Detaillierte Erklärung des Next-Generation-End-to-End-Modells VLA: Eine entscheidende Brücke zum autonomen Fahren.
Text|Li Anqi
Bearbeitung|Li Qin
Ähnlich wie auf einem Fischmarkt erleben die Technologien im Bereich des autonomen Fahrens rasante Veränderungen. Kaum hat sich „End-to-End“ als neues technologisches Paradigma etabliert, ist es schon wieder Zeit für den nächsten technischen Wandel, selbst wenn viele Unternehmen ihre F&E-Modelle noch nicht umgestellt haben.
Die neueste Entwicklungsrichtung des „End-to-End“ ist die tiefe Integration in multimodale große Modelle. In den vergangenen zwei Jahren haben große Modelle bereits die Fähigkeiten zum Textverstehen, zur Bilderkennung und zur Filmproduktion gezeigt, aber das autonome Fahren wäre etwas völlig Neues.
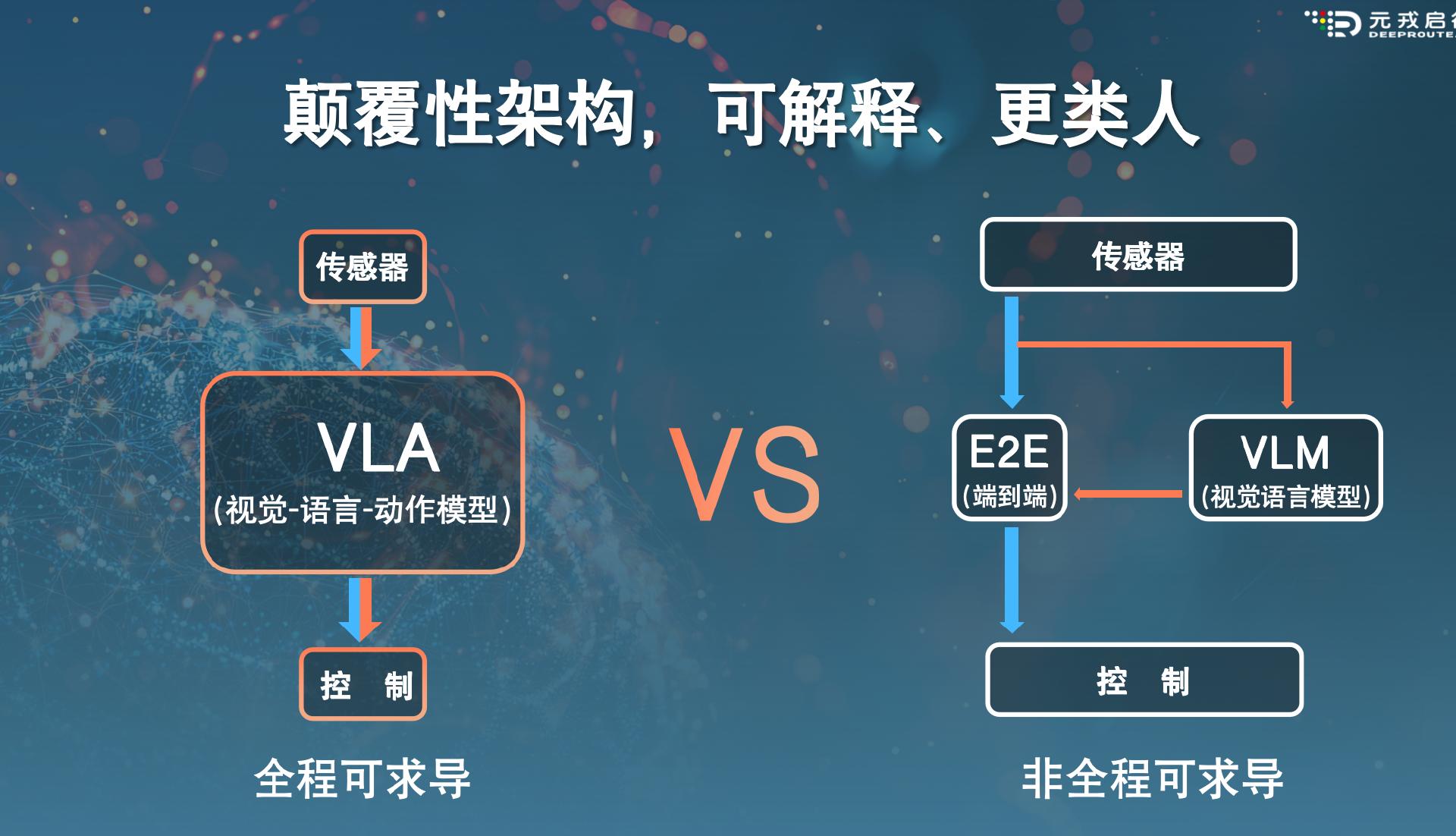
Kürzlich ist im Bereich autonomes Fahren eine multimodale große Modellparadigma namens VLA (Vision-Language-Action Model, also Visuell-Sprache-Aktion Modell) aufgetaucht, das eine höhere Fähigkeit zur Szenariodeutung und Generalisierung bietet. Viele Fachleute im Bereich des autonomen Fahrens sehen VLA als die Version 2.0 der derzeitigen „End-to-End“-Lösung.
Tatsächlich fand das VLA-Modell seine erste Anwendung in der Robotik. Am 28. Juli 2023 führte Google DeepMind das weltweit erste visuelles Sprachaktionsmodell (VLA) zur Steuerung von Robotern ein.
Jedoch breitet sich dieses Modellkonzept schnell auch auf das autonome Fahren aus. Ende Oktober dieses Jahres präsentierte Waymo, die Tochtergesellschaft von Google für autonomes Fahren, ein auf dem „End-to-End“-Paradigma basierendes, multimodales Modell namens EMMA. Branchenkenner sehen darin eine VLA-Modellstruktur, die sowohl End-to-End-Fähigkeiten als auch Elemente eines multimodalen großen Modells beinhaltet.
In der Vergangenheit erforschte die Branche des intelligenten Fahrens mehr als ein Jahrzehnt lang Regelalgorithmen. In den letzten zwei Jahren wurde das von Tesla angeführte „End-to-End“ zum neuen Technologietrend, der nicht nur menschenähnlichere Verhaltensweisen imitiert, sondern auch mit den komplexen Verkehrssituationen in Städten besser umgehen kann.
Ergänzend zur „End-to-End“-Technologie setzen Branchenakteure auch auf große Sprachmodelle, um die Grenzen der autonomen Fahrfähigkeit zu erweitern. End-to-End+VLM (Visuelles Sprachmodell) wird beispielsweise von Unternehmen wie Ideal hochgeschätzt.
Unterschiedlich zu VLM, das relativ unabhängig und selten Fahrempfehlungen für End-to-End bietet, verbindet die VLA-Architektur die „End-to-End“-Technologie und das multimodale große Modell intensiver. Selbst Experten des Unternehmens Ideal räumten gegenüber 36Kr Auto ein: „Man kann VLA als Fusion zwischen End-to-End und VLM betrachten.“
Das VLA-Modell könnte der „End-to-End+VLM“-Technologierahmen beenden.
Branchenkenner betonen, dass das VLA-Modell eine große Bedeutung für die Weiterentwicklung des autonomen Fahrens hat, da es die „End-to-End“-Fähigkeit, die Welt zu verstehen, verstärkt. Langfristig könnte VLA in dem Sprung von L2-Fahrassistenz zu L4-autonomem Fahren eine Schlüsselrolle spielen.
Einige Automobilhersteller und Akteure im intelligenten Fahrwesen bereiten sich bereits heimlich darauf vor. In einer Telefonkonferenz zu den Q3-Ergebnissen erklärte Ideal Auto, dass intern bereits Vorbereitungen zur Erforschung des L4-Autonomiegrads begonnen haben und man plant, ein stärkeres Fahrzeug-seitiges VLA-Modell zu entwickeln, das mit einem Cloud-Weltmodell kombiniert wird.
Das Unternehmen Yuanrong Qixing kündigte nach dem Erhalt einer Investition von 700 Millionen RMB von Great Wall Motors ebenfalls an, das VLA-Modell weiterzuverfolgen. Yuanrong Qixing erklärte, dass man das VLA-Modell auf Basis des neuesten intelligenten Fahrchips Thor von Nvidia entwickeln möchte, wobei das Modell voraussichtlich 2025 vorgestellt wird.
Es herrscht jedoch auch Einigkeit darüber, dass die Implementierung des VLA-Modells auf Fahrzeugen mit erheblichen Schwierigkeiten verbunden ist und sowohl hohe technische als auch Chip-Leistungsanforderungen stellt. „Chips, die das VLA-Modell auf Fahrzeugen unterstützen können, werden möglicherweise erst 2026 verfügbar sein.“
Die neueste Richtung: Integration multimodaler großer Modelle
Seit den von BEV und „End-to-End“-Technologie im Jahr 2023 ausgelösten Wellen, integriert autonomes Fahren schrittweise KI-Neuronale Netze in Wahrnehmung, Planung und Steuerung. Im Vergleich zu traditionellen regelbasierten Ansätzen bietet das „End-to-End“ auf KI und datengetriebener Basis eine höhere Leistungsstärke.
Bildquelle: Yuanrong Qixing
Außerhalb des „End-to-End“-Modells setzen Autohersteller auch große Sprachmodelle und visuelle Sprachmodelle ein, um eine stärkere Fähigkeit zum Umweltverständnis zu bieten. Mitte des Jahres führte Ideal eine Lösung aus End-to-End-Modell und VLM (Visuelles Sprachmodell) ein. Das VLM-Modell besitzt eine stärkere Fähigkeit, komplexe Verkehrsumgebungen zu verstehen und bietet relevante Fahrempfehlungen für End-to-End.
Wie 36Kr Auto berichtet, handelt es sich bei Ideals End-to-End-Modell und VLM-Modell um zwei relativ unabhängige Modelle. „Ideals VLM nutzt die Rechenleistung eines Ori-Chips und bietet derzeit hauptsächlich Fahrempfehlungen für Geschwindigkeitsbeschränkungen an.“
Das VLA-Modell hingegen kombiniert die End-to-End- und VLM-Modelle. Das bedeutet, dass das multimodale große Modell nicht länger als Add-on für End-to-End dient, sondern zu einer intrinsischen Fähigkeit von End-to-End wird.
In einem kürzlich veröffentlichten Paper von Google Waymo wird beschrieben, dass das End-to-End-Multimodell für autonomes Fahren nicht nur Video und Bild von Kameras als Eingabewahrnehmung nutzt, sondern auch Eingabeaufforderungen wie „Bitte rechts abbiegen an der zweiten Ausfahrt“ von Google Maps sowie den historischen Fahrzeugstatus kombiniert, um die zukünftige Fahrzeugtrajektorie auszugeben.
Branchenkenner sagten gegenüber 36Kr Auto, dass der autonome Fahrbereich für einige spezialisierte, komplexe Szenarien immer noch auf Lernmusterdaten fehlt. Wenn jedoch multimodale Modelle integriert werden, könnte das, von großen Modellen gelernte Wissen auf autodidaktische Systeme übertragen werden, was wirksame Bewältigung von Randfällen (Long-Tail-Szenarien) ermöglicht.
Zhou Guang, CEO von Yuanrong Qixing, sieht das VLA-Modell ebenfalls als Version 2.0 des End-to-End. Er sagte, dass bei komplexen Verkehrsregeln, besonderen Fahrstreifen und langperiodischen Szenarios das autonome Fahren besser als je zuvor in der Lage sei, sie zu verstehen und zu bewältigen.
Zum Beispiel bezieht sich die Begründungsdauer: Bei traditionellen regelbasierten Systemen kann Intelligenz nur eine Sekunde der Verkehrsinformationen verarbeiten und dann Entscheidungen treffen; im End-to-End-1.0-Stadium kann das System die Verkehrssituation für die nächsten sieben Sekunden vorhersehen, während VLA dutzende Sekunden vorhersagen kann.
„Grundsätzlich sind derzeit alle seit einem Jahr in der Vorforschung, aber es ist schwer, bis nächstes Jahr in die Massenproduktion zu gehen“, bemerkte ein Brancheninsider.
Abwandlung des End-to-End, weniger Chancen für Späteinsteiger
Bevor die großangelegte Einführung beginnt, stehen die nächsten End-to-End-Lösungen vor realen Herausforderungen.
Zum einen reichen die derzeitigen Hardwarekapazitäten von Fahrzeugchips nicht aus, um eine multimodale Modellimplementierung zu unterstützen. Laut einem Branchenexperten, der mit 36Kr Auto sprach, erhöhen sich bei der Kombination von End-to-End mit dem VLM-Modell dramatisch die Parameter des fahrzeugseitigen Modells. Es erfordert nicht nur effiziente Echtzeit-Verarbeitungskapazitäten, sondern auch Lesefähigkeit der großen Modelle, um die komplexe Welt zu verstehen und Empfehlungen zu geben, was extrem hohe Anforderungen an die Hardware von Fahrzeugchips stellt.
Derzeit verfügen fortgeschrittene autonome Fahrfähigkeiten über eine Rechenleistung von zwei Nvidia OrinX Chips mit einer Leistung von 508 Tflops. Branchenkenner sagen, dass es derzeit schwierig ist, das VLA-Modell mit der aktuellen Rechenleistung in Fahrzeugen zu implementieren.
Der neueste AI-Chip von Nvidia, Thor, soll dieses Problem ändern, da er eine einzige AI-Rechenleistung von 1000 Tflops bietet und sowohl KI als auch große Modellleistung unterstützt.
Jedoch warnten Personen, die in Kontakt mit Nvidia stehen, dass der Thor-Chip möglicherweise auf nächstes Jahr verschoben wird, wobei zuerst die Version mit 700 Tflops Rechenleistung veröffentlicht werden könnte. Doch selbst ein Chip mit 700 Tflops Rechenleistung könnte das VLA-Modell nicht unterstützen, und zwei Thor-Chips wären extrem kostspielig.
Die Herausforderungen der Markteinführung und der Kosten von Nvidias Chips stellen Hürden für die Autohersteller dar. Deshalb sind einige neue Kräfte mithilfe von Eigenentwicklungschips gehalten, um mit dem Fortschritt mitzuhalten. Laut Informationen von 36Kr Auto plant eine führende Marke, ihr VLA-Modell im Jahr 2026 in Fahrzeugen zu implementieren. „In Verbindung mit neuen leistungsstarken Chips werden die Effekte des VLA bemerkenswerter werden“, sagte der zuvor erwähnte Branchenkenner.
Glücklicherweise sind die Datenherausforderungen unter der VLA-Modellarchitektur nicht dramatisch gestiegen.
Branchenkenner erklärten gegenüber 36Kr, dass das VLA-Modell auf dem End-to-End-Modell basierend ein visuelles Sprachmodell und Aktionsmodell integriert. Doch die Daten für multimodale große Modelle sind nicht schwer zu erhalten, einschließlich offener großer Modelle und bereits vorhandenen allgemeinen Sprachdaten im Internet dienen als Grundlage für multimodale große Modelle im autonomen Fahrwesen.
Größere Herausforderungen bestehen in der tiefgreifenden Integration der Daten und Informationen der End-to-End- und multimodalen großen Modelle, was die Fähigkeit zur Modellrahmendefinition und schnellen Modellentwicklung von führenden Teams im autonomen Fahren prüft.
All dies hat Auswirkungen darauf, dass VLA-Modelle nicht schnell in den Massenproduktionsprozess des autonomen Fahrens gelangen werden.
Die plötzliche Eskalation der technologischen Entwicklung und der Wettkampf stellen ein höheres Hindernis für Spieler dar, die noch nicht im End-to-End-Bereich aktiv geworden sind, wodurch Chancen für Späteinsteiger noch seltener werden.