After ingesting 1.7 billion images, Meta's most powerful model DINOv3 is open-sourced, redefining the ceiling of computer vision.
[Introduction] Without manual annotation, after ingesting 1.7 billion images, Meta has trained a "visual all - rounder" using self - supervised learning! NASA has sent it to Mars, and the medical, satellite, and autonomous driving fields are all abuzz.
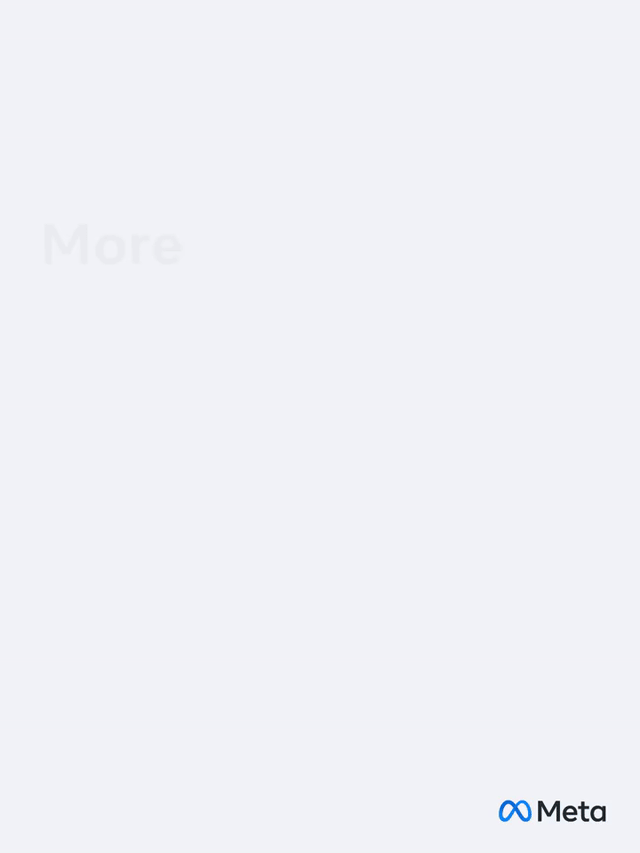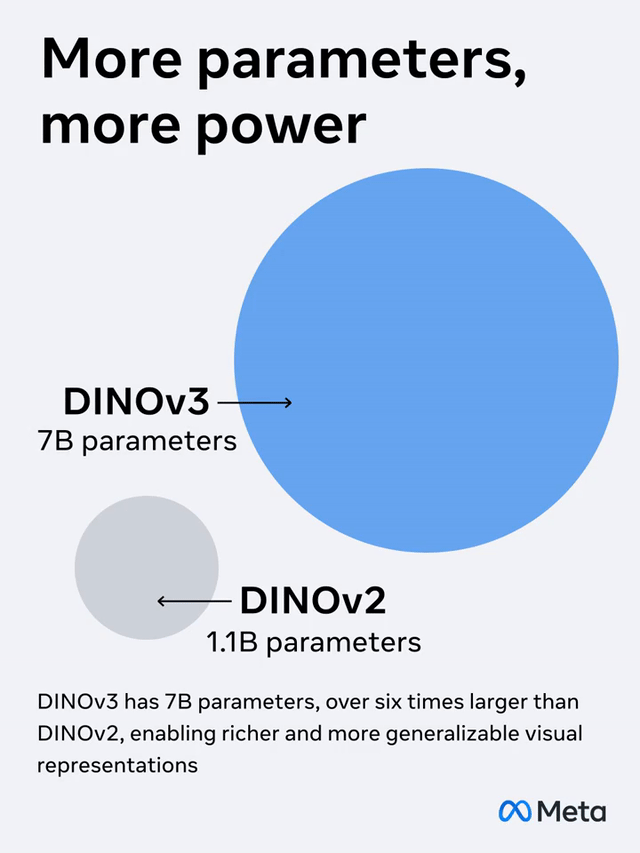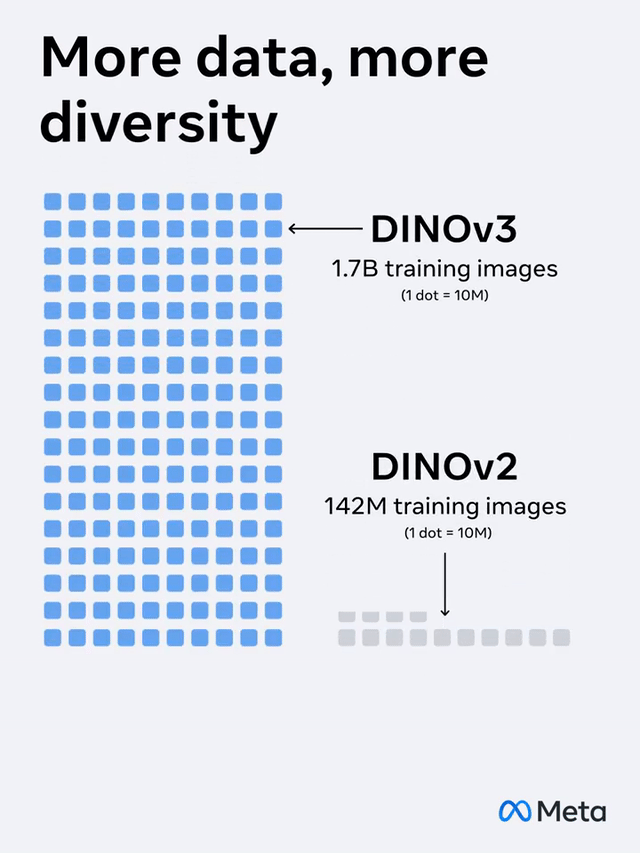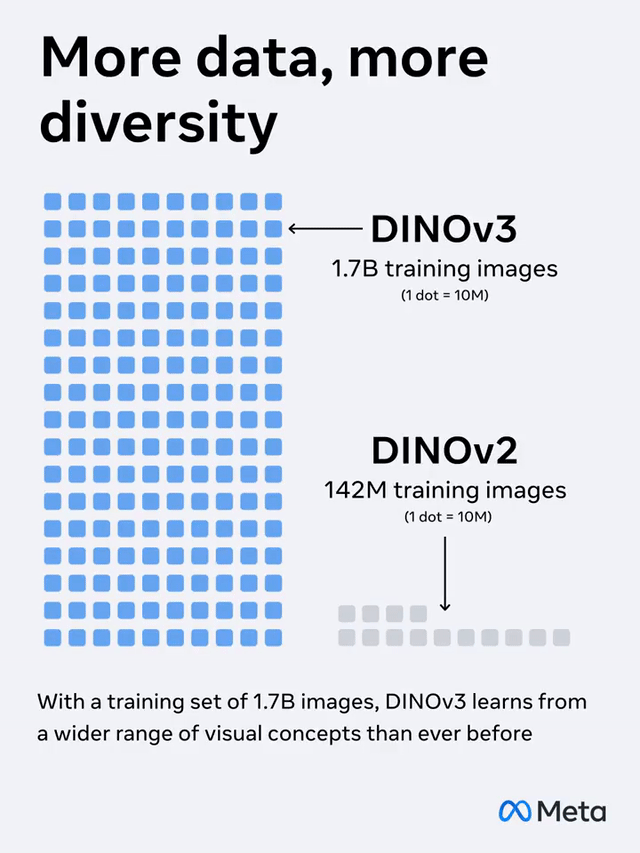
With 1.7 billion images, Meta has trained a "visual behemoth" DINOv3 with 7 billion parameters, and it's completely open - source!
Trained through self - supervised learning (SSL), DINOv3 can generate powerful and high - resolution image features.
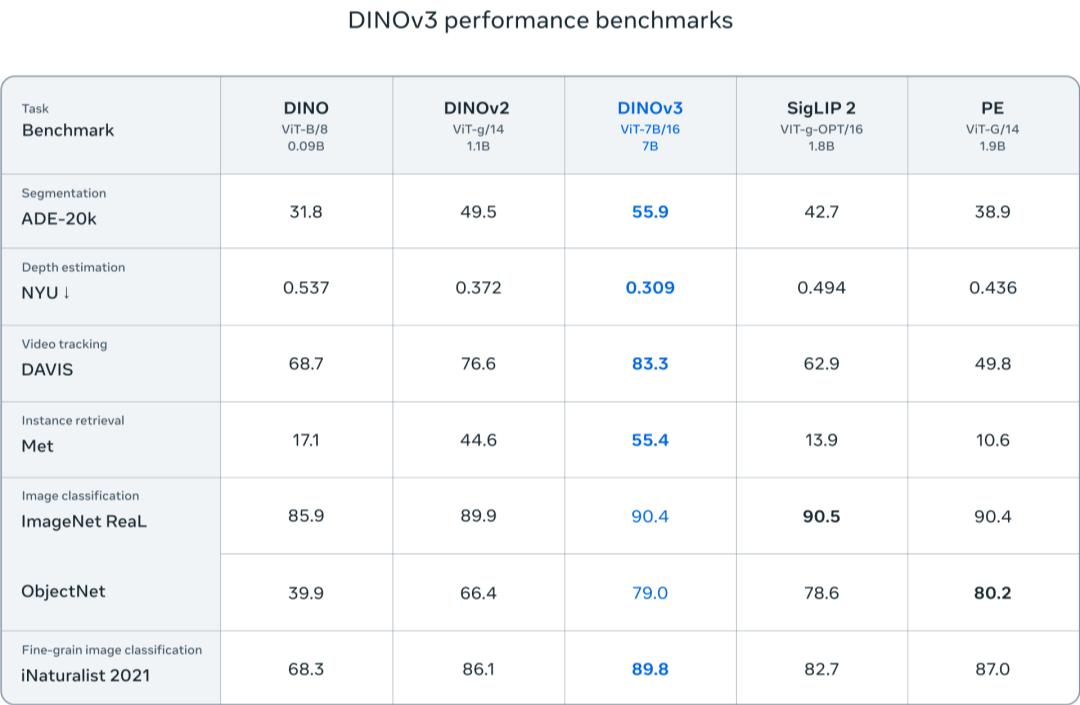
In multiple dense prediction tasks, this is the first time that a single fixed visual backbone network has outperformed specialized solutions.
DINOv3 redefines the ceiling of computer vision performance, refreshing or approaching the best results in multiple benchmark tests!
Even NASA in the United States has used DINOv3 in Mars exploration. It has truly gone to space!
Just when everyone thought Meta had been left behind in the AI competition, Meta has finally regained its glory this time.

Moreover, this time Meta is truly open - source: DINOv3 is not only commercially available but also open - sources the entire "full - process" including the complete pre - trained backbone network, adapters, training and evaluation codes.

Project address: https://github.com/facebookresearch/dinov3
All checkpoints: https://huggingface.co/collections/facebook/dinov3 - 68924841bd6b561778e31009
The highlights of DINOv3 are as follows👇:
SSL supports training a model with 1.7 billion images and 7 billion parameters without labels, making it suitable for scenarios with scarce annotation resources, including satellite images.
Generates excellent high - resolution features and achieves state - of - the - art performance in dense prediction tasks.
Applies to diverse visual tasks and domains, all using a frozen backbone (no fine - tuning required).
Includes smaller post - distillation models (ViT - B, ViT - L, and ConvNeXt variants for flexible deployment.
A new victory for self - supervised learning
Self - supervised learning can learn independently without manually annotated data and has become the dominant paradigm in modern machine learning.
The rise of large language models is entirely due to this: they obtain general representations by pre - training on massive text corpora. However, progress in the field of computer vision has been relatively slow because the currently most powerful image encoding models still rely heavily on manually generated metadata, such as web image captions, during training.
DINOv3 has changed all this:
DINOv3 proposes a new unsupervised learning technique that significantly reduces the time and resources required for training.
This annotation - free method is particularly suitable for scenarios where annotations are scarce, costly, or simply unavailable. For example, the DINOv3 backbone network pre - trained on satellite imagery performs excellently in downstream tasks such as canopy height estimation.
Not only can it accelerate the development of existing applications, but DINOv3 may also unlock new application scenarios, promoting progress in industries such as healthcare, environmental monitoring, autonomous driving, retail, and manufacturing, and enabling more accurate and efficient large - scale visual understanding.
Unprecedented: Self - supervised learning surpasses weak - supervised learning
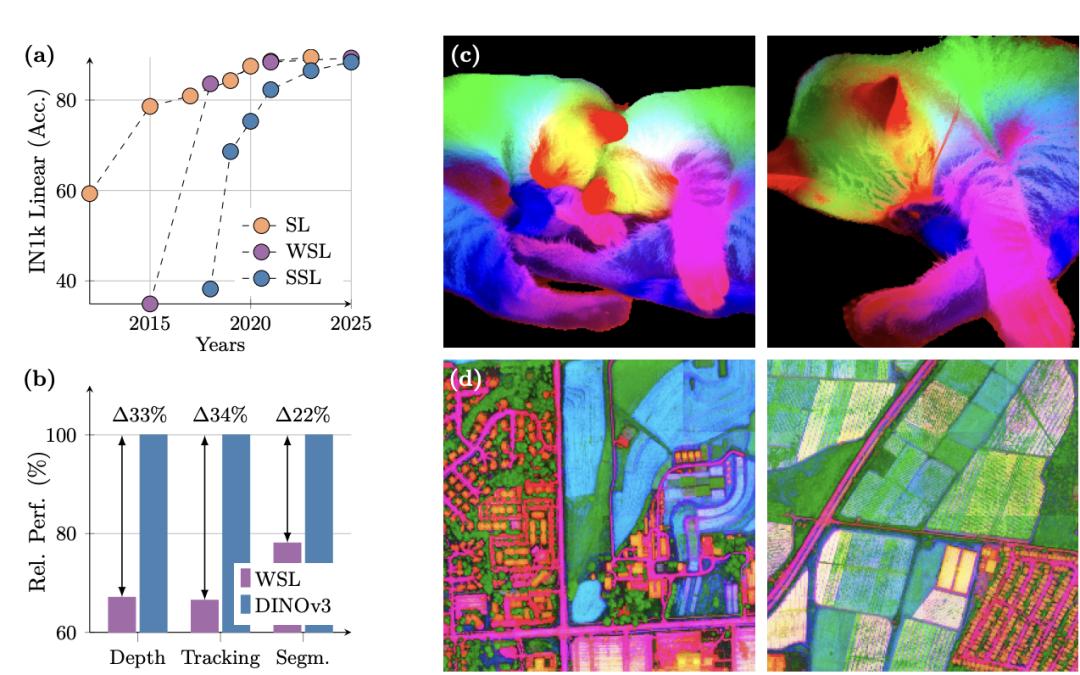
DINOv3 has once again set a new milestone - for the first time, it proves that self - supervised learning (SSL) models can outperform weak - supervised models in a wide range of tasks.
DINOv3 continues the DINO algorithm and does not require any metadata input. However, this time, the training computing power required is only a fraction of previous methods, yet it can still produce an extremely powerful visual foundation model.

With these new improvements, DINOv3 can also achieve the current best performance in competitive downstream tasks (such as object detection under frozen weights conditions).
This means that researchers and developers can directly apply it to a wider and more efficient range of scenarios without fine - tuning for specific tasks.
In addition, the DINO method is not optimized for specific image modalities. It is not only applicable to web images but can also be generalized to fields where annotation is extremely difficult or costly.
DINOv2 has already supported diagnostic and scientific research work in areas such as histopathology, endoscopy, and medical imaging using massive amounts of unannotated data. In the field of satellite and aerial imagery, the data volume is huge and complex, making manual annotation almost impossible.
DINOv3 can use these rich datasets to train a single backbone network and achieve various applications such as environmental monitoring, urban planning, and disaster response across different types of satellite images.
DINOv3 has already had an impact in the real world.
The World Resources Institute (WRI) is using the new model to monitor deforestation and support ecological restoration, helping local groups protect vulnerable ecosystems. Relying on DINOv3, the WRI analyzes satellite imagery to detect tree loss and land - use changes in affected ecological areas.
The accuracy improvement brought by DINOv3 enables it to automate the climate finance allocation process, reduce transaction costs by verifying restoration results, and accelerate the flow of funds to local small - scale organizations.
For example, compared with DINOv2, when measuring the canopy height in a certain area of Kenya, DINOv3 trained on satellite and aerial imagery reduced the average error from 4.1 meters to 1.2 meters.
Efficient scaling without fine - tuning
Compared with its predecessor DINOv2, DINOv3 has significantly increased in scale:
The model parameters have been expanded by 7 times, and the training data volume has also increased by 12 times.
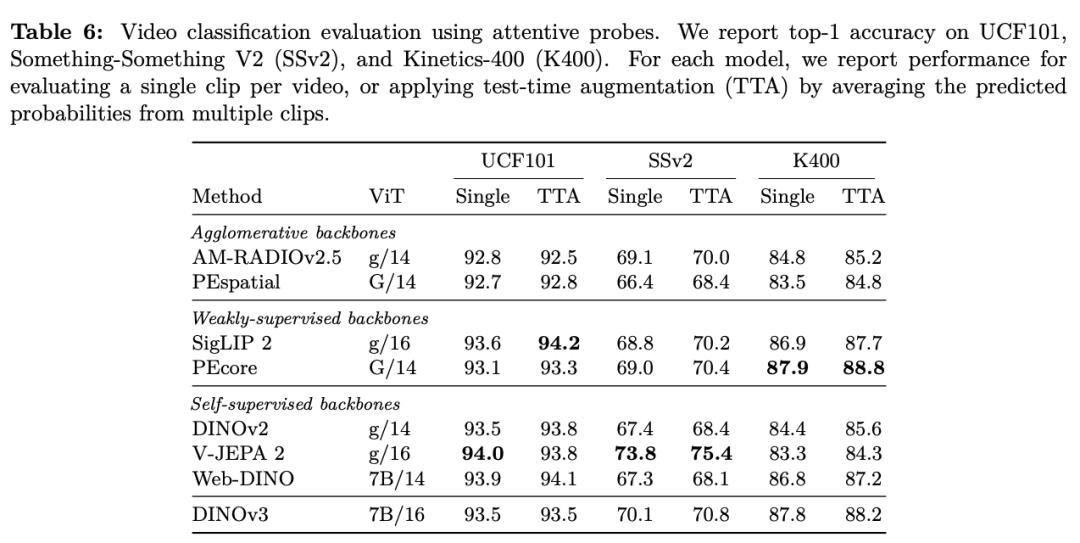
To verify its diversity, the Meta team comprehensively evaluated DINOv3 on 15 different visual tasks and more than 60 benchmark tests.
In various dense prediction tasks, the backbone network of DINOv3 performs excellently, demonstrating a deep understanding of scene structure and physical properties.
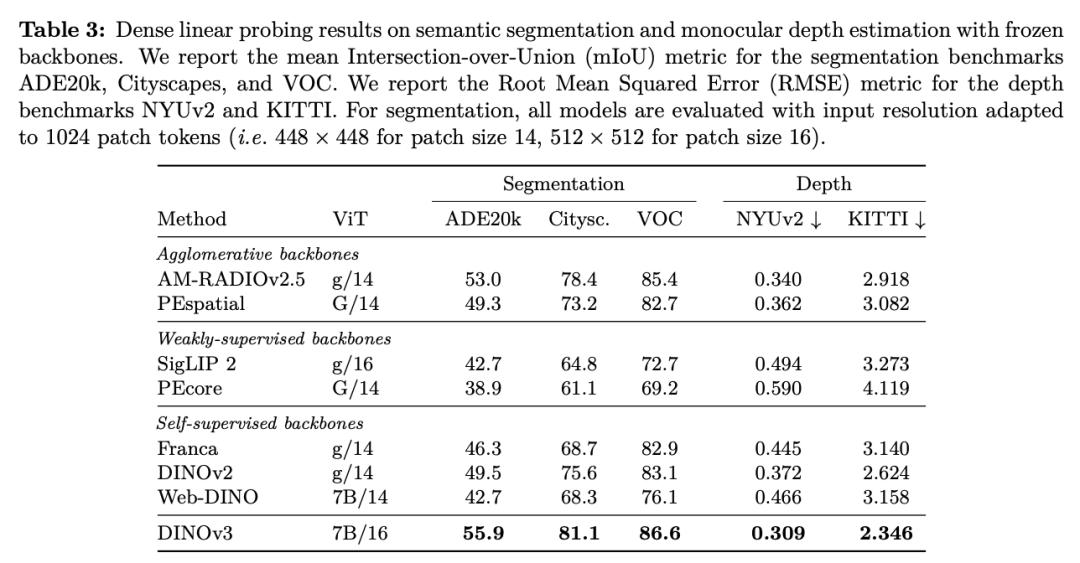
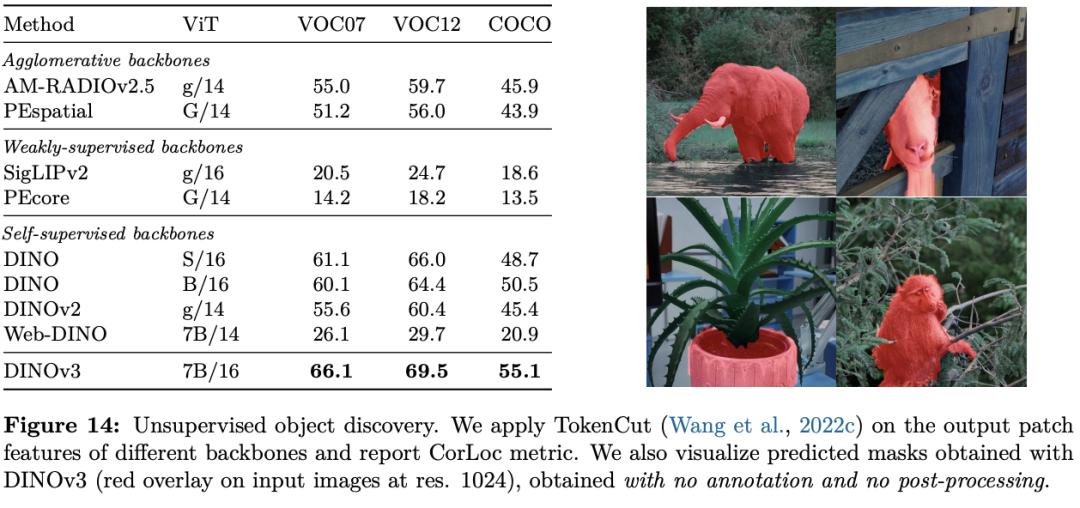
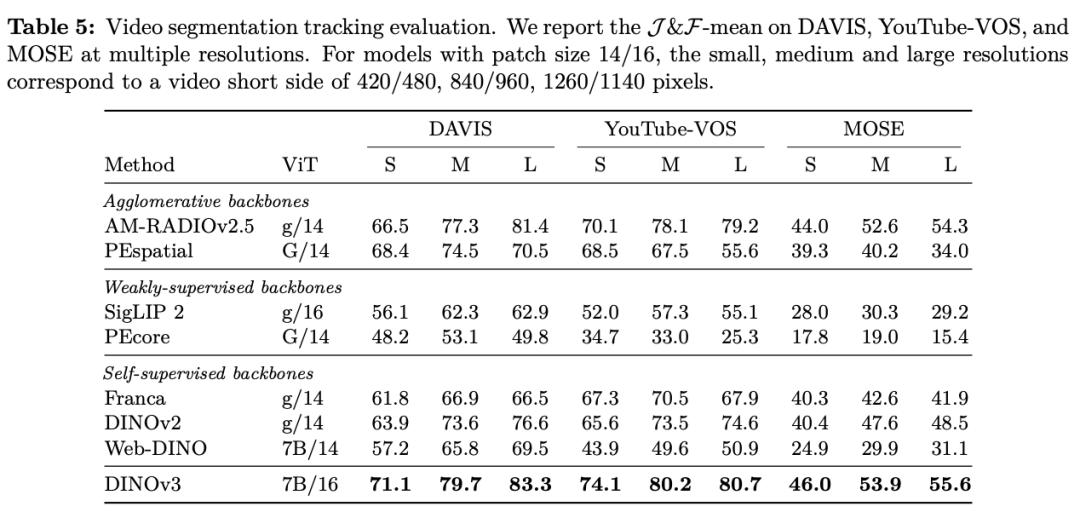
DINOv3 can extract rich dense features, generating a floating - point vector containing measurable attributes for each pixel in the image. These features can not only help identify the detailed structure of objects but also generalize between different instances and categories.
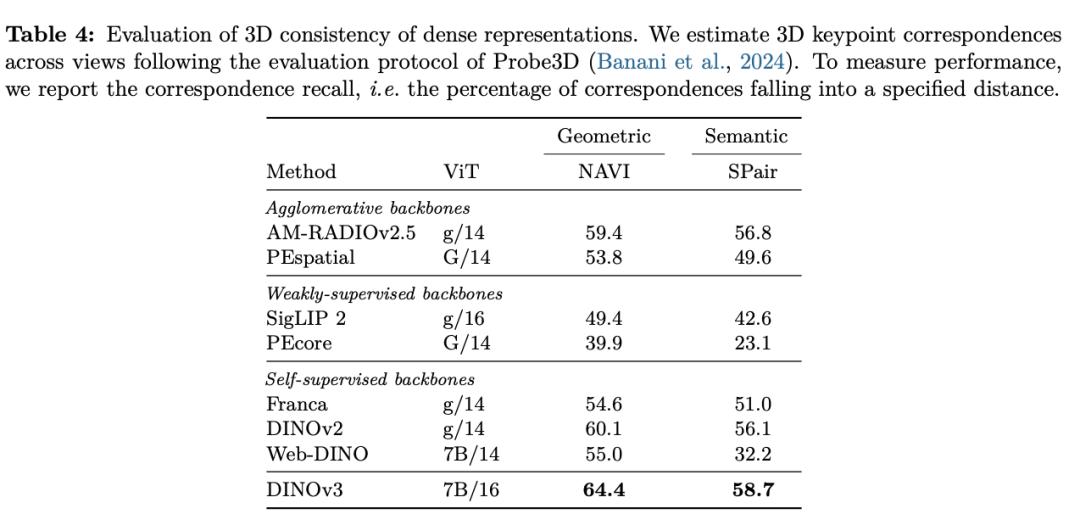
With this powerful representation ability, even using only a small amount of annotated data, a simple linear model, and some lightweight adapters, robust dense prediction results can be achieved on DINOv3. If combined with a more complex decoder, it can even reach the current state - of - the - art level in classic computer vision tasks such as object detection, semantic segmentation, and relative depth estimation without fine - tuning the backbone model.
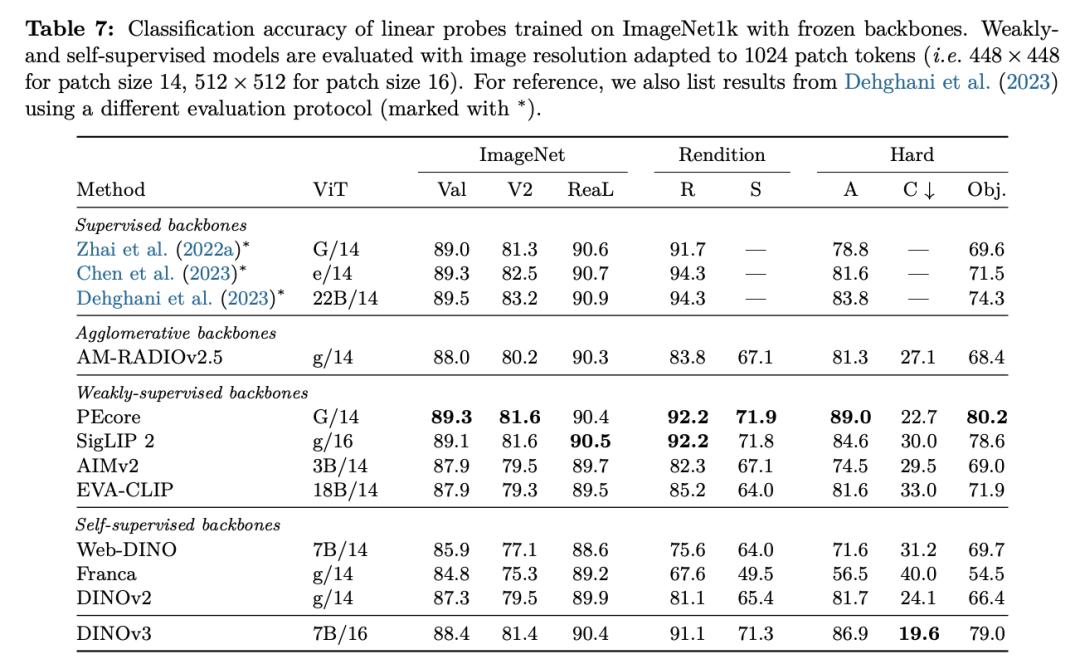
Since no fine - tuning is required, in a single forward pass, DINOv3 can serve multiple visual tasks simultaneously, allowing multiple tasks to share the computational overhead.
This is particularly crucial for scenarios where multiple visual processing tasks need to be executed in parallel on edge devices.
The excellent versatility and high efficiency of DINOv3 make it an ideal choice for such applications.
NASA's Jet Propulsion Laboratory (JPL) has already used DINOv2 to build Mars exploration robots, achieving the goal of completing multiple visual tasks with extremely low computing resources.

Suitable for practical deployment, all models are fully open - source
DINOv3 has been scaled up to 7 billion parameters, fully demonstrating the potential of self - supervised learning (SSL). However, such a large model is not practical for many real - world applications.
Therefore, Meta has built a family of models that cover different computing requirements from lightweight to high - performance to meet various research and development scenarios.
By distilling ViT - 7B into smaller but high - performance versions (such as ViT - B and ViT - L), DINOv3 outperforms similar CLIP models in multiple evaluation tasks.
In addition, they have also introduced a series of ConvNeXt architectures (T, S, B, L) based on the distillation of ViT - 7B, suitable for deployment requirements under different computing resource constraints.
At the same time, they have also opened up the complete distillation process to facilitate further expansion by the community.
Reference materials:
https://ai.meta.com/blog/dinov3 - self - supervised - vision - model/
https://ai.meta.com/dinov3/
https://ai.meta.com/blog/nasa - jpl - dino - robot - explorers/
https://ai.meta.com/research/publications/dinov3/
This article is from the WeChat official account "New Intelligence Yuan", edited by KingHZ. Republished by 36Kr with permission.