Covering nearly 15,000 species, Google's DeepMind has released Perch 2.0, refreshing the state-of-the-art (SOTA) in bioacoustic classification and detection.
Perch 2.0, jointly launched by Google DeepMind and Google Research, further propels bioacoustic research to new heights. Compared with its predecessor, Perch 2.0 takes species classification as the core training task. It not only incorporates more training data from non - avian taxa but also adopts a new data augmentation strategy and training objectives. It has refreshed the current state - of - the - art (SOTA) in both the BirdSET and BEANS authoritative bioacoustic benchmark tests.
Bioacoustics, as an important tool connecting biology and ecology, plays a crucial role in biodiversity conservation and monitoring. Early studies mostly relied on traditional signal processing methods such as template matching. In the face of complex natural acoustic environments and large - scale data, these methods gradually showed limitations in terms of low efficiency and insufficient accuracy.
In recent years, the explosive development of artificial intelligence technology has promoted deep learning and other methods to replace traditional means and become the core tools for bioacoustic event detection and classification. For example, the BirdNET model, which is trained on a large - scale labeled avian acoustic dataset, performs excellently in bird vocalization recognition. It can not only accurately distinguish the calls of different species but also achieve individual recognition to a certain extent. In addition, models such as Perch 1.0 have accumulated rich achievements in the field of bioacoustics through continuous optimization and iteration, providing solid technical support for biodiversity monitoring and conservation.
Recently, Perch 2.0, jointly launched by Google DeepMind and Google Research, further propels bioacoustic research to new heights. Compared with its predecessor, Perch 2.0 takes species classification as the core training task. It not only incorporates more training data from non - avian taxa but also adopts a new data augmentation strategy and training objectives. This model has refreshed the current SOTA in both the BirdSET and BEANS authoritative bioacoustic benchmark tests, demonstrating its powerful performance potential and broad application prospects.
The relevant research results are published as a preprint on arXiv under the title "Perch 2.0: The Bittern Lesson for Bioacoustics".
Paper link: https://arxiv.org/abs/2508.04665
Dataset: Training Data Construction and Evaluation Benchmark
This study integrates 4 labeled audio datasets for model training - Xeno - Canto, iNaturalist, Tierstimmenarchiv, and FSD50K, which together form the basic data support for the model's learning. As shown in the following table, Xeno - Canto and iNaturalist are large - scale citizen science libraries. The former is obtained through a public API, and the latter is sourced from the audio labeled as research - grade on the GBIF platform. Both contain a large number of acoustic recordings of birds and other organisms. Tierstimmenarchiv, as the animal sound archive of the Natural History Museum in Berlin, also focuses on the field of bioacoustics. FSD50K supplements a variety of non - avian sounds.
These four types of data contain a total of 14,795 categories, among which 14,597 are species, and the remaining 198 are non - species sound events. The rich category coverage not only ensures in - depth learning of bioacoustic signals but also expands the model's scope of application through non - avian sound data. However, since the first three datasets use different species classification systems, the research team manually mapped and unified the category names and removed the bat recordings that could not be represented by the selected spectrogram parameters to ensure the consistency and applicability of the data.
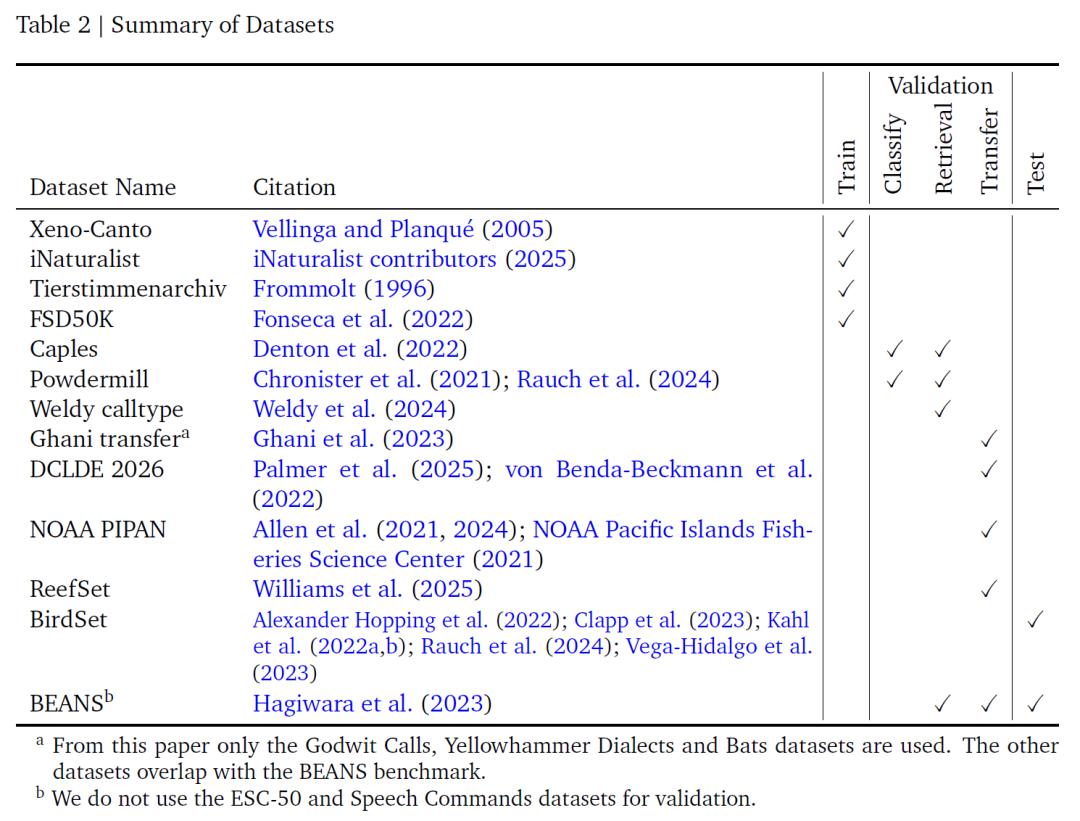
Dataset summary
Considering that the recording durations of different data sources vary greatly (ranging from less than 1 second to more than 1 hour, with most being between 5 - 150 seconds), and the model takes a 5 - second segment as input by default, the research team designed two window selection strategies: The random window strategy randomly selects a 5 - second segment when a certain recording is selected. Although it may include segments where the target species does not vocalize, bringing some label noise, the overall noise level is within an acceptable range. The energy peak strategy follows the idea of Perch 1.0, selecting the 6 - second region with the strongest energy in the recording through wavelet transform and then randomly selecting a 5 - second segment from it. Based on the assumption that "high - energy regions are more likely to contain the target species' sounds", this method is consistent with the detector design logic of models such as BirdNET and can more accurately capture effective acoustic signals. This method can more accurately capture effective acoustic signals.
To further improve the model's adaptability to complex acoustic environments, the research team adopted a variant of the mixup data augmentation method, generating composite signals by mixing multiple audio windows: First, the number of audio segments to be mixed is determined by sampling from the Beta - binomial distribution. Then, the weights are sampled from the symmetric Dirichlet distribution, and the selected multiple signals are weighted and summed, followed by gain normalization.
Different from the original mixup, this method uses the weighted average of multi - hot target vectors instead of one - hot vectors, ensuring that all vocalizations (regardless of their loudness) within the window can be identified with high confidence. The relevant parameters are tuned as hyperparameters, which can enhance the model's ability to distinguish overlapping sounds and improve the classification accuracy.
Model evaluation is carried out based on two authoritative benchmarks, BirdSet and BEANS. BirdSet contains 6 fully - annotated soundscape datasets from the United States mainland, Hawaii, Peru, and Colombia. During evaluation, no fine - tuning is performed, and the output of the prototype learning classifier is directly used. BEANS covers 12 cross - taxa test tasks (involving birds, terrestrial and marine mammals, anurans, and insects). Only its training set is used to train linear and prototype probes, and the embedding network is not adjusted either.
Perch 2.0: A High - Performance Bioacoustic Pre - trained Model
The model architecture of Perch 2.0 consists of a frontend, an embedding network, and a set of output heads, and each part works together to achieve the complete process from audio signals to species recognition.
Among them, the frontend is responsible for converting the original audio into a feature form that the model can process. It receives single - channel audio sampled at 32kHz. For a 5 - second long segment (containing 160,000 sampling points), through a 20ms window length and 10ms hop length processing, a log - mel spectrogram containing 500 frames with 128 mel bands per frame is generated, covering a frequency range from 60Hz to 16kHz, providing basic features for subsequent analysis.
The embedding network uses the EfficientNet - B3 architecture - a convolutional residual network with 120 million parameters. It maximizes parameter efficiency through the depth - separable convolution design. Compared with the 78 million - parameter EfficientNet - B1 used in the previous version of Perch, it is larger in scale to match the increase in training data volume.
After being processed by the embedding network, a spatial embedding with a shape of (5, 3, 1536) (the dimensions correspond to time, frequency, and feature channels respectively) is obtained. By taking the mean of the spatial dimensions, a 1536 - dimensional global embedding is obtained, which serves as the core feature for subsequent classification.
The output heads undertake specific prediction and learning tasks and consist of 3 parts: The linear classifier projects the global embedding into a 14,795 - dimensional category space. Through training, it makes the embeddings of different species linearly separable, improving the linear probing effect when adapting to new tasks later. The prototype learning classifier takes the spatial embedding as input and learns 4 prototypes for each category, making predictions based on the maximum activation of the prototypes. This design is derived from the AudioProtoPNet in the field of bioacoustics. The source prediction head is a linear classifier that predicts the original recording source of the audio segment based on the global embedding. Since the training set contains more than 1.5 million source recordings, it achieves efficient computation through a low - rank projection of rank 512 for the learning of self - supervised source prediction loss.
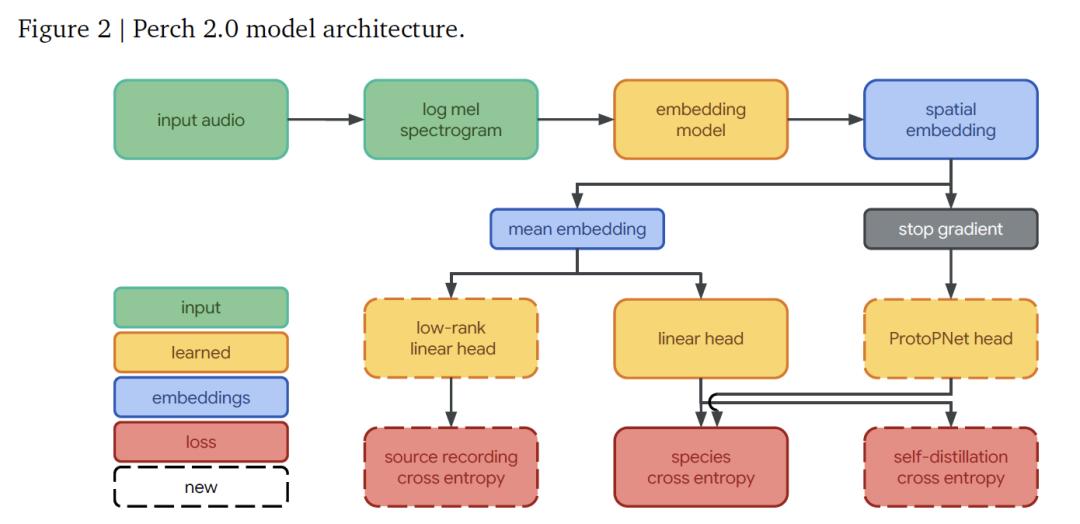
Perch 2.0 model architecture
The model training achieves end - to - end optimization through 3 independent objectives:
* The species classification cross - entropy is applied to the linear classifier, using softmax activation and cross - entropy loss, and assigning uniform weights to the target categories.
* In the self - distillation mechanism, the prototype learning classifier acts as the "teacher", and its prediction results guide the "student" linear classifier. At the same time, the orthogonal loss is used to maximize the difference between prototypes, and the gradients are not back - propagated to the embedding network.
* Source prediction is a self - supervised objective. The original recordings are regarded as independent categories for training, prompting the model to capture significant features.
The training is divided into two stages: The first stage focuses on training the prototype learning classifier (without starting self - distillation, with a maximum of 300,000 steps). The second stage starts self - distillation (with a maximum of 400,000 steps), and the Adam optimizer is used in both stages.
Hyperparameter selection relies on the Vizier algorithm. In the first stage, the learning rate, dropout rate, etc. are searched, and the optimal model is determined through two rounds of screening. In the second stage, the search continues with the addition of the self - distillation loss weight. Both window sampling methods are used throughout the process.
The results show that in the first stage, mixing 2 - 5 signals is preferred, and the source prediction loss weight ranges from 0.1 to 0.9. In the self - distillation stage, a small learning rate and less use of mixup are preferred, and a high weight of 1.5 - 4.5 is assigned to the self - distillation loss. These parameters support the model's performance.
Evaluation of Perch 2.0's Generalization Ability: Benchmark Performance and Practical Value
The evaluation of Perch 2.0 focuses on its generalization ability, examining its performance in bird soundscapes (which are significantly different from the training recordings) and non - species recognition tasks (such as call type recognition), as well as testing its transfer ability to non - avian taxa such as bats and marine mammals. Considering that practitioners often need to process small - scale or unlabeled data, the core principle of the evaluation is to verify the effectiveness of the "frozen embedding network", that is, quickly adapting to new tasks such as clustering and few - shot learning by extracting features once.
The practicality of the model is verified from 3 aspects during the model selection stage:
* The performance of the pre - trained classifier is evaluated by ROC - AUC on the fully - annotated bird dataset to assess its "out - of - the - box" species prediction ability.
* One - shot sample retrieval measures the clustering and search performance using cosine distance.
* Linear transfer simulates the few - shot scenario to test the adaptation ability.
The scores of these tasks are calculated using the geometric mean, and the results of 19 sub - datasets ultimately reflect the model's real - world usability.
Based on the two authoritative benchmarks, BirdSet and BEANS, the evaluation results of this study are shown in the following table. Perch 2.0 performs outstandingly in multiple indicators, especially achieving the current best ROC - AUC, without the need for fine - tuning. The performance of its random window and energy peak window training strategies is similar, presumably because self - distillation alleviates the impact of label noise.
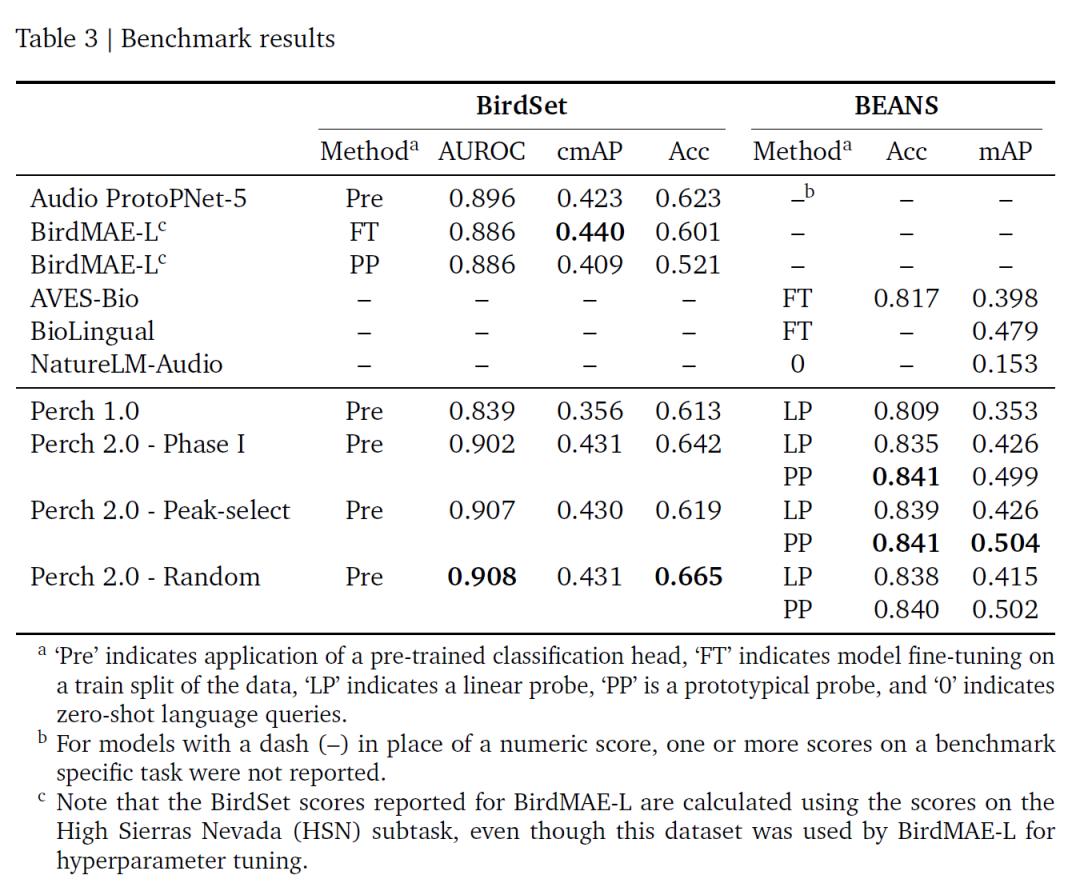
Benchmark test results
Overall, Perch 2.0 is centered around supervised learning and is closely related to the characteristics of bioacoustics. The breakthrough of Perch 2.0 shows that high - quality transfer learning does not need to rely on extremely large models. A well - tuned supervised model combined with data augmentation and auxiliary objectives can perform excellently. Its fixed - embedding design (without the need for repeated fine - tuning) reduces the cost of large - scale data processing and makes agile modeling possible. In the future, building practical evaluation benchmarks, developing new tasks using metadata, and exploring semi - supervised learning will be important directions in this field.
The Convergence of Bioacoustics and Artificial Intelligence
In the cross - field of bioacoustics and artificial intelligence, research directions such as cross - taxa transfer learning, self - supervised objective design, and optimization of fixed embedding networks have attracted extensive exploration from the global academic and industrial communities.
The Cosine Distance Virtual Adversarial Training (CD - VAT) technology developed by a team from the University of Cambridge improves the discriminability of acoustic embeddings through consistency regularization. In the large - scale speaker verification task, it recovers a 32.5% improvement in the equal error rate, providing a new paradigm for semi - supervised learning in speech recognition.
In the sperm whale vocalization research jointly conducted by the Massachusetts Institute of Technology and CETI, a "pronunciation alphabet" containing rhythm, prosody, tremors, and ornaments is separated through machine learning, revealing that the complexity of their communication system far exceeds expectations. There are at least 143 distinguishable vocal combinations in the sperm whale clan in the Eastern Caribbean alone, and its information - carrying capacity even exceeds the basic structure of human language.
The photoacoustic imaging technology developed by the Swiss Federal Institute of Technology in Zurich breaks through the acoustic diffraction limit through microcapsules loaded with iron oxide nanoparticles. It achieves super - resolution imaging of deep - tissue microvessels (with a resolution of 20 microns), showing the potential for multi - parameter dynamic monitoring in brain science and tumor research.
Meanwhile, the open - source project BirdNET, with the accumulation of 150 million recordings globally, has become a benchmark tool for ecological monitoring. Its lightweight version, BirdNET - Lite, can run in real - time on edge devices such as the Raspberry Pi, supporting the recognition of more than 6,000 bird species and providing a low - cost solution for biodiversity research.
The AI bird song recognition system deployed by the Japanese company Hylable in Hibiya Park combines a multi - microphone array with a deep neural network. It can simultaneously output the sound source location and species identification, with an accuracy rate of over 95%. Its technical framework has been extended to the fields of urban green space ecological assessment and barrier - free facility construction.
Notably, Google DeepMind's Project Zoonomia is exploring the evolutionary mechanism of cross - species acoustic commonalities by integrating the genomic and acoustic data of 240 mammalian species. The research finds that the harmonic energy distribution of dogs' happy barks (the energy ratio of the 3rd - 5th harmonics is 0.78±0.12) is highly homologous to that of dolphins' social whistles (0.81±0.09). This molecular - biological correlation not only provides a basis for cross - species model transfer but also inspires a new modeling path of "biologically - inspired AI" - integrating evolutionary tree information into the training of the embedding network to break through the limitations