Google has open-sourced Gemma 3 270M, whose performance surpasses that of the same-level models of Qwen 2.5.
The downloaded file is only 241 MB.
On Thursday this week, Google officially released the latest model in the Gemma 3 series.
Gemma 3 270M is a compact language model with 270 million parameters. It is designed for fine - tuning on specific tasks and has powerful instruction - following and text structuring capabilities.
It inherits the advanced architecture and powerful pre - training capabilities of the Gemma 3 series, and at the same time brings strong instruction execution capabilities to small - sized models. As shown in the IFEval benchmark results presented by Google, Gemma 3 270M sets a new performance level among peer models, making complex AI functions more accessible for device - side and research applications.
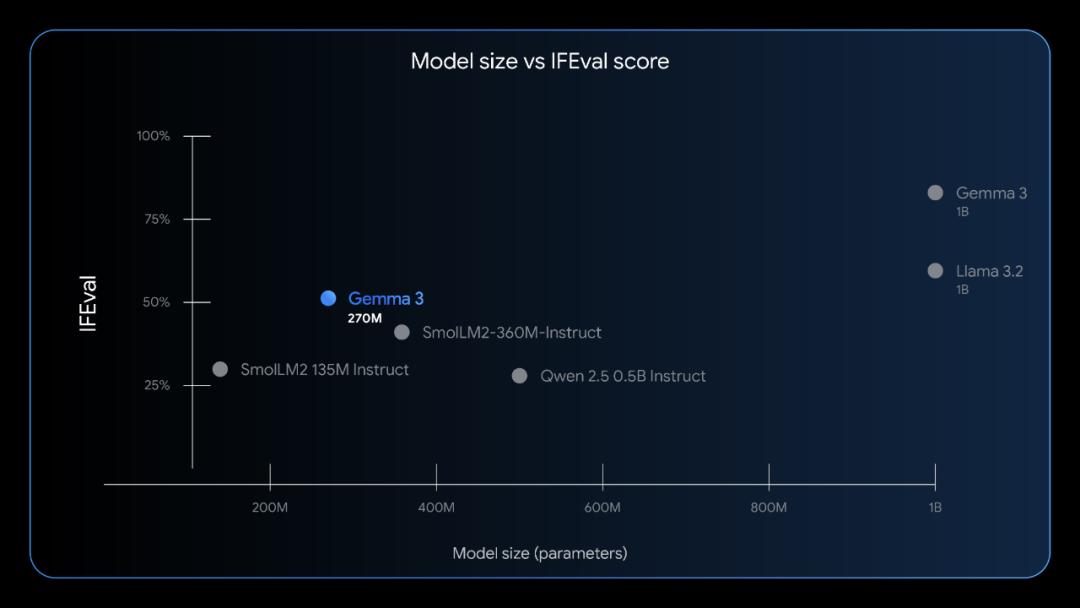
IFEval is designed to test the model's ability to execute verifiable instructions.
The core functions of Gemma 3 270M mainly include the following aspects:
- Compact and powerful architecture: The new model has a total of 270 million parameters. Due to the large vocabulary, there are 170 million embedding parameters and 100 million parameters in the Transformer module. Thanks to the large vocabulary of 256k tokens, the model can handle specific and rare tokens, making it a powerful base model that can be further fine - tuned in specific domains and languages.
- Extreme energy efficiency: A key advantage of Gemma 3 270M is its low power consumption. Internal tests on the Pixel 9 Pro phone SoC show that the INT4 quantized model only consumes 0.75% of the battery power in 25 conversations, making it the most energy - efficient Gemma model.
- Instruction following: Google has released an instruction - tuned model with pre - trained checkpoints. Although the model is not designed for complex conversation use cases, it is a powerful model that can follow general instructions out of the box.
- Quantization for production: Quantization - aware training (QAT) checkpoints are available, enabling people to run the model with INT4 precision while minimizing performance degradation, which is crucial for deployment on resource - constrained devices.
Google didn't explain in detail how to ensure no embedding collapse during the training process for the 170 million embedding parameters. However, after Google's release, the AI community quickly started research.
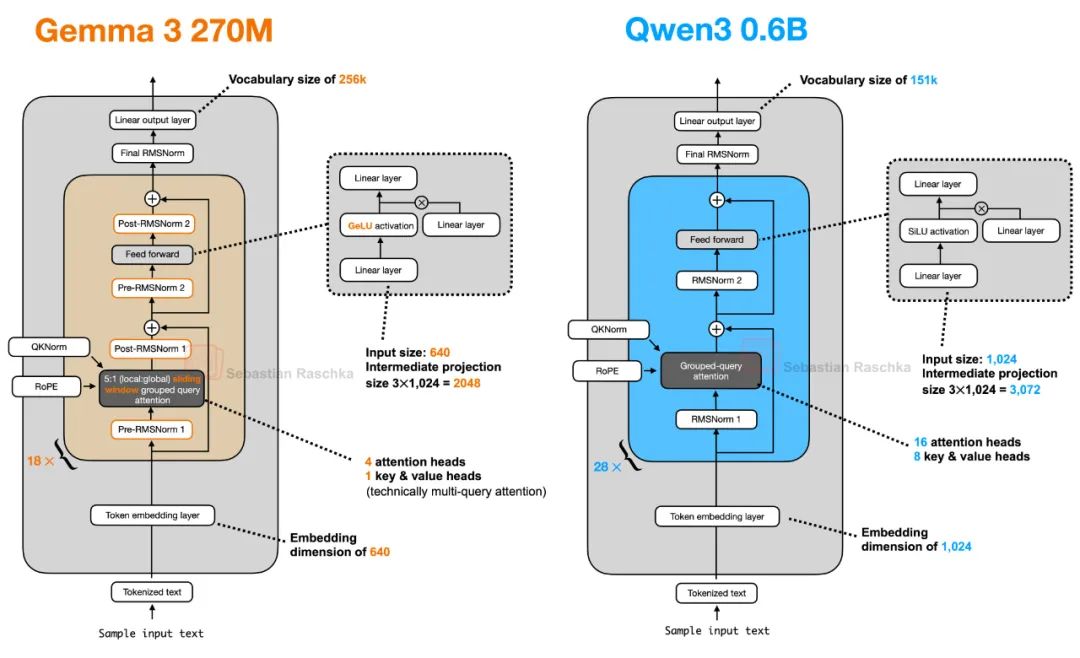
Sebastian Raschka provided a simple interpretation right away and noticed some architectural features of the new model.
Google says that Gemma 3 270M is a high - quality base model that can be used out of the box for specialized tasks. In practice, people should start with a compact and powerful model to build a lean, fast, and low - cost production system.
This approach has achieved good results in the real world. Google cited the example of the cooperation between Adaptive ML and SK Telecom. Facing the challenge of detailed multilingual content moderation, they chose specialization. Instead of using a large - scale general model, Adaptive ML fine - tuned the Gemma 3 4B model. The results show that the specialized Gemma model has achieved or even exceeded the performance of larger proprietary models on their specific tasks.
Gemma 3 270M aims to allow developers to further leverage this approach to unlock higher efficiency for well - defined tasks. It is an ideal starting point for creating a series of small specialized models, each an expert in its own task.
The power of specialization is not only applicable to enterprise tasks but also helps individual developers build creative applications. For example, members of the Hugging Face team used Gemma 3 270M to power a bedtime story generator web application using Transformers.js. It can be seen that the model's size and performance make it very suitable for offline, web - based creative tasks.
Google says that Gemma 3 270M is suitable for the following scenarios:
- There is a high - capacity and well - defined task. The model is very suitable for functions such as sentiment analysis, entity extraction, query routing, unstructured to structured text processing, creative writing, and compliance checking.
- Tasks that require cost - effectiveness and have high latency requirements. It can significantly reduce or even eliminate inference costs in production and provide faster responses to users. The fine - tuned 270M model can run on lightweight infrastructure or directly on the device.
- Work that requires rapid iteration and deployment. The small size of Gemma 3 270M enables rapid fine - tuning experiments, helping you find the perfect configuration for your use case within hours (instead of days).
- Tasks that require ensuring user privacy. Since the model can run entirely on the device, you can build applications that handle sensitive information without sending data to the cloud.
- You need a batch of specialized task models. Build and deploy multiple custom models, each professionally trained to complete different tasks without exceeding the budget.
For the new model, Google provides quick - start solutions and tools. You can find a guide for full fine - tuning with Gemma 3 270M in the Gemma documentation: https://ai.google.dev/gemma/docs/core/huggingface_text_full_finetune
Google also released the pre - trained model and instruction - tuned model of Gemma 3 270M: https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
You can try out the model on Vertex AI or use popular inference tools such as llama.cpp, Gemma.cpp, LiteRT, Keras, and MLX: https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/gemma3
Now, you can also try fine - tuning on Colab by yourself, which can be completed in less than 5 minutes.
In the past few months, Google's Gemma open - source model series has undergone a series of releases. From April to May, Google launched Gemma 3 and Gemma 3 QAT, providing good AI performance for single - cloud and desktop - level GPUs. Then on June 25th, Gemma 3n for mobile was officially released, introducing powerful real - time multimodal AI capabilities to devices such as mobile phones.
Google says that as of last week, the cumulative downloads of the Gemma series have exceeded 200 million.
Reference content:
https://developers.googleblog.com/en/introducing-gemma-3-270m/
This article is from the WeChat official account "Machine Intelligence", and is published by 36Kr with authorization.