AI sent the first red envelope in human history.
Written by | Yongyi Deng
Edited by | Jianxun Su
On November 29, at the Open Day of Zhipu AI, the moment when the atmosphere reached its peak was undoubtedly when Zhipu CEO Peng Zhang raised his phone and said to the AI: Help me send a 20,000-yuan red envelope in the group chat of Zhipu Open Day, with 100 red envelopes, and the name is "The First Red Envelope Sent by AI".
Then, the AI quickly called up WeChat, opened the red envelope function, and successfully sent the red envelopes.
"AGI is not just a ChatBot, a language model, or just the number of model parameters," said Peng Zhang, CEO of Zhipu AI.

△Source: Zhipu AI
This also explains why, in 2024, the trend of Agent (Intelligent Agent) is becoming more and more popular - globally, including giants like Google, and in China, Baidu, Alibaba, ByteDance, etc., have all launched their own Agent products.
The industry generally believes that 2025 will be the year of the Agent explosion. Gartner recently listed agentic AI as one of the top ten technology trends in 2025, and predicts that at least 15% of daily work decisions will be autonomously completed by agentic AI in 2028, while this number was 0 in 2024.
Agent (Intelligent Agent) can be understood as an AI agent that helps humans complete some procedural software operations.
Peng Zhang summarized the essence of AI Agent in one sentence: "We are also constantly thinking about what the'sequential prediction' of the large model means and how to apply it efficiently in what form. What if the form of prediction is not limited to language text, but extends to image and video, or even operation sequences?"
Completing the operation sequence, or the task, is the essence of AutoGLM.
The form of AutoGLM is an assistant on the App, Web, and PC terminals. At today's conference, Zhipu officially released products corresponding to these three terminals:
AutoGLM can independently perform long-step operations of more than 50 steps and can also perform tasks across apps
AutoGLM,开启 a "fully automatic" new online experience, supporting unmanned driving on dozens of websites
GLM-PC, operating the computer like a human, officially started internal testing, and exploring the universal Agent based on the visual multi-modal model
A month ago, Zhipu had already released the internal test of AutoGLM, and in this month, more than 1 million users have visited. The Demo can already operate on apps such as WeChat, Taobao, Meituan, and Xiaohongshu, and can complete operations including sending red envelopes and using Alipay to order coffee on behalf of others, etc.
At today's conference, AutoGLM is even more powerful - the supported apps have added apps such as Douyin, Weibo, Jingdong, and Pinduoduo, and more importantly, it can complete cross-app and cross-terminal operations.
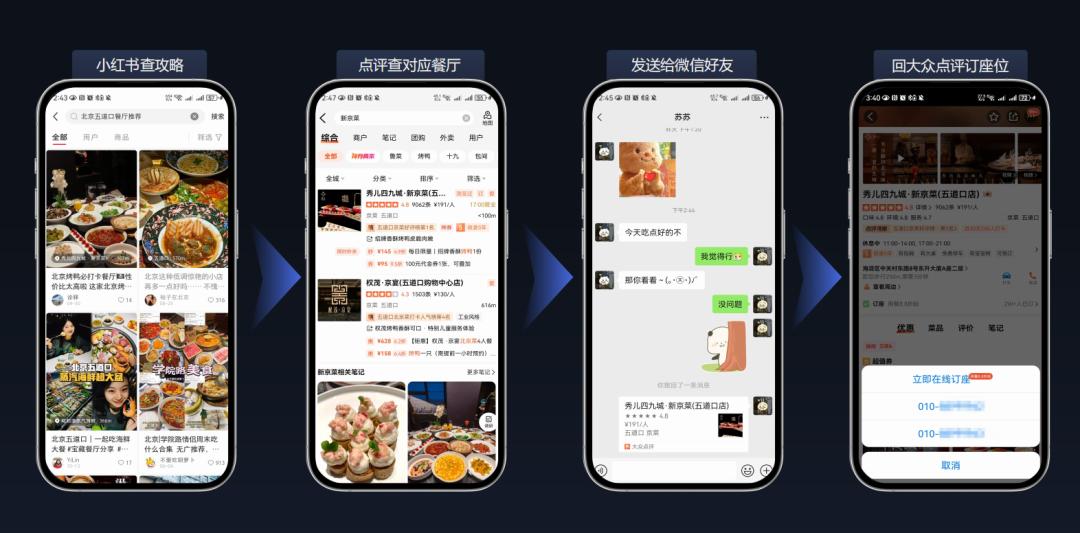
△Check the restaurant + Reservation scene Source: Zhipu AI
For example, in the on-site demo, the Zhipu Qingyan plugin automatically completed "Search for Mango TV, open Xiaoxiang Renjia, play the latest episode, and send a bullet comment to check in the ending". There was no human intervention throughout the process.
In another example of purchasing hot pot ingredients, AutoGLM independently performed 54 operations and was not interrupted in the middle. In multi-step and cyclic tasks, the speed performance of AutoGLM also exceeds manual operation.
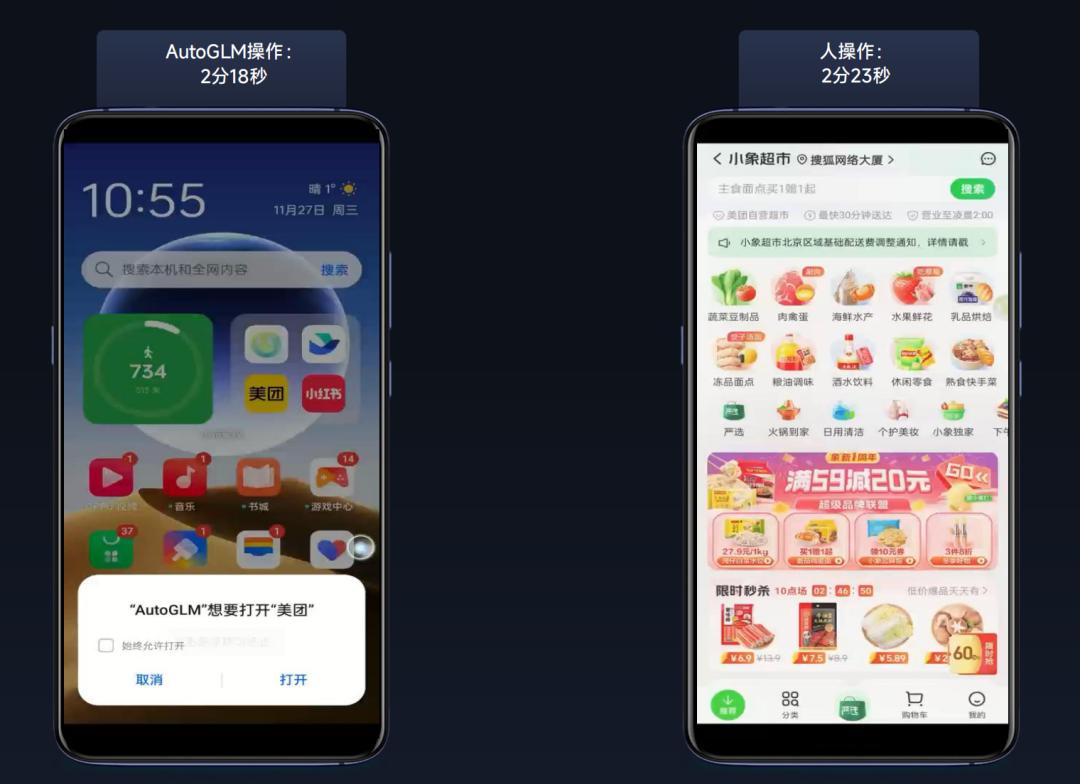
△Source: Zhipu AI
Peng Zhang also used his phone to call up Weibo, imitating human operations, opened the Weibo homepage of a celebrity, and left a text comment on a certain Weibo post - the AI also successfully completed this task.
On the PC, more daily work tasks can be completed, including helping users make and participate in meetings, sending meeting summaries; supporting document download, document sending, understanding and summarizing documents, etc.
△Source: Zhipu AutoGLM
In addition, it also supports cross-application information search and summarization - for example, searching for specified keywords on specified platforms (such as WeChat Official Accounts, Zhihu, Xiaohongshu, etc.) and completing reading and summarization.
It seems simple, but for the Agent to complete these operations, the operations and permissions involved are very complex. For example, there is a strict anti-crawler mechanism within WeChat. Once a robot is identified, it is very easy to be banned. It is even difficult to copy the content of posts on Xiaohongshu - the common operation in the past was that users first took a screenshot and then used other software to extract the text.
Agent is not a new technical term but has appeared decades ago.
The hope of having machines help humans complete software work has previously led to the exploration of completing procedural and repetitive work in various fields such as iPaaS, RPA (Robotic Process Automation, abbreviated as RPA), and even more traditional BPM (Business Process Management).
However, previous technologies would encounter multiple factors that affect the accuracy and feasibility, including inaccurate grasping of AI image elements and the low degree of openness of the Api of various software. But after the emergence of large models, these problems can be solved - large models can clearly understand what the software interface is pointing to, and will not have recognition errors due to slight changes in image elements.
Liu Xiao, the technical leader of AutoGLM, told "Intelligent Emergence" that AutoGLM is to operate on behalf of the user, relying on the "user-agreed interactive interface", and the essence is to simulate human operations for invocation - which is fundamentally different from the original api invocation and machine invocation.
There is no doubt that including embodied intelligence and Agent, they have been hot topics throughout 2024. Large model technology is moving out of the simple model layer and towards changing the interaction mode between machines and humans - based on understanding needs, planning and decision-making, executing actions, and self-reflection, to enable machines to better understand humans and thus better complete tasks.
This also reflects the recent Scaling Law discussion.
Scaling Law is an important law that drives the iteration of large models. In the two years after the emergence of ChatGPT, large model manufacturers generally focused on the pre-training model - feeding the model with more high-quality data to enable the emergence of intelligence after the model reaches a certain scale.
However, after OpenAI released the new model o1 in September this year, this means a shift in Scaling Law - from training models with larger scales and parameters to focusing on post-training, allowing the model to have more thinking time rather than more parameters, so that the model can think about more complex and difficult problems.

△ Source: Zhipu AI
Peng Zhang believes that the AutoGLM released today is only a "convergence" of the capabilities of the GLM model family and the beginning and attempt towards an AI intelligent operating system.
Scaling is not just "At present, a viewpoint that I relatively agree with is that the computational volume might be the key, that is, the useful information."
"At this stage, AutoGLM is equivalent to adding an execution scheduling layer between humans and applications, largely changing the human-machine interaction form. More importantly, we see the possibility of LLM-OS. Based on the intelligent capabilities of large models (from L1 to L4 and even higher), there is an opportunity to achieve native human-machine interaction in the future. Bringing the human-machine interaction paradigm to a new stage."
The following is the post-conference interview with Peng Zhang, CEO of Zhipu, and Liu Xiao, the technical leader of Zhipu AutoGLM, organized by "Intelligent Emergence":
Intelligent Emergence: For example, various major companies, such as Meituan, Douyin, and WeChat, will develop their own agents. Then, after we released this AutoGLM, how do we consider the issue of ecological niche? Software, including some terminal sides, actually have a thick application wall, and some underlying permissions are not so easy to obtain. How does Zhipu solve this problem?
Peng Zhang: This is half a business issue and half a technical issue.
Liu Xiao: AutoGLM hopes to become a hub that helps people better connect hardware, applications, and services. It should be a tool that enables users to more easily combine various functions through natural language and according to their own personal wishes.
Technically, it is quite difficult. Originally, if they were in their original ecosystem, they could obtain data and design it completely by themselves, but this is also a development in a closed platform. You cannot cooperate well with others, and your model, that is, our model, is not smart enough to connect better.
Next, we hope to enable the model to connect to the ecosystems of various major company applications. This is a very important development focus for us next.
Peng Zhang: From a business perspective, it is a mutually beneficial way. We will have such an underlying ecosystem to provide a basic platform for everyone. The new manufacturers can now take what they need on this platform. For example, their own built Agent system can be connected to more other platforms.
Q: I would like to discuss a technical detail. To complete complex business processes, the intelligent agent needs to mobilize a large amount of data and applications. However, many websites and apps have their own APIs, and these APIs are not completely unified and lack standardization. This may make it difficult for enterprises to use the Agent. How will you solve this?
Liu Xiao: AutoGLM, essentially, is based on the user graphical interaction interface, which is fundamentally different from API invocation. It actually simulates human operations rather than using traditional APIs.
In the past, when using APIs, for example, yesterday we connected to an application, but after a week when a new version is released, it is very easy to become invalid.
However, by using the user re-visualized interaction interface, this problem is avoided. Because as long as this interface is still understandable by humans and is a software interface that users can really use, it can be applied.
Q: Why didn't everyone mention the concept of Agent much last year, but started to mention it this year? What elements do you think are satisfied?
Peng Zhang: First, regarding the issue that was less discussed last year, it is indeed because I think everyone can refer to some of our previous solution materials. Including the APP capabilities we mentioned, it is actually an embodiment of the model capabilities. If the degree is not enough, then it may not be able to achieve the expected effect. So the problem raised at that time was that due to your insufficient capabilities, the effect was not ideal.
The model is more about the human-computer interaction scene, and people's feelings can be more obvious. Previously, people were facing system, development, and other enterprise-level applications, so people were not very perceptible before.
On the other hand, with the advancement of technology and the increase in attention, now software and hardware manufacturers are also increasingly participating in adaptation. Therefore, the satisfaction of these two conditions makes our feelings on the terminal side more obvious.
Q: Has Scaling Law slowed down? What is your attitude? How does Zhipu find a solution?
Peng Zhang: What we are showing today is exactly the exploration of such a path. For example, when language encounters the human cognitive limit that may be insurmountable, can we break through this limit? This may require a large amount of data and large-scale processing.
In addition, in the multi-modal aspect, on the Agent we discussed today, this is all areas where Scaling can be attempted. In fact, there are many areas worth exploring.
The slowdown of Scaling Law is just a phenomenon, which is the result we finally observe. What is the essence of this system? We have been discussing this issue and looking for its essence.
At present, a viewpoint that I relatively agree with is: Computational volume might be the key, that is, the useful information.
The pre-training has slowed down, but the post-training curve now also has the effect of Scaling, but it will not be as simple and crude as the pre-training stage, where only the increase in data volume and parameter quantity is seen.
Q: I just saw many interesting applications of the agent, but there is still a gap from the productivity scenarios you just mentioned. If we want to use the agent to cover more, such as 50%, 80% of our device usage scenarios, or to make it do more things beyond pre-training. Then what things do we need to do next?
Liu Xiao: In fact, as we introduced in the technical report at today's conference, the current pre-training Scaling Law has indeed encountered a certain bottleneck at the industry level due to data issues at this stage.
But like o1, in fact, AutoGLM itself represents a new technology that opens up a new path for the Scaling of Agent to continue to mutate upwards.
We have almost found the same effect of Agent Scaling Law as shown in the OpenAI o1 blog. So the next step is actually how we can better iterate on the basis of such a model.
Pre-training still has space, but it requires new algorithms, frameworks, and data transformations.
Q: At the beginning of the year, you had many routes for both To B and To C. For To C, there are GLM OS and productivity applications. Now To B is still being done, and the C-end has shrunk to Agent. Has the previous OS been abandoned?
Peng Zhang: I don't think this is an abandonment. The exploration process is actually a process of continuous trial and error, right. It can be understood that it is our initial understanding of Agent, and now it is more concretely converged into the current Agent capabilities.
The effects of these capabilities are huge in our opinion, so concretizing them does not mean that those explorations are meaningless.
In fact, we can soon see many things coming out. Today it is operating mobile phones and computers, and tomorrow it may be operating your database and enterprise data