The inference cost has dropped by 75% suddenly. GPT-OSS achieves a 4-fold inference speed with a new data type, and an 80GB graphics card can run a large model with 120 billion parameters.
OpenAI has adopted the MXFP4 data type in its latest open - source model gpt - oss, directly slashing the inference cost by 75%!
Even more astonishing is that while reducing the memory usage to one - quarter of that of a BF16 model of the same scale, MXFP4 also boosts the token generation speed by a full 4 times.
In other words, this operation directly fits a large model with 120 billion parameters into a graphics card with 80GB of video memory. Even a graphics card with only 16GB of video memory can run a version with 20 billion parameters.
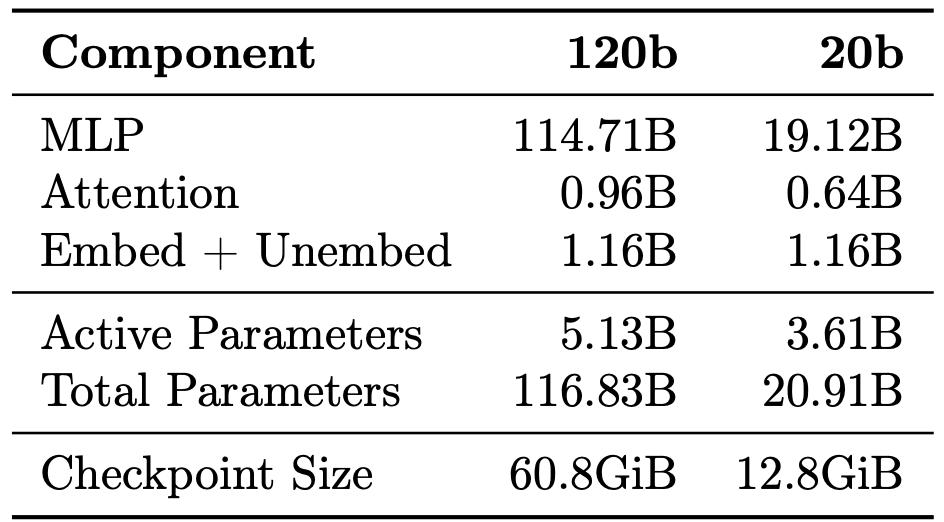
(Note: The video memory capacity is usually larger than the Checkpoint Size.)
Compared with previous data types, MXFP4 offers extremely high cost - effectiveness. The hardware resources required for model operation are only one - quarter of what they were before.
What's the magic of MXFP4?
In gpt - oss, OpenAI applies MXFP4 quantization to approximately 90% of the weights. The direct motivation (benefit) of this operation is to make the model operation cost even cheaper.
After quantizing the gpt - oss model to MXFP4, the memory occupied by the large language model is only 1/4 of that of a BF16 model of the same scale, and the token generation speed can be increased by up to 4 times.

How can changing the data type reduce the model operation cost? Here's the logic:
The operation cost of the model mainly consists of two parts: weight storage and memory bandwidth.
The former is the space where the model parameters are stored and occupied, that is, the number of bytes required to store them.
The latter is the limitation of the data read and write speed and capacity during model inference.
The change in data type will directly affect the occupation of weight storage and memory bandwidth.
For example, traditional model weights are usually stored in FP32 (32 - bit floating - point numbers), and each parameter occupies 4 bytes of memory.
If MXFP4 is used, then each weight is only half a byte, and the weight storage size is 1/8 of that of FP32, which greatly compresses the size of the weight data.
This compression not only reduces the model's storage space but also enables the model to complete faster data reading and writing under the same bandwidth, thereby improving the inference speed.
Thus, by changing the data type, cost reduction and efficiency improvement of inference can be achieved.
So, how does MXFP4 achieve this?
MXFP4
The full name of MXFP4 is Micro - scaling Floating Point 4 - bit, which is a 4 - bit floating - point data type defined by the Open Compute Project (OCP).
(Note: OCP is a hyperscale data center cooperation organization initiated by Facebook in 2011, aiming to reduce the cost of data center components and improve their availability.)
In the field of deep learning, the precision and efficiency of data types have always been the focus of researchers' trade - offs.
For example, the traditional FP4 has only four bits: 1 sign bit (indicating positive or negative), 2 exponent bits (determining the magnitude of the value), and 1 mantissa bit (representing the decimal part).
Although this representation method compresses the data volume, it also results in a very limited representable numerical range. It can only represent 8 positive numbers and 8 negative numbers.
In contrast, BF16 (1 sign bit, 8 exponent bits, and 7 mantissa bits) can represent 65,536 values. However, the increase in the representable range also brings an increase in computational cost.
If, in order to improve computational efficiency, the four BF16 values 0.0625, 0.375, 0.078125, and 0.25 are directly converted to FP4, they will become 0, 0.5, 0, 0.5.
It's not hard to see that such an error is obviously unacceptable.
Therefore, in order to ensure a certain level of precision while reducing the data volume, MXFP4 multiplies a set of high - precision values (32 by default) by a common scaling factor (this scaling factor is an 8 - bit binary exponent). Thus, the four BF16 values mentioned above will become 1, 6, 1.5, 4.
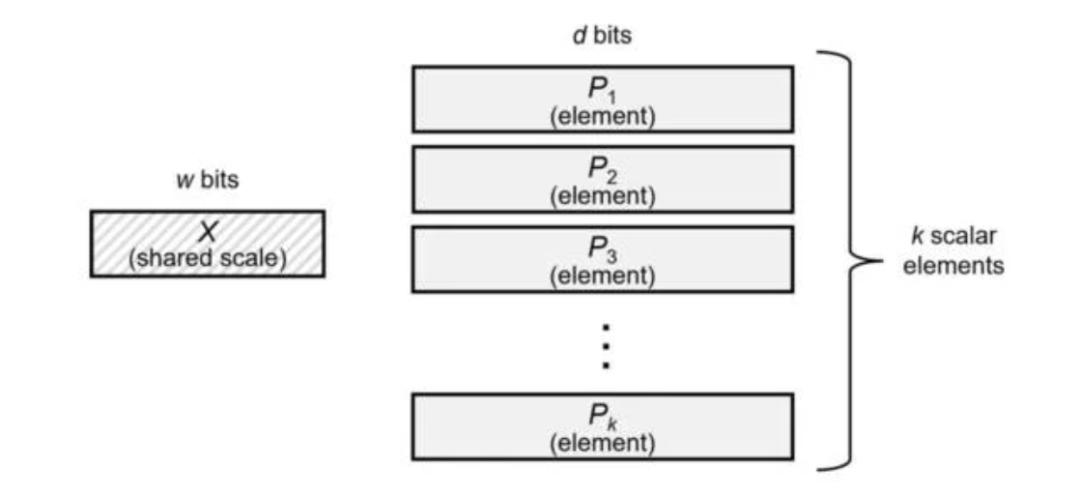
This achieves both the ultimate data size and maintains the precision of the size relationship between values.
In addition, the implementation of this process is also related to the computing hardware.
Generally, halving the floating - point precision doubles the floating - point throughput of the chip.
For example, the dense BF16 computing performance of a B200SXM module is approximately 2.2 petaFLOPS. After reducing to FP4 (with hardware acceleration provided by the Nvidia Blackwell chip), it can be increased to 9 petaFLOPS.
Although this will bring some improvement in throughput, during the inference stage, more FLOPS mainly means reducing the waiting time for the model to start generating answers.
It's worth noting that running an MXFP4 model does not require the hardware to natively support FP4.
The Nvidia H100 used to train gpt - oss does not support native FP4, but it can still run, although it cannot enjoy all the advantages of this data type.
Trade - off between low precision and computational volume
In fact, MXFP4 is not a new concept. As early as in the 2023 report, OCP introduced this data type in detail in the report "OCP Microscaling Formats (MX) Specification Version 1.0".
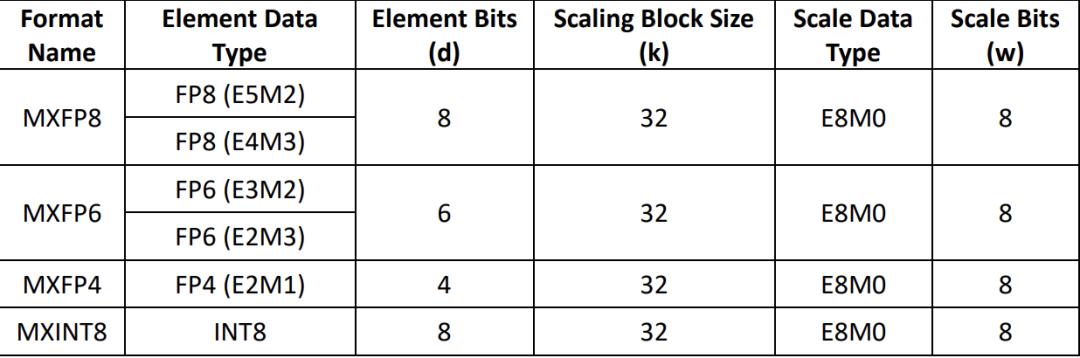
However, this low - precision data type is usually considered a compromise for cost - effectiveness because the decrease in precision will lead to quality loss. The degree of loss depends on the specific quantization method.
However, enough research has shown that reducing the data precision from 16 bits to 8 bits causes almost no quality loss in the scenario of large language models, and this precision is sufficient to support the normal operation of the model.
In fact, some model developers, such as DeepSeek, have begun to directly use FP8 for training.
In addition, although MXFP4 is much better than standard FP4, it also has defects.
For example, Nvidia believes that this data type may still experience quality degradation compared to FP8, partly because its scaling block size is 32, which is not fine - grained enough.
To this end, Nvidia has launched its own micro - scaling data type NVFP4, which improves the quality by reducing the scaling block size to 16 and using an FP8 scaling factor.
This is almost equivalent to the working mode of FP8. The only difference is that MXFP4 applies the scaling factor to small blocks within the tensor instead of the entire tensor, thus achieving a finer granularity between values.
Finally, on gpt - oss, OpenAI only uses MXFP4.
Given OpenAI's influence in the AI field, this basically means:
If MXFP4 is sufficient for us, it should also be sufficient for you.
Reference links
[1]https://www.theregister.com/2025/08/10/openai_mxfp4/
[2]https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
[3]https://www.opencompute.org/documents/ocp-microscaling-formats-mx-v1-0-spec-final-pdf
This article is from the WeChat official account "QbitAI", and is published by 36Kr with authorization.