist eine kontinuierliche Beobachtung und zyklische Vorhersage unter mehrschrittigen Bedingungen. Wahrnehmung und Handlung sind zyklisch voneinander abhängig - die Wahrnehmung leitet die Handlung, und die Handlung wiederum verbessert die Wahrnehmung.
Intuitiv kann der EAD - Rahmen unter mehrschrittigen Bedingungen durch eine RNN - Style - Trainingsmethode optimiert werden. Die Studie zeigt jedoch die Nachteile dieser Vorgehensweise.
Zunächst beweist die Studie durch theoretische Analyse, dass die RNN - Style - Trainingsmethode im Wesentlichen eine gierige Erkundungsstrategie ist:
Diese gierige Erkundungsstrategie kann dazu führen, dass EAD eine lokal optimale Strategie wählt und es schwierig ist, dauerhaft von der mehrschrittigen Exploration zu profitieren.
△Abbildung 2: Gierige Informationsexploration kann zu wiederholter Exploration führen
Zweitens erfordert die Rückwärtsverteilung des Gradienten entlang der Zeitschritte, dass die Zustandsübergangsfunktion und die Beobachtungsfunktion differenzierbar sein müssen. Diese Eigenschaft ist in realen Umgebungen und gängigen Simulationsmotoren (wie UE) nicht erfüllt.
Schließlich erfordert die Rückwärtsverteilung des Gradienten unter mehrschrittigen Bedingungen die Konstruktion einer sehr langen Gradientenkette, was zu Gradientenverschwindung/Explosion führen kann und enorme Grafikspeicherauslastung verursacht.
Um die suboptimale Natur der gierigen Strategie zu beseitigen und die Leistung von REIN - EAD zu verbessern, führt die Studie die Definition der kumulativen Informationsexploration ein:
sowie das mehrschrittige kumulative Interaktionsziel:
Dabei ist die Erkundungsspur, der Vorhersageverlust im Zeitschritt, und als Regularisierungsterm repräsentiert die Labelvorhersageentropie im Zeitschritt, um zu verhindern, dass der Agent hochentropische Vorhersagen mit Angriffseigenschaften macht.
Das mehrschrittige kumulative Interaktionsziel enthält ein Zielterm zur Minimierung des Vorhersageverlusts und einen Regularisierungsterm zur Bestrafung hochentropischer Vorhersagen. Durch eine Reihe von Interaktionen mit der Umwelt wird die Strategie innerhalb von Schritten optimiert, um die langfristige Unsicherheit der Zielvariablen zu minimieren, anstatt sich nur auf einen einzigen Schritt zu konzentrieren.
Dieses Ziel minimiert die Unsicherheit der Zielvariablen durch eine Reihe von Handlungen und Beobachtungen. Indem es den Vorhersageverlust und den Entropie - Regularisierungsterm kombiniert, ermutigt es den Agenten, einen informationsreichen und robusten Erkenntniszustand zu erreichen, der robust gegen Angriffsstörungen ist.
Die Studie beweist die Übereinstimmung der Definition des vorgeschlagenen mehrschrittigen kumulativen Interaktionsziels und der kumulativen Informationsexploration und analysiert weiter die Leistungsüberlegenheit der kumulativen Informationsstrategie im Vergleich zur gierigen Informationsstrategie.
Um die Abhängigkeit von einer differenzierbaren Trainingsumgebung zu beseitigen und die Instabilität der Gradientenoptimierung zu verringern, schlägt die Studie eine Reinforcement - Strategielernmethode mit unsicherheitsorientierter Belohnungsformung vor.
Die unsicherheitsorientierte Belohnungsformung bietet in jedem Schritt dichte Belohnungen, um die Strategie dazu zu bringen, neue Beobachtungsergebnisse als Rückmeldung aus der Umwelt zu suchen. Dadurch wird das Problem der Sparsität der Belohnung, die nur am Ende einer Runde erhalten werden kann, im mehrschrittigen kumulativen Interaktionsziel gelöst. Die Herausforderung der Verteilung von Exploration und Ausnutzung wird gemildert, und ein schnellerer Konvergenz und ein effizienteres Lernen werden gefördert.
Die Studie beweist auch die Äquivalenz dieser Belohnungsformung und des mehrschrittigen kumulativen Interaktionsziels (Details siehe in der Studie).
Für den Reinforcement - Learning - Kern wird die Proximal Policy Optimization (PPO) gewählt, die eine gute Lernleistung und Konvergenzstabilität hat. Durch die Begrenzung der Strategiegöße wird eine stabile Strategieaktualisierung erreicht.

Offline - Angriffspatch - Approximationstechnik
Die Studie schlägt auch die Offline - Angriffspatch - Approximation (OAPA) vor, um die Rechenkosten des Angriffstrainings in 3D - Umgebungen zu reduzieren.
Die Berechnung des Angriffspatches erford