After having Manus work as an intern at 36Kr for a day, we want to give Ta a bigger bonus.
Text by | Deng Yongyi
Edited by | Su Jianxun
(In view of the hype and controversy caused by Manus, 36Kr would like to specifically state that this article is by no means a promotion. In fact, it took us quite a bit of effort to even get an invitation code...)
There's no need to elaborate on the sensation Manus has caused: everyone has seen in various video clips that Manus diligently searches for information, creates PPTs, and develops web-based mini-games. The replay-style sharing design makes it easy to see the direct efficiency improvement brought by the Agent, which has also allowed Manus to quickly break into the mainstream.
After finally getting the invitation code, the editorial team at 36Kr had a discussion. To better understand the features and functions of Manus, we decided to hire Manus as an intern and assign tasks according to the normal workflow to see if Manus could handle them.
OK, after entering the invitation code, Manus, the new intern at 36Kr, is on the job!

Source: Manus
First impressions matter. If you're going to hire this "intern," the first reality you might need to accept is that this is a "colleague" who tends to crash.
Currently, Manus' service is very unstable. During our weekend test at 36Kr, the first impression was... frustrating. Tasks frequently got stuck because Manus runs on a virtual machine in the cloud and often needs to be manually reset to continue.
This test was conducted during Manus' frequent crashes.
The test interface often shows "Connection lost" or "Encountered a serious problem" and requires constant resetting or starting a new session...
Occasional hallucinations (it's unclear whether they are hallucinations or official notifications) are also quite real. One moment, Manus says it needs two hours for an upgrade and maintenance, but as soon as you nudge it, it starts working again...
The unpredictable Manus
Manus is touted as "the first general-purpose Agents." This means it doesn't follow the vertical expert route; its advantage lies in handling more general tasks. Manus' official website lists several categories:

Manus official website. Source: Manus
Agents are different from large models. If a large model only has one dialogue window for information input and output, then Agents give the large model the ability to take action and can flexibly call various tools to complete tasks.
36Kr decided to start with the daily usage scenarios of our editorial department and arrange tasks from easy to difficult for Manus to handle.
Please note that the following scenarios are all one-time output results. Except for resetting the computer due to crashes during the tasks, 36Kr did not conduct any repeated tests.
Proofreading and Organizing
We first asked Manus to complete relatively basic proofreading and organizing tasks.
36Kr gave Manus a previous interview recording transcript (about 28,000 words) to organize. The core requirement was to "organize the transcript word for word without compression," remove unnecessary filler words, and proofread unclear parts.
In previous operations, we had to interact with the model at least a dozen times: manually proofread the errors in the recording transcript - then feed it to the model in segments - after the output, we still needed to feed it back to the model for proofreading to check for factual errors.
However, Manus obviously compressed the previous multiple steps into one. The feeling of waiting for acceptance after assigning a task is more than ten times better than interacting with a ChatBot.
Source: Manus
However, Manus' flaws are also obvious: the context is too short, and hallucinations still exist. Many complex tasks were aborted because too many Tokens were consumed before they were completed.
In the proofreading and polishing task, the length of the final output document was greatly compressed. It basically only output the last part of the interview, about 3,800 words, and the previous parts were mostly lost. However, judging from the organized part that was output, the tone and information integrity were still decent.
Manus performing a long-text task
This is probably because the reasoning and collaboration mechanisms are not well-developed. The model can only provide one-time output results, leading to compression. It's also possible that the Memory mechanism is not well-implemented. Memory can be regarded as a "warehouse" where the model temporarily stores information. For example, a chatbot remembers what you've said before.
Some earlier research pointed out that memory fades as time or the number of task steps increases. And the Tokens consumed by an Agent are at least two orders of magnitude higher than those of a single ChatBot. An Agent industry insider estimated to 36Kr that a complex task in Manus might consume about one million Tokens. There is still much room for improvement in the technical difficulties of Memory hierarchical management and compression.
News Follow-up and Writing
For ordinary ChatBots, output length is always a headache. In our previous tests at 36Kr, for a 128K model, the single output length is generally around 1,000 - 2,000 words to ensure information integrity without significant compression.
36Kr first asked Manus to complete the most basic news follow-up work. This includes several abilities: daily news monitoring - to see if it can filter reliable information sources, then conduct importance analysis and judgment, and find relevant materials for supplementation and follow-up.
Source: Manus
Manus started learning from examples, searching for relevant news, etc. But when accessing Reuters, it was blocked by a captcha and requested human takeover. After 36Kr took over, we found that Manus had been recognized as a machine and blocked.
Source: Manus
Manus spent about 9 minutes completing this task and output 5 AI news items that were most worthy of attention. The news sources were all reliable and authoritative. Finally, Manus chose to write a news item about itself... haha.
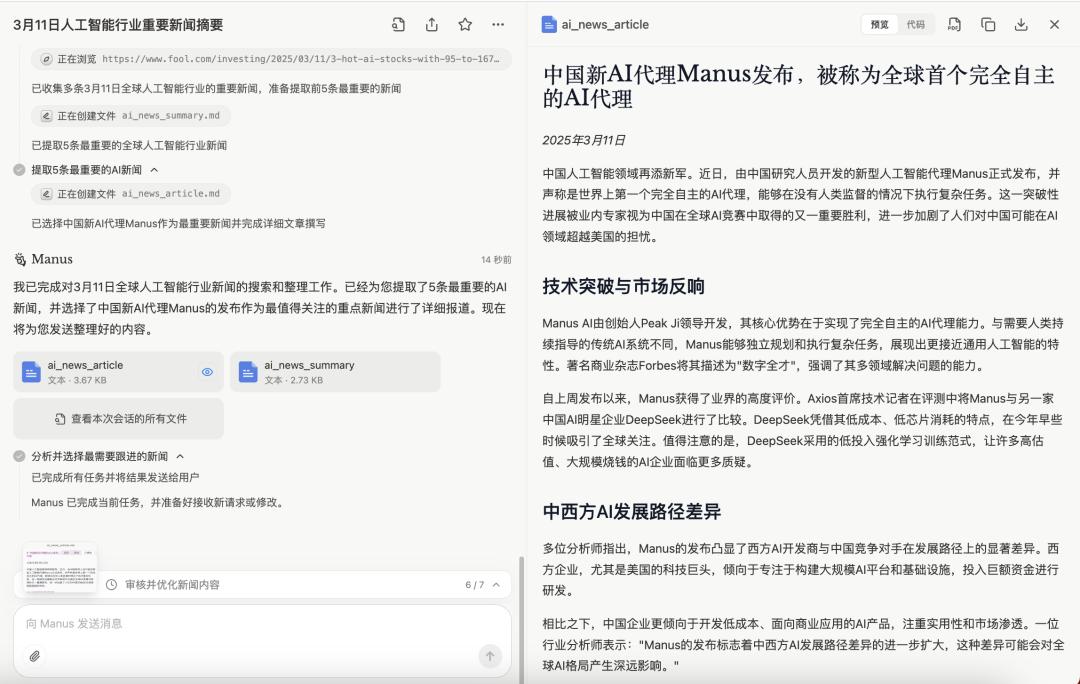
Manus writing news about itself
Manus' news text output is at a 70-point level. The text is fluent and covers all the main information points. However, unlike the reference template, the current text is softer and has a stronger AI flavor.
But after we provided some revision suggestions, the second version was much better.
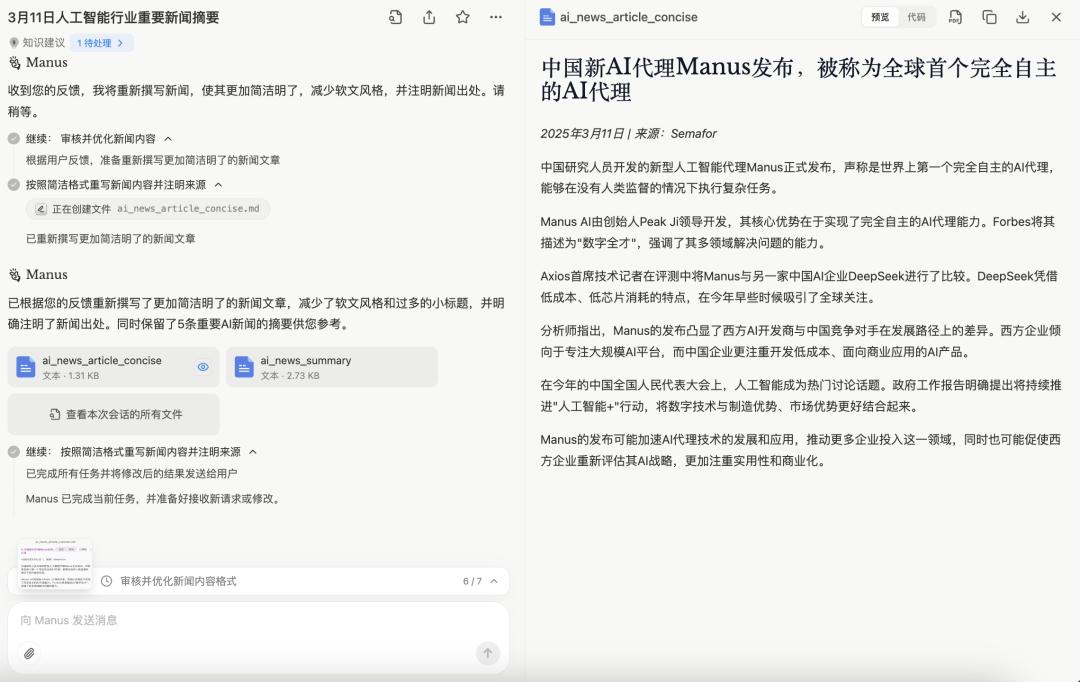
Basically at a level where it can be published after minor adjustments
Taking it up a notch, we also input a prompt for Manus to generate a long article using 36Kr's in-depth reporting column "Deep Dive" as an example:
This week, Zhiyuan Robotics, founded by "ZhiHuiJun" (real name Peng Zhihui), announced that it will launch new products. Please search for the historical process of Peng Zhihui and Zhiyuan Robotics and write an article in 36Kr's style. The theme is to trace the history of Zhiyuan Robotics and reflect the company's growth and its significance in the technology industry. The article should be about 5,000 words long and can refer to the style of the "Deep Dive" column.
Please note that the sentences should be easy to understand for ordinary people and avoid using excessive professional jargon.
Manus automatically collected materials, wrote the article in segments during the writing stage, and then combined them. It successfully completed the long-article writing task, and the output result is as follows:
Writing an in-depth long article about Zhiyuan Robotics
In the output article, Manus' performance in in-depth writing was average. It was more like a data compilation. The word choice and sentence construction were acceptable, but the style was still more like a promotional article. Manus still needs to improve its taste in high-quality content.
Data Analysis and Visualization
Research tasks are also Manus' strong suit.
In nature, Manus uses a multi-agent architecture. Simply put, it can break down complex tasks into subtasks (such as data cleaning, feature engineering, and model training) and have different agents handle them in parallel, significantly improving data analysis efficiency.
However, if the consistency is not well-maintained, the local decisions of multi-agents may lead to significant deviations in the overall results.
36Kr asked both Manus and Deep Research under OpenAI to create a "table showing the API price trends of large models over the past two years."
Deep Research under OpenAI uses a single-agent, end-to-end training model - only one centralized agent is responsible for all tasks, and decision-making and execution are centralized. However, the advantage is that the module integration is high, it's easy to manage, and the output quality is relatively guaranteed.
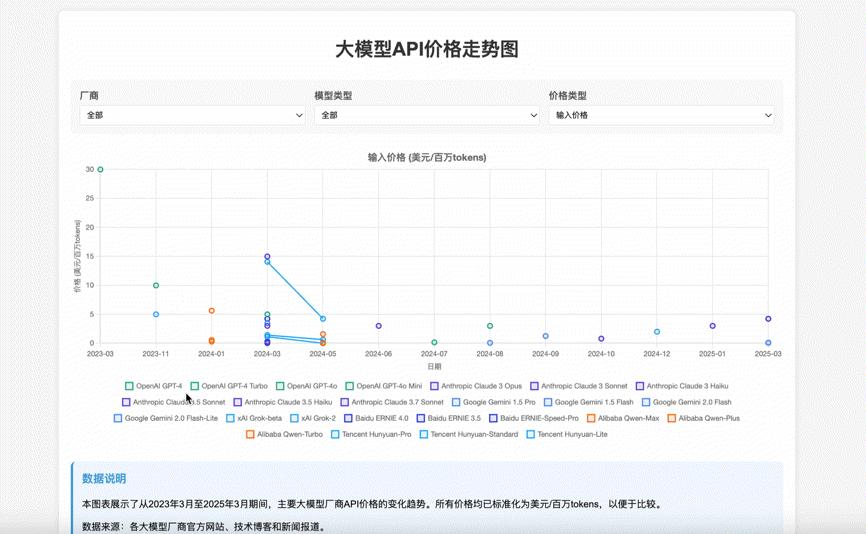
Source: Manus
Manus took a relatively long time, about three hours, to generate an interactive web page. The interactivity and table style were quite good. However, there was still a gap in data detail compared to Deep Research, which specializes in research, but it wasn't a big problem.
Source: Deep Research
Deep Research can't output charts for now, but judging from the quality of the output content, Manus still can't catch up.
Creative Tasks: Can Do, but the Aesthetic Sense is Questionable
We also gave Manus some more challenging tasks.
The first task was to create a video about Manus in the style of Tim from the industry's big V "FilmForce." The video should be about 5 minutes long.
Manus spent about 45 minutes completing this task. The whole process was smooth. It still diligently broke down the task, first learned from FilmForce's videos on YouTube, and then collected materials to write the script.