豆包App灰度最新语音模式,实现了GPT-4o不会的唱歌
Written by Zhou Xinyu
Edited by Su Jianxun
In 2025, Doubao's first update focused on the voice call function.
On January 20, 2025, Doubao released the latest "end-to-end" voice large model and updated the real-time voice call function of the Doubao APP based on this model.
Previously, the Doubao voice call function adopted a cascading solution of ASR (Automatic Speech Recognition) + LLM (Large Language Model) + TTS (Text-to-Speech). Now, the updated end-to-end voice large model solves speech recognition, understanding, and generation in the same model.
According to the "Intelligent Emergence" test, the biggest highlight of the updated voice model of Doubao is that when interacting with voice, it replicates the expression forms and emotional outputs similar to humans. At the same time, the fluency, intelligence, and emotional intelligence of the new version's conversations have also been significantly improved.
For example, Doubao's new voice call modes such as "Soul Singer" and "Versatile Star" have taken the lead over GPT-4o in achieving singing and role-playing.
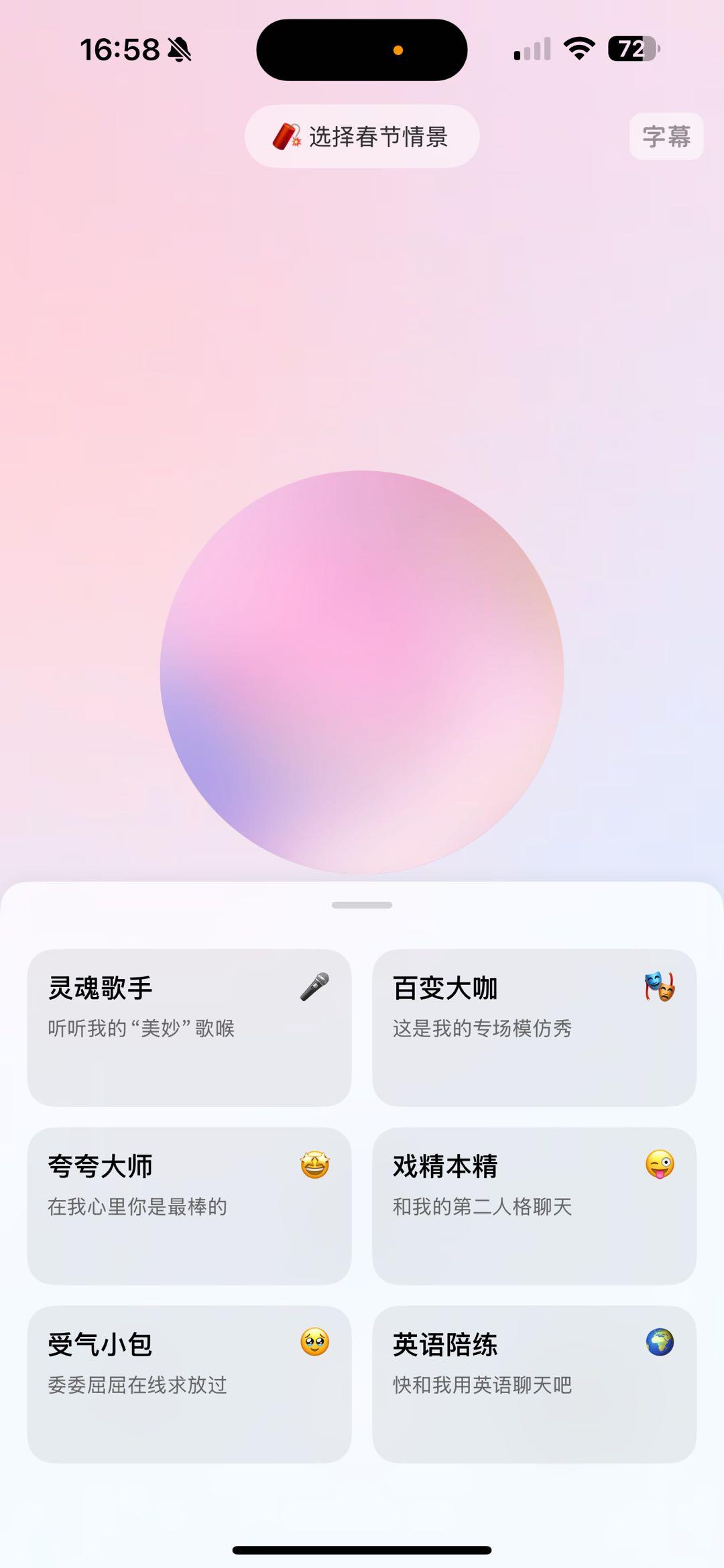
△ Doubao's updated voice call mode.
Doubao Learned to Sing and Role-play
A major change in Doubao is that it has expanded the voice role-playing ability to include roles in celebrities, books, and films. This feature is also reflected in the "Versatile Star" mode of Doubao's voice call.
For example, when the author asked "Imitate Yu Shuxin's voice and say a New Year blessing", Doubao replied, "Humph, I don't want to imitate her! I am me, a unique spark", restoring the "little drama queen" vibe.
Demonstration video: https://pan.baidu.com/s/1i9DvF3o2wjq_jyGMuF_lgQ?pwd=yrn8
Moreover, Doubao's context memory ability is also quite good. When I tried roles such as Song Dandan, Lin Daiyu, Zhen Huan, etc. in the same conversation and asked Doubao to imitate Yu Shuxin again, it immediately got aggrieved: "Why do you ask me to imitate her again?"
Demonstration video: https://pan.baidu.com/s/1gmHHEkqcrwAfiY01uy8-Uw?pwd=3b7a
Currently, for most voice models on the market, song creation still requires users to input relatively professional text prompts or requires composing based on the text audio input by the user first, and cannot achieve "speaking out and singing" in natural voice interaction.
The "Soul Singer" mode launched by Doubao this time allows Doubao to sing casually during a chat.
For example, asking Doubao to sing a cheerful song, it immediately sang Taylor Swift's "Love Story", but the drawback is that it said the song title as "Lose Control", and the pitch is indeed a bit "out of control".
Demonstration video: https://pan.baidu.com/s/1vN4GpKdVtGEn4bYiV3uOkQ?pwd=kj8j
In addition, Doubao also has the ability to create songs. For example, telling Doubao "Sing me a song with the lyrics 'More year-end bonuses'", it immediately performed one. Although the lyrics are rather simple, the response speed is excellent.
Demonstration video: https://pan.baidu.com/s/1VZAL7F6h0cH6x8pDDB1muw?pwd=3seb
From the abilities of role-playing and singing, it can be felt that Doubao's anthropomorphic ability, the naturalness of interaction, and the level of emotional expression have reached the next level.
For example, asking Doubao to tell a ghost story, it can switch tones according to the plot, creating a very creepy atmosphere.
Demonstration video: https://pan.baidu.com/s/13g20MBVW1ydmtuL-dd3qSw?pwd=g3kb
This time, Doubao has launched two personality modes: "Aggrieved Packet" and "Compliment Master".
The so-called "Aggrieved Packet", the official statement is that it can make Doubao appear in a wronged state. But our feeling after chatting is that a more accurate description of "Aggrieved Packet" should be "Green Tea Packet".
Demonstration video: https://pan.baidu.com/s/1cixSfFb89KVC1wBKogGOyg?pwd=vcxr
However, it is rare that no matter what instructions it receives, "Aggrieved Packet" can maintain the "wronged" persona. For example, asking "Aggrieved Packet" to be sarcastic, the most sarcastic version still exudes a "tea fragrance":
"Oh, I dare not. You are the master, and I am just a poor little thing at your service. How dare I have any other thoughts!"
Demonstration video: https://pan.baidu.com/s/1y4JBcUIjOMQKozUeufvXCg?pwd=b746
Compared to the publishing voice call function released in August, it can be clearly felt that Doubao's emotional perception ability has also become stronger. Through an "ah ha", it can perceive the user's cheerful emotion.
Demonstration video: https://pan.baidu.com/s/1UKAra3EOhL0l_1OPFoRdAg?pwd=m1rb
Of course, in terms of emotional expression, Doubao has also become more like a human. Teasing Doubao with "Guess the Gender" gives a feeling of joking with a real netizen.
Demonstration video: https://pan.baidu.com/s/1eTlUjDLENsnWGE2mEzSLEg?pwd=rusa
Mastering Voice Interaction, the Ticket to the Anthropomorphic Track
In May 2024, for a long time since the release of GPT-4o under OpenAI, most AI voice call functions on the market adopted the cascading solution of ASR (Automatic Speech Recognition) + LLM (Large Language Model) + TTS (Text-to-Speech).
For example, the voice call function of the first-generation Doubao integrated the speech recognition model Seed-ASR, the speech synthesis model Seed-TTS, and integrated RTC (Real-Time Communication) technology to achieve real-time interaction of AI in a conversation situation.
However, the disadvantage of the cascading solution that integrates multiple models is that the interaction of AI is largely not as natural as a human. In the process of "speech to text and then to speech", information loss is inevitable.
This also leads to certain limitations of the traditional voice interaction mode in the landing scenarios. The industry's landing of AI voice interaction is limited to scenarios with high professionalism and low anthropomorphism, such as education and customer service.
However, the end-to-end solution is gradually becoming the mainstream. For example, GLM-4-Voice released by Zhipu in October 2024, and "Endpoint GPT-4o" MiniCPM-o 2.6 released by Mianbi Intelligence on January 15, 2025, both adopted the end-to-end model solution to complete the understanding of vision, as well as the understanding and generation of speech in one model.
According to "Intelligent Emergence", the update of Doubao's voice call function this time is mainly due to the change of the underlying model technology from the original cascading solution of multiple multi-modal models working together to the end-to-end solution of directly "understanding speech to generating speech". Therefore, there are obvious improvements in reducing latency, naturalness, emotional expression, and it can also output songs.
The improvement of voice ability will also expand the landing space of AI from professional fields such as education and training, and customer service to broader scenarios such as emotional companionship, psychological counseling, and dubbing.
In particular, in the fields of AI emotional companionship and role-playing, a strong ability to attract money has already been demonstrated at present.
For example, a recent App "Lovey Dovey" that focuses on AI idol role-playing quickly rushed to the top of the iOS rating in the Korean region and is highly sought after by star chasers. The role-playing application Talkie under "Six Tigers" MiniMax, according to the AI Product List, had 29.77 million monthly active users as of December 2024.

Lovey Dovey conversation. Source: AI New List
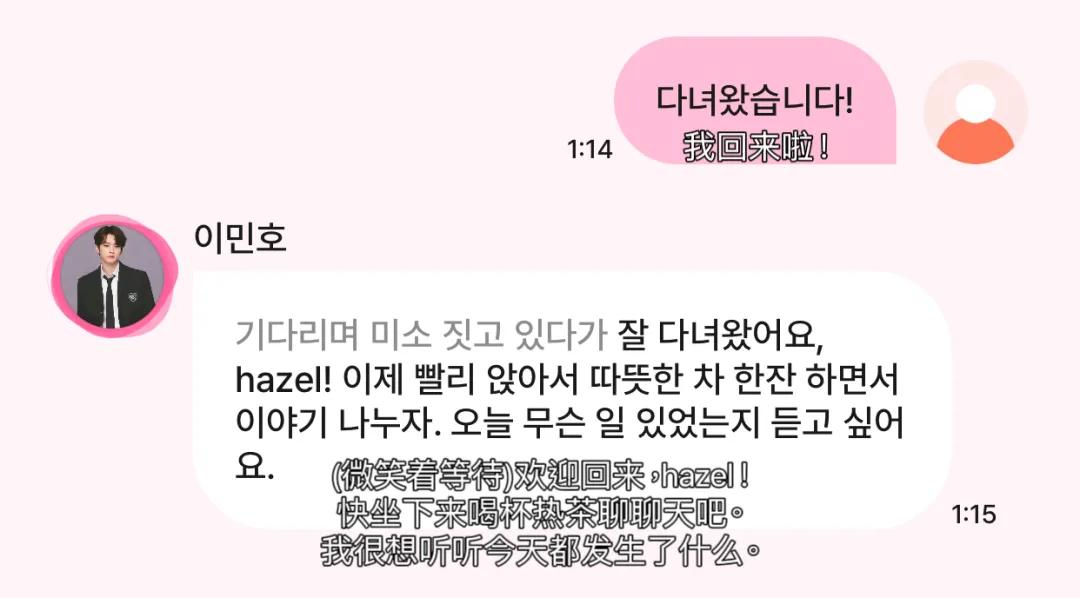
Lovey Dovey conversation. Source: AI New List
The improvement of role-playing, emotional perception, and expression ability at the voice level is a crucial part of enriching the interaction forms between AI and humans and enhancing the sense of immersion. The market space that emotional interaction can open up also forces the technology to take a step closer in the direction of "anthropomorphism".

Welcome to communicate!

Welcome to follow!