Qwen 3 ist veröffentlicht, und Alibaba hat erneut das Lagerfeuer der Open-Source-Künstlichen Intelligenz entzündet.
Text | Deng Yongyi
Redaktion | Su Jianxun
Am 28. April warteten alle Fachleute im Bereich Künstliche Intelligenz auf eine Ankündigung: Qwen 3.
Ab Mittag verbreiteten sich schon Gerüchte über die baldige Veröffentlichung von Qwen 3. Lin Junyang, Leiter des Qwen - Teams, hat auch auf X (früher Twitter) angedeutet: „Mal sehen, ob wir heute Abend die Arbeit an Qwen 3 abschließen können.“

Quelle: X (Twitter)
In mehreren Branchen - Diskussionsgruppen von „Intelligentes Auftauchen“ kursierten Screenshots über das Hochladen des Qwen 3 - Modells, deren Echtheit nicht klar war. KI - Fachleute haben wild die Qwen - Seiten auf GitHub und HuggingFace aktualisiert, mit KI Poster für den Start von Qwen 3 und Simulationsbilder der Veranstaltung erstellt und mit Emojis die Gruppen überschwemmt. Die Feierlichkeiten hielten bis in die späte Nacht an.
Qwen 3 wurde schließlich um 5 Uhr morgens online gestellt. Die neue Generation von Qwen 3 hat nur ein Drittel der Parameter von DeepSeek - R1. Dadurch sinkt zunächst die Kosten erheblich, und die Leistung übertrifft alle Weltspitzenmodelle wie R1 und OpenAI - o1.
Was noch wichtiger ist, Qwen 3 ist mit einem gemischten Inferenzmechanismus wie dem von Claude 3.7 ausgestattet. Es integriert „schnelles Denken“ und „langsames Denken“ in ein einziges Modell, was den Rechenleistungsbedarf erheblich reduziert.
Die Open - Source - Veröffentlichung von Qwen 3 umfasst insgesamt 8 Modelle mit unterschiedlicher Architektur und Größe, von 0,6 Milliarden bis hin zu 235 Milliarden Parametern, die für mehr Arten von Mobilgeräten geeignet sind. Neben den Modellen hat Qwen auch einen nativen Rahmen für Agenten eingeführt, der das MCP - Protokoll unterstützt, was den Eindruck vermittelt, dass „jeder Agenten nutzen soll“.
Im Januar, kurz vor Neujahr nach chinesischer Zeit, nachdem DeepSeek auf der Weltbühne aufgetaucht war, hat Alibaba schnell die neuen Modelle Qwen2.5 - VL und Qwen2.5 - Max online gestellt. Dies hat nicht nur Alibabas Stärke in der KI - Branche demonstriert, sondern auch die Aktienkurse von Alibaba um über 30 % in der Zeit um das chinesische Neujahr gestiegen.
Im Vergleich zu Qwen 3, dem Flaggschiffmodell dieser Veröffentlichung, waren die obigen Modelle nur der Auftakt.
Die hohe Erwartung an Qwen 3 rührt von Alibabas guten Ruf in der Open - Source - KI - Community. Qwen ist heute eine weltweit führende Open - Source - Modellreihe. Laut neuesten Daten hat Alibaba über 200 Modelle open - source veröffentlicht, die weltweit über 300 Millionen Mal heruntergeladen wurden. Die Anzahl der abgeleiteten Qwen - Modelle beträgt über 100.000, was die vorherige Open - Source - Nummer eins, Llama, übertrifft.
Wenn man DeepSeek als eine elite Truppenkompanie ansieht, die schnell voranschreitet, dann ist Qwen eine ganze Armee. Qwen hat früher mit der Planung von großen Modellen begonnen und ist aktiver in der Ökosystementwicklung, was eine breitere Abdeckung und eine lebendigere Community zeigt.
In gewisser Weise ist Qwen auch ein Industriewindfahne für die Umsetzung von großen Modellen.
Ein typisches Beispiel: Nach der Veröffentlichung von DeepSeek R1 wollten viele Unternehmen und Privatpersonen die „voll ausgestattete Version“ von DeepSeek (671 Milliarden Parameter) privat einsetzen. Die Hardwarekosten allein beliefen sich auf über eine Million Yuan, was die Umsetzung sehr teuer macht.
Die Qwen - Familie von Alibaba bietet mehr Modellgrößen und - klassen, die die Branche bei der schnelleren Validierung der Umsetzungswert helfen. Einfach ausgedrückt, können Entwickler die Modelle direkt nutzen, ohne sie selbst anpassen zu müssen, und so schnell umsetzen. Die Modelle von Qwen 13 Milliarden Parametern und weniger sind gut steuerbar und gehören heute zu den beliebtesten Modellen in der KI - Anwendungsbranche.
DeepSeek R1 ist ein Meilenstein in der Geschichte der Open - Source - Modelle und hat auch die Richtung des Wettbewerbs um große Modelle stark beeinflusst. Anders als zuvor, als sich die Modellhersteller auf Benchmark - Tests und Aufgaben konzentrierten, müssen die großen chinesischen Unternehmen nun ihre echte technische Stärke beweisen.
Die Veröffentlichung von Qwen 3 ist genau ein solcher Zeitpunkt.
Die Kosten der voll ausgestatteten Version betragen ein Drittel von DeepSeek R1, die Leistung ist jedoch stärker
Im September 2024 hat Alibaba Cloud auf der Yunqi - Konferenz das Vorgängermodell Qwen 2.5 veröffentlicht. Qwen2.5 hat auf einmal sechs Modelle von 0,5 Milliarden bis 72 Milliarden Parametern open - source veröffentlicht, die alle Anwendungsfälle von Endgeräten bis hin zu Cloud - Umgebungen abdecken und in vielen Kategorien wie Code die beste Leistung (SOTA) erzielen.
Alle Modelle dürfen kommerziell genutzt und weiterentwickelt werden, was von den Entwicklern als „wirklich offene KI“ bezeichnet wird.
Es ging in der Branche die Gerüchte, dass die neue Generation von Qwen 3 auf der MoE - Architektur basieren würde, mehr Modellgrößen open - source veröffentlichen würde und die Kosten niedriger als bei DeepSeek wären. All diese Vermutungen wurden bestätigt.
Qwen 3 hat insgesamt acht Modelle in verschiedenen Größen open - source veröffentlicht:
- Die Gewichte (die Entscheidungspräferenzen des Modells) von zwei MoE (Mixture of Experts) - Modellen: 30 Milliarden und 235 Milliarden Parameter
- Sechs Dense - Modelle: 0,6 Milliarden, 1,7 Milliarden, 4 Milliarden, 8 Milliarden, 14 Milliarden und 32 Milliarden Parameter
Jedes Modell hat die beste Leistung (SOTA) unter den Open - Source - Modellen gleicher Größe erreicht.
Qwen 3 setzt Alibabas großzügiges Open - Source - Konzept fort und wird weiterhin unter der freundlichen Apache2.0 - Lizenz veröffentlicht. Es unterstützt erstmals über 119 Sprachen, und globale Entwickler, Forschungsinstitute und Unternehmen können die Modelle kostenlos herunterladen und kommerziell nutzen.
Der größte Vorteil von Qwen 3 ist, dass die Kosten stark sinken, während die Leistung zugleich stark steigt.
Für das Training von Qwen 3 hat Alibaba enorme Kosten aufgebracht. Qwen 3 wurde auf 36 Billionen Tokens vortrainiert, was doppelt so viel wie beim Vorgängermodell Qwen 2.5 ist und auch unter den Weltspitzenmodellen gleicher Größe an der Spitze steht.
Laut offizielle Daten des Qwen - Teams kann die voll ausgestattete Version von Qwen 3 mit nur vier H20 - Grafikkarten deployed werden, und der Grafikspeicherbedarf beträgt nur ein Drittel von vergleichbaren Modellen.
Die Kosten sinken, die Leistung steigt jedoch.
Die Inferenzfähigkeit von Qwen hat sich erheblich verbessert. In Bereichen wie Mathematik, Codegenerierung und logischem Schlussfolgern hat Qwen 3 sowohl das vorherige Inferenzmodell QwQ (Denkmodus) als auch das Qwen2.5 - Modell (nicht - Denkmodus) übertroffen.
In Benchmark - Tests wie Code, Mathematik und allgemeinen Fähigkeiten kann Qwen 3 auch mit den aktuellen Weltspitzenmodellen wie o3 - mini, Grok - 3 und Gemini - 2.5 - Pro mithalten.
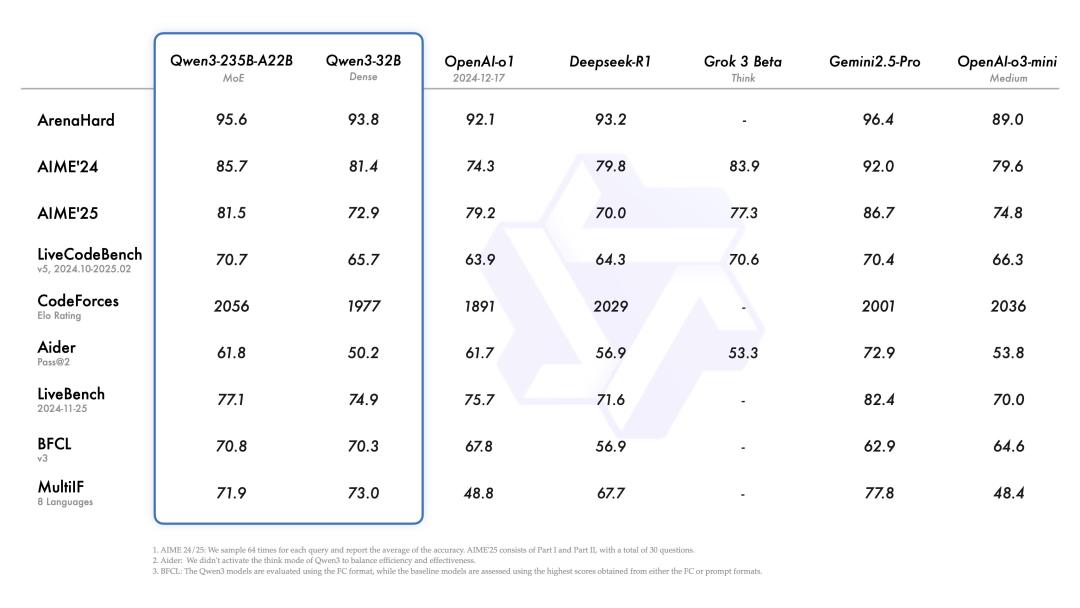
△Leistungsdiagramm von Qwen 3. Quelle: Qwen 3
Ein weiterer Kernpunkt ist die vollständige Anpassung des Qwen - Modells an Agenten.
Wenn man sagt, dass das o1 - Modell von OpenAI die Tür zu Inferenzmodellen geöffnet hat, dann hat die Veröffentlichung von DeepSeek R1 den Nutzern die Magie von Inferenzmodellen gezeigt: Das Modell hat eine „Denkkette“ wie ein Mensch, eine Denkordnung und prüft ständig, ob die Antwort richtig ist, um schließlich eine geeignete Antwort zu finden.
Aber wenn es nur den tiefen Denkmodus gibt, sind die Nachteile auch offensichtlich. Selbst wenn man einfache Fragen wie das Wetter oder was man anziehen soll stellt, denkt DeepSeek ständig nach, stellt sich selbst Fragen und prüft ständig, was zu einer Überlegung von mindestens mehreren zehn Sekunden führt. Wenn DeepSeek die Denkkette des Modells nicht dem Nutzer zeigt, kann kaum ein Nutzer eine solche verzögerte Dialogerfahrung ertragen.
Wu Yongming, CEO von Alibaba, hat auf der Yunqi - Konferenz im September 2024 gesagt: „Die größte Vorstellungskraft der KI liegt nicht auf dem Handybildschirm, sondern darin, die digitale Welt zu übernehmen und die physische Welt zu verändern.“
Agenten sind ein wichtiger Weg, um dieses Ziel zu erreichen. Deshalb ist es sehr wichtig, dass Qwen3 ein gemischtes Inferenzmodell ist: Innerhalb eines einzigen Modells kann man nahtlos zwischen dem Denkmodus (für komplexe logische Schlussfolgerungen, Mathematik und Programmierung) und dem Nicht - Denkmodus (für effiziente allgemeine Gespräche, wie das Abfragen von Wetterinformationen oder historischen Fakten) wechseln.
Die Fähigkeit, Inferenz - und Nicht - Inferenzaufgaben zu kombinieren, ermöglicht es dem Modell:
- Die digitale Welt zu verstehen, was eher auf Nicht - Inferenzfähigkeiten wie Erkennung, Suche und Klassifizierung abzielt.
- Die digitale Welt zu manipulieren, was eher auf Inferenzfähigkeiten wie eigenständige Planung, Entscheidung und Programmierung abzielt, wie in der typischen Anwendung Manus.
Die API von Qwen 3 kann den „Denkbudget“ (d. h. die erwartete maximale Anzahl von Tokens für tiefes Denken) nach Bedarf einstellen, um unterschiedliche Grade des Denkens zu ermöglichen und sicherzustellen, dass es in allen Szenarien die beste Leistung erzielt.
In der alten Mechanik musste der Nutzer den „tiefen Denkmodus“ manuell ein - und ausschalten, und in einem Gespräch konnte man sich möglicherweise nur auf einen Modus konzentrieren. Aber die neue Mechanik von Qwen 3 überlässt diese Entscheidung dem Modell. Das Modell kann automatisch die Aufgabe und das Szenario erkennen und den Denkmodus auswählen, was die Interventionskosten des Nutzers für den Modellmodus reduziert und eine reibungslosere Produktumgebung bietet.
Das gemischte Inferenz ist derzeit ein schwieriger technischer Bereich, der eine äußerst feine und innovative Gestaltung und Training erfordert. Die Schwierigkeit ist weit höher als beim Training eines reinen Inferenzmodells. Das Modell muss zwei unterschiedliche Ausgabeverteilungen lernen und die beiden Modi integrieren, ohne die Leistung in einem der Modi zu beeinträchtigen.
Unter den beliebten Modellen können derzeit nur Qwen 3, Claude3.7 und Gemini 2.5 Flash ein gutes gemischtes Inferenz leisten.
Das gemischte Inferenz verbessert die Kosteneffizienz der Modellnutzung insgesamt, erhöht die Intelligenz und reduziert den Rechenleistungsbedarf. Beispielsweise beträgt der Preisunterschied zwischen dem Inferenz - und Nicht - Inferenzmodus von Gemini - 2.5 - Flash etwa das Sechsfache.
Um es allen zu ermöglichen, sofort Agenten zu entwickeln, hat das Qwen - Team fast einen umfassenden Toolkit bereitgestellt:
- Das beliebte MCP - Protokoll von Qwen 3, das die Fähigkeit zur Funktionsaufrufung hat, beide sind die Hauptrahmen für Agenten.
- Der native Qwen - Agent - Rahmen, der die Vorlagen und Parser für Funktionsaufrufe kapselt.
- Die API - Dienstleistung ist ebenfalls online, und Unternehmen können direkt über Alibaba Cloud Bai Lian darauf zugreifen.
Wenn man es mit der Wohnungseinrichtung vergleicht, ist es, als würde das Qwen - Team das Haus bauen, die Rohbauarbeiten erledigen und auch einen Teil der Einrichtung bieten. Entwickler können direkt viele Dienste nutzen. Dies wird die Codekomplexität erheblich reduzieren und die Entwicklungsbarriere senken. Beispielsweise können viele Aufgaben wie die Agentensteuerung auf Handys und Computern effizient umgesetzt werden.
Die Open - Source - Modelle treten in eine neue Wettbewerbsphase ein
Nachdem DeepSeek R1 weltweit Bekanntheit erlangt und zum Standard für Open - Source - Modelle geworden ist, ist die Veröffentlichung von Modellen nicht mehr einfach ein Produktupdate, sondern ein wichtiger Schritt in der Unternehmensstrategie.
Die Veröffentlichung von Qwen 3 erfolgte nach DeepSeek R1, und ein neuer Wettbewerb zwischen Open - Source - und Closed - Source - Modellen hat begonnen: Im April 2025 wurde das Open - Source - Modell Llama 4 von Meta Anfang April offiziell veröffentlicht, wurde aber wegen der schlechten Leistung stark kritisiert. Das AI - Gigant Google, das zuvor oft gescheitert war, hat mit Gemini 2.5 pro wieder einen Sieg errungen.
Die Fähigkeiten der allgemeinen großen Modelle ändern sich noch schnell, und es ist schwierig, dass ein Hersteller dauerhaft an der Spitze bleibt. An diesem Punkt ist es für die Teams hinter den großen Modellen, wie sie ihre Entwicklungspfade festlegen, nicht nur eine technische Frage, sondern auch eine strategische Entscheidung über verschiedene Produktpfade und kommerzielle Einschätzungen.
Bei der Veröffentlichung von Qwen 3 kann man eine praktischere Open - Source - Strategie erkennen.
Beispielsweise sind die Modellgrößen von Qwen3 feiner aufgeteilt als bei Qwen 2.5. Qwen 3 kann auf ressourcenbeschränkten Geräten (wie Mobilgeräten und Edge - Computing - Geräten) effizient laufen und gleichzeitig eine gewisse Leistung gewährleisten, um die Anforderungen an leichte Inferenz und Gespräche zu erfüllen.
Alibaba hat die Anwendungsfälle für jedes Modell genau erklärt:
- Die Modelle mit den geringsten Parametern (z. B. 0,6 Milliarden und 1,7 Milliarden): Unterstützen die Entwickler bei Experimenten mit speculative decoding (spekulative Dekodierung) und sind für die Forschung sehr geeignet.
- Das 4 - Milliarden - Parameter - Modell: Wird für Anwendungen auf Mobiltelefonen empfohlen.
- Das 8 - Milliarden - Parameter - Modell: Wird für Anwendungen auf Computern oder Autos empfohlen.
- Das 14 - Milliarden - Parameter - Modell: Eignet sich für die Umsetzung von Anwendungen. Selbst normale Entwickler können es mit wenigen Grafikkarten nutzen.