A Detailed Explanation of the "End-to-End" Next-Generation Model VLA: A Key Springboard towards Autonomous Driving
Text|Angie Li
Editor|Qin Li
Like the seafood market, the technological wave in the intelligent driving industry is rapidly changing. "End-to-end" has just become a new technical paradigm, and even before many companies have had time to complete the switch in their R & D model, end-to-end has entered the era of technological upgrading.
The latest evolutionary direction of "end-to-end" is to deeply integrate into the multimodal large model. In the past two years, large models have shown the ability to read text, recognize images, and make movies, but it is probably the first time for a large model to drive a vehicle.
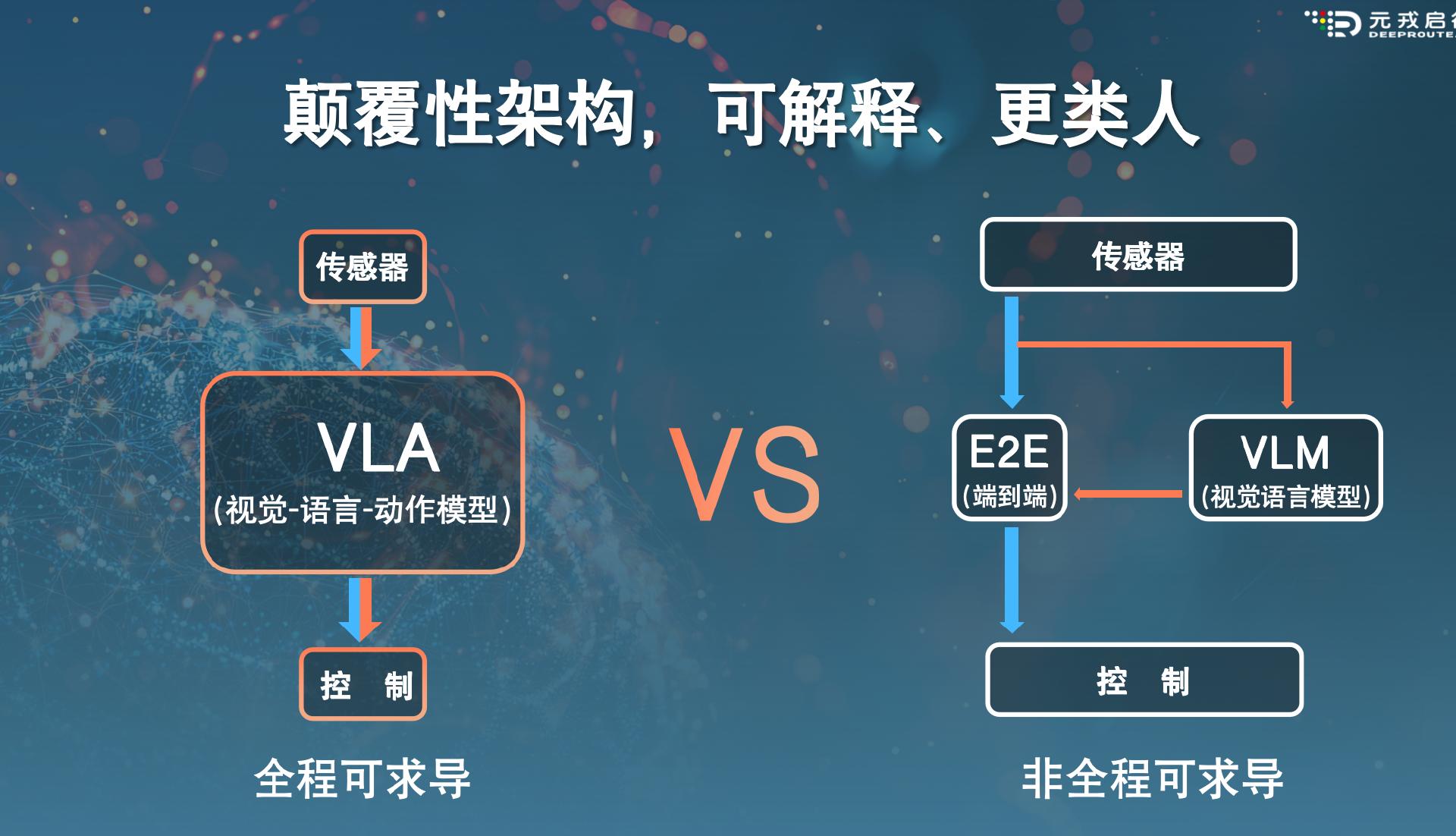
Recently, a multimodal large model paradigm that integrates vision, language, and action - VLA (Vision-Language-Action Model) has emerged in the intelligent driving industry, with higher scene reasoning and generalization capabilities. Many intelligent driving professionals regard VLA as the 2.0 version of the current "end-to-end" solution.
In fact, the VLA model was first seen in the robotics industry. On July 28, 2023, Google DeepMind launched the world's first visual language action (VLA) model for controlling robots.
However, this model concept is rapidly spreading to the intelligent driving field. At the end of October this year, Google's self-driving company Waymo launched an end-to-end self-driving multimodal model EMMA. Industry insiders say that this is a VLA model architecture that not only has end-to-end intelligent driving capabilities but also integrates a multimodal large model.
In the past, the intelligent driving industry has been exploring based on rule-based algorithms for more than ten years. In the past two years, the "end-to-end" intelligent driving led by Tesla has become a new technical direction, not only making intelligent driving more anthropomorphic but also able to deal with a large number of complex traffic scenarios in the city.
In coordination with the "end-to-end" technology, industry players will also add large language models to improve the upper limit of intelligent driving capabilities. The combination of end-to-end and VLM (Visual Language Model) is highly regarded by companies such as Ideal.
But unlike the relatively independent and low-frequency mode of VLM in providing driving suggestions for end-to-end, under the VLA architecture, the combination of end-to-end and the multimodal large model will be more thorough. Even Ideal insiders admitted to 36Kr Auto, "VLA can be seen as the combination of end-to-end and VLM."
The VLA model is likely to be the "terminator" of the "end-to-end + VLM" technical framework.
Some industry insiders say that the VLA model is of great significance to the evolution of intelligent driving. After making the end-to-end ability to understand the world stronger, "in the long run, in the leap from L2 assisted driving to L4 autonomous driving, VLA may become a key springboard."
Some automotive intelligent driving players are already secretly working hard. Previously, Ideal Auto stated in the third-quarter earnings conference call that it has internally initiated the pre-research of L4-level autonomous driving, and on the basis of the current technical route, it is developing a reinforcement learning system that combines a more powerful vehicle-end VLA model with a cloud-end world model.
After receiving a 700 million yuan investment from Great Wall Motors, intelligent driving company DeepRoute also said it will further layout the VLA model. DeepRoute claims that the company will conduct VLA model research and development based on NVIDIA's latest intelligent driving chip Thor, and the model is expected to be launched in 2025.
However, there is a consensus that it is not easy to implement the VLA model in vehicles, and it has high-intensity requirements for both technology and the computing power of the vehicle-end chip. "The chip that can support the delivery of the VLA model in vehicles may only appear in 2026."
The Latest Direction of End-to-End: Integrating Multimodal Large Models
Since the BEV and end-to-end technological waves in the intelligent driving industry since 2023, intelligent driving is gradually integrating AI neural networks into perception, planning, control and other links. Compared with the traditional rule-based solution, the AI and data-driven "end-to-end" has a higher capacity ceiling.
Source: DeepRoute
However, in addition to the "end-to-end" model, automotive companies also use external devices such as large language models and visual language models to provide a more powerful environmental understanding ability. In the middle of the year, Ideal launched a solution of end-to-end model + VLM (Visual Language Model). The VLM model has a stronger understanding ability of complex traffic environments and can provide relevant driving suggestions for end-to-end.
However, according to 36Kr Auto, the end-to-end model + VLM model of Ideal is two relatively independent models. "Ideal VLM occupies the computing power of an Ori chip, and currently mainly provides driving suggestions for scenarios such as speed limit reminders."
And the VLA model combines the end-to-end and VLM models into one. That is to say, the multimodal large model is no longer an external device for end-to-end, but becomes an inherent ability of end-to-end itself.
In the recent paper published by Google Waymo, the end-to-end autonomous driving multimodal model not only uses the video and images from the camera as perception input, but also can use instructions such as "Please turn right at the second ramp ahead and exit the ramp" from Google Maps as input, and combines the historical state of the vehicle to output the future trajectory of the vehicle.
Some industry insiders told 36Kr Auto that currently, for some special complex scenarios, intelligent driving still lacks learning data samples. If the multimodal large model is integrated, the knowledge learned by the large model can be transferred to the intelligent driving system, which can effectively deal with corner cases (long-tail scenarios).
Zhou Guang, the CEO of intelligent driving company DeepRoute, also believes that the VLA model is the 2.0 version of end-to-end. He said that when encountering some special scenarios such as complex traffic rules, tidal lanes, and long-term sequence reasoning, intelligent driving will understand and respond better than in the past.
For example, in terms of reasoning time, under the traditional rule-base (based on rules) solution, intelligent driving can only reason about the road conditions for 1 second and then make decision and control; the end-to-end 1.0 stage system can reason about the road conditions for the next 7 seconds, while VLA can reason about the road conditions for several tens of seconds.
"Basically, everyone has been pre-researching along this line for more than a year, but it will still be very difficult to mass-produce it next year," an industry insider said.
The Variation of End-to-End: Fewer Opportunities for Latecomers
Before entering large-scale promotion, the next-generation end-to-end solution still faces very realistic challenges.
On the one hand, the current vehicle-end chip hardware is not sufficient to support the deployment of the multimodal large model. Some industry insiders told 36Kr Auto that after combining the end-to-end and VLM models, the vehicle-end model parameters become larger, requiring not only efficient real-time reasoning ability, but also the ability of the large model to understand the complex world and give suggestions, which has quite high requirements for the vehicle-end chip hardware.
Currently, the computing power hardware for high-level intelligent driving is basically two NVIDIA OrinX chips, with a computing power of 508 Tops. Some industry insiders said that the current computing power of the vehicle-end is difficult to support the deployment of the VLA model.
However, NVIDIA's latest generation of vehicle-mounted AI chip Thor is expected to change this situation. The single-chip AI computing power of Thor is 1000 Tops, and it has good support for AI, large models and other computing powers.
However, people in contact with NVIDIA told 36Kr Auto that the NVIDIA Thor chip is likely to be delayed for release next year, and the 700 Tops computing power version is expected to be launched first in the first half of the year. But a 700 Tops computing power chip may also not be able to support the VLA model, and the cost of two Thor chips is much higher.
The challenges of the mass production time and cost of NVIDIA's chips lie in front of automotive companies. For this reason, some new forces that develop their own chips are also closely following the chip progress. According to 36Kr Auto, the VLA model of a leading new force is expected to be officially implemented in vehicles in 2026. "By then, combined with the self-developed high-computing power chip, the effect of VLA will be more amazing," the above industry insider said.
Fortunately, under the VLA model architecture, the challenges in data do not increase suddenly.
Some industry insiders told 36Kr that on the basis of end-to-end, the VLA model integrates the visual language model and the action model. But the data of the multimodal large model is not difficult to obtain, and the already open-source large models and the existing general language on the Internet may all become the nutrients of the intelligent driving multimodal large model.
What is more challenging is how to deeply integrate the data and information of end-to-end and the multimodal large model. This tests the model framework definition ability and the rapid iteration ability of the top intelligent driving teams.
These all determine that the VLA model will not enter the mass production stage of intelligent driving too quickly.
However, the sudden upgrade and competition variation of the technical route have set a higher threshold for players who have not yet exerted their strength in end-to-end, and the opportunities for latecomers to gain an advantage are even rarer.