Qwen 3 is released, and Alibaba has once again ignited the bonfire of AI open source.
Text by | Deng Yongyi
Edited by | Su Jianxun
On April 28th, practitioners in the AI circle were all waiting for one thing: Qwen 3.
Since noon, rumors about the upcoming release of Qwen 3 have been flying everywhere. Lin Junyang, the person in charge of the Qwen team, also hinted on X: "Let's see if we can finish the work on Qwen 3 tonight."

Source: X (Twitter)
In multiple industry discussion groups where "Intelligent Emergence" is involved, there are screenshots of the alleged Qwen 3 model uploads of unknown authenticity. AI practitioners frantically refreshed the Qwen pages on GitHub and HuggingFace, used AI to generate posters for the Qwen 3 launch and simulated on - site pictures, and flooded the chat with various emojis. The excitement lasted until late at night.
Qwen 3 was finally launched at 5 a.m. The new - generation Qwen 3 has only one - third of the parameter count of DeepSeek - R1. Firstly, the cost has been significantly reduced, and its performance comprehensively surpasses that of global top - tier models such as R1 and OpenAI - o1.
More importantly, Qwen 3 is equipped with a hybrid inference mechanism similar to top - tier models like Claude 3.7, integrating "fast thinking" and "slow thinking" into the same model, which greatly reduces computing power consumption.
The open - sourcing of Qwen 3 involves a total of 8 models with different architectures and sizes, ranging from 0.6B to 235B, which are suitable for more types of mobile devices. In addition to the models, Qwen also launched a native framework for Agents, supporting the MCP protocol, with an ambition to "let everyone use Agents".
In January after the explosion of DeepSeek, on the eve of Chinese New Year's Eve, Alibaba quickly launched new models Qwen2.5 - VL and Qwen2.5 - Max. While showing off its strength, it also gave Alibaba Group a stronger "AI flavor". Driven by this sentiment, Alibaba's stock price soared by more than 30% around the Spring Festival.
However, compared with the flagship model Qwen 3 this time, the above - mentioned models are just a prelude.
The high expectations for Qwen 3 come from Alibaba's high reputation in the AI open - source community. Now, Qwen is already a globally leading open - source model series. According to the latest data, Alibaba Tongyi has open - sourced more than 200 models, with a global download volume of over 300 million times and more than 100,000 derivative models of Qianwen, surpassing the previous open - source leader Llama.
If DeepSeek is an elite small team charging forward rapidly in technology, then Qwen is an army. It started the layout of large models earlier and is more active in building an ecosystem, showing broader coverage and community vitality.
To some extent, Qwen is also an industrial indicator for the implementation of large models.
A typical example is that after the release of DeepSeek R1, many enterprises and individuals wanted to privately deploy the "full - blooded version" of DeepSeek (671B), but the hardware cost alone would be over one million yuan, resulting in high implementation costs.
The Alibaba Qwen family offers more model sizes and categories, which can help the industrial circle verify the implementation value more quickly. In plain language, developers don't need to trim the models themselves but can use them directly and then implement them quickly. Models of Qwen 13B and below have strong controllability and are indeed one of the most popular models in the current AI application field.
DeepSeek R1 has become an anchor point in the history of open - source models and has deeply influenced the direction of large - model competition. Different from previous model manufacturers who were obsessed with improving Benchmark scores and solving problems, Chinese tech giants are now in a period where they must prove their real technological strength.
The release of Qwen 3 is such a moment.
The full - blooded version costs one - third of DeepSeek R1 and has more powerful performance
In September 2024, Alibaba Cloud released the previous - generation model Qwen 2.5 at the Yunqi Conference. Qwen2.5 open - sourced a full - series of 6 models ranging from 0.5B to 72B at once, covering all - scenario requirements from the edge to the cloud. In many categories such as code, it can reach the SOTA level.
All models allow commercial use and secondary development, which is also called "truly open AI" by developers.
There were rumors in the market that the new - generation Qwen 3 would be based on the MoE architecture, open - source more sizes, and have a lower cost than DeepSeek. All these speculations have been confirmed one by one.
Qwen 3 has open - sourced a total of 8 models of different sizes, namely:
- Weights of two MoE (Mixture of Experts) models (referring to the decision - making preferences of the models): 30B (30 billion) and 235B (235 billion) parameters
- Six Dense models: including 0.6B (600 million), 1.7B (1.7 billion), 4B (4 billion), 8B (8 billion), 14B (14 billion), and 32B (32 billion)
Each model has reached the SOTA (best performance) among open - source models of the same size.
Qwen 3 continues Alibaba's generous open - source style and is still open - sourced under the lenient Apache2.0 protocol. It supports more than 119 languages for the first time, allowing global developers, research institutions, and enterprises to download the models for free and use them commercially.
The biggest highlight of Qwen 3 is that the cost is significantly reduced while the performance is greatly improved.
Alibaba invested a staggering amount in the training of Qwen 3. Qwen 3 was pre - trained on 36 trillion tokens, which is twice that of the previous - generation model Qwen 2.5 and ranks among the top in global top - tier models of the same scale.
According to the data publicly released by the Qwen team, only 4 H20 GPUs are needed to deploy the full - blooded version of Qwen 3, and the video memory usage is only one - third of that of models with similar performance.
The cost is reduced, but the performance is even higher.
The inference ability of Qwen has been significantly improved. In terms of mathematics, code generation, and common - sense logical reasoning, Qwen 3 surpasses the previous inference models QwQ (thinking mode) and Qwen2.5 model (non - thinking mode).
In benchmark tests such as code, mathematics, and general abilities, Qwen 3 can also compete with current top - tier models such as o3 - mini, Grok - 3, and Gemini - 2.5 - Pro.
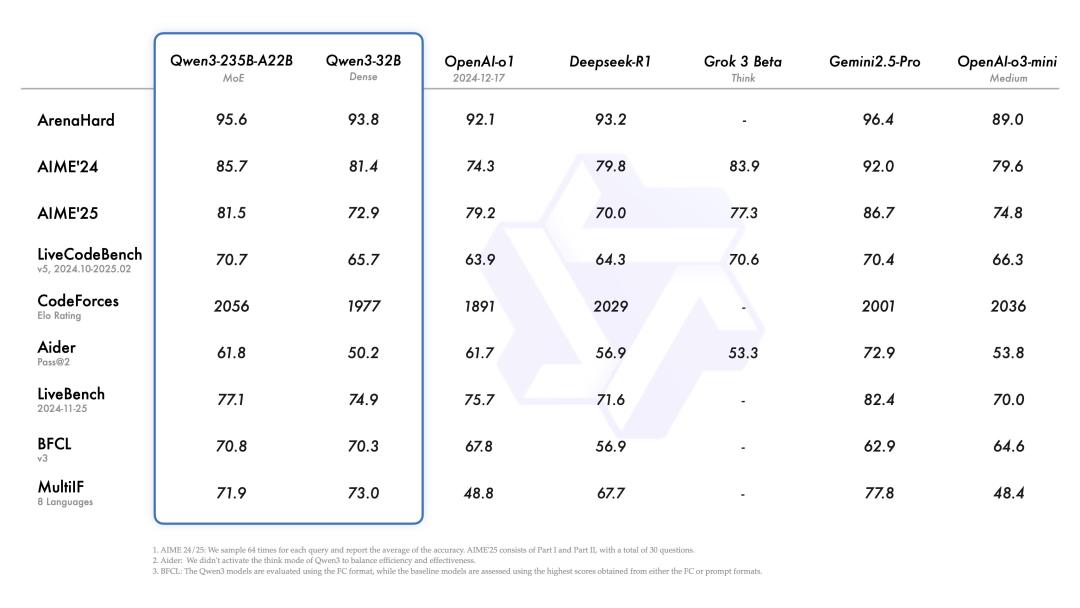
△Qwen 3 performance chart. Source: Qwen 3
Another core highlight is the full adaptation of the Qwen model to Agents.
If OpenAI's o1 model kicked open the door to inference models, the release of DeepSeek R1 let all users experience the magic of inference models: the model has a "thinking chain" like a human, with a thinking sequence, constantly verifying whether it is correct, and deducing appropriate answers.
However, if there is only a deep - thinking mode, the drawbacks are also obvious. Even when asking simple questions such as the weather or what to wear today, DeepSeek will keep struggling, self - questioning, and constantly verifying, going through excessive thinking that lasts at least dozens of seconds. If DeepSeek does not show the thinking chain of the model to users, almost no user can tolerate such a delayed dialogue experience.
Alibaba CEO Wu Yongming once said at the Yunqi Conference in September 2024: "The greatest imagination of AI lies not in the mobile phone screen but in taking over the digital world and changing the physical world."
Agents are an important path to this vision. Therefore, it is quite crucial for Qwen3 to be a hybrid inference model: within a single model, it can seamlessly switch between the thinking mode (for complex logical reasoning, mathematics, and coding) and the non - thinking mode (for efficient general conversations, such as simple information searches like asking about the weather or historical knowledge).
The ability to integrate reasoning and non - reasoning tasks actually enables the model to:
- Understand the digital world, which mainly emphasizes non - reasoning abilities such as recognition, retrieval, and classification;
- Operate the digital world, which mainly emphasizes reasoning abilities. The model can autonomously plan, make decisions, and program, with typical applications such as Manus.
The API of Qwen 3 can set the "thinking budget" (i.e., the expected maximum number of tokens for deep thinking) as needed to perform different degrees of thinking, ensuring optimal performance in various scenarios.
In the previous mechanism, users needed to manually switch the "deep - thinking" mode, and they could only focus on one mode in a single dialogue. However, the new mechanism of Qwen 3 leaves this choice to the model. The model can automatically identify the task scenario and select the thinking mode, reducing the user's intervention cost in the model mode and bringing a smoother product experience.
Hybrid inference is a relatively difficult technical direction at present, requiring extremely delicate and innovative design and training, which is much more difficult than training a pure inference model. The model needs to learn two different output distributions, achieve the integration of the two modes, and basically not affect the effect in either mode.
Among popular models, currently only Qwen 3, Claude3.7, and Gemini 2.5 Flash can achieve good hybrid inference.
Hybrid inference will overall improve the cost - performance ratio of model use, not only enhancing the intelligence level but also reducing the overall consumption of computing resources. For example, the price difference between the reasoning and non - reasoning modes of Gemini - 2.5 - Flash is about 6 times.
To enable everyone to start developing Agents immediately, the Qwen team has almost provided a nanny - style toolbox:
- The recently popular MCP protocol of Qwen 3, which has the ability of function calling, both of which are the main frameworks of Agents;
- The native Qwen - Agent framework, which encapsulates the function - calling template and the function - calling parser;
- The API service has also been launched simultaneously, and enterprises can directly call it through Alibaba Cloud Bailian.
If we use home decoration as an example, it's like the Qwen team has built the house, completed the hard - decoration, and also provided some soft - decoration. Developers can directly use many services. This will greatly reduce the coding complexity and further lower the development threshold. For example, many tasks such as mobile phone and computer Agent operations can be efficiently implemented.
The open - source model has entered a new round of competition cycle
After DeepSeek R1 gained explosive popularity and became the benchmark for global open - source models, the release of models is no longer just a simple product update but represents the key strategic direction of the company.
The release of Qwen 3 came after DeepSeek R1, and a new round of competition between open - source and closed - source models has begun. In April 2025, Meta's open - source model Llama 4 was officially released at the beginning of April but was criticized for its poor performance. Google, an AI giant that had suffered setbacks before, also made a comeback with Gemini 2.5 pro.
The capabilities of the general large - model layer are still changing rapidly, and it is difficult for any manufacturer to maintain a leading position all the time. At this point, how large - model teams determine their development mainlines is not only a technical issue but also a strategic issue regarding different product routes and business judgments.
In the release of Qwen 3, a more practical open - source strategy can be seen.
For example, the model sizes proposed by Qwen3 this time are more detailed than those of Qwen 2.5. Qwen 3 can run efficiently on resource - constrained devices (such as mobile devices and edge - computing devices) while ensuring a certain level of performance to meet the needs of lightweight inference and conversations.
Alibaba carefully explained the applicable scenarios of each model:
- The smallest parameter models (such as 0.6B and 1.7B): Support developers to use them as experimental models for speculative decoding, which is very friendly to scientific research;
- The 4B model: Recommended for mobile - side applications;
- The 8B model: Recommended for computer or automotive - side applications;
- The 14B model: Suitable for implementation applications, and ordinary developers can handle it with a few GPUs;
- The 32B model: The most popular model size among developers and enterprises, supporting large - scale commercial deployment by enterprises.
In terms of the flagship model, the model scale and architecture of Qwen 3 are also a more refined and easier - to - implement design.
Let's directly compare the Qwen flagship model 235B (23.5 billion parameters) with the full - blooded version of DeepSeek R1:
- Qwen 3 235B uses a medium - scale (235B) and efficient activation design (22B activation, about 9.4%), and only 4 H20 GPUs are needed for deployment;
- DeepSeek - R1 pursues a super - large scale (671B) and sparse activation (37B activation, about 5.5%), and a 16 - card H20 configuration is recommended, costing about 2 million yuan.
In terms of deployment cost, Qwen 3 is 25% - 35% of the full - blooded version of R1, and the model deployment cost is reduced by 60% - 70%.
After DeepSeek R1, if there is any consensus in the large - model field, it is to reinvest resources and manpower into technological breakthroughs at the model layer to let the model capabilities break through the upper limit of application capabilities.
Now, the large - model field has refocused on the breakthrough of model capabilities.
From the change in the release theme of Qwen, we can also see the change in the current technological mainline. When Qwen 2.5 was released, the theme was "Expanding the Boundaries of Large Language Models", while for Qwen 3, it is "Think Deep, Act Fast", focusing on improving the application performance of model capabilities and lowering the implementation threshold, rather than simply expanding the parameter scale.
Now, the global download volume of Tongyi Qianwen Qwen has exceeded 300 million. In the global model download volume on the HuggingFace community in 2024, Qwen accounts for more than 30%. Alibaba Cloud's model open - source strategy has blazed a clearer path: truly becoming the soil for applications.

Welcome to communicate
