Bringen gute Lehrer immer hervorragende Schüler hervor? Das neueste Revelation einer Tsinghua-Universität-Team: Hör auf, an das "kostenlose Mittagessen" der Large Language Model-Distillation zu glauben!
Dieser Artikel wurde von Forschern aus dem THUNLP-Labor der Tsinghua-Universität in Zusammenarbeit mit mehreren Institutionen wie der ShanghaiTech-Universität, der University of Illinois at Urbana-Champaign und der Renmin-Universität China erstellt.
Is die "kostenlose Mahlzeit" der Distillation wirklich lecker?
In der aktuellen Post-Training-Pipeline von großen Modellen ist die On-Policy Distillation (OPD) zu einer Star-Technologie geworden. Von Qwen3, MiMo bis hin zu GLM-5 haben Unternehmen OPD eingesetzt und über enorme Leistungsteigerungen berichtet. Im Vergleich zu den spärlichen Ergebniserlösen bei der Reinforcement Learning (RL) bietet die OPD dichte Token-Level-Überwachungssignale, was wie eine "kostenlose Mahlzeit" aussieht.
Aber wenn Sie die OPD selbst ausprobiert haben, könnten Sie ein kontra-intuitives Phänomen beobachten: Warum verbessert sich die Leistung des Studentenmodells nicht, sondern verschlechtert sich sogar, wenn ich einen stärkeren Lehrermodell einsetze?
In der Ära der großen Modelle ist die Distillation längst nicht mehr einfach "mehr Kraft bringt Wunder".
Eine neueste Studie des Tsinghua-Teams hat das Schwarze Brett der On-Policy Distillation systematisch erforscht. Diese Studie enthüllt nicht nur zwei entscheidende Vorbedingungen für den Erfolg der Distillation, sondern gründet auch in die Token-Level-Ausrichtungsmechanismen und gibt eine praktische Rezeptur zur Rettung fehlgeschlagener Distillationen.
📄 Link zur Studie: https://arxiv.org/abs/2604.13016
💻 Code-Repository: https://github.com/thunlp/OPD
𝕏 Thread: https://x.com/HBX_hbx/status/2044464414829777354
Phänomen: Warum kann ein "guter Lehrer" keinen "guten Schüler" ausbilden?
In der herkömmlichen Vorstellung sollte die Distillationseffektivität umso besser sein, je höher die Punktzahl des Lehrermodells ist. Aber das Forschungs-Team hat durch rigorose Vergleichsexperimente zwei Kernregeln für das Schicksal der OPD entdeckt:
Regel 1: Denkmodus-Konsistenz (Thinking-Pattern Consistency)
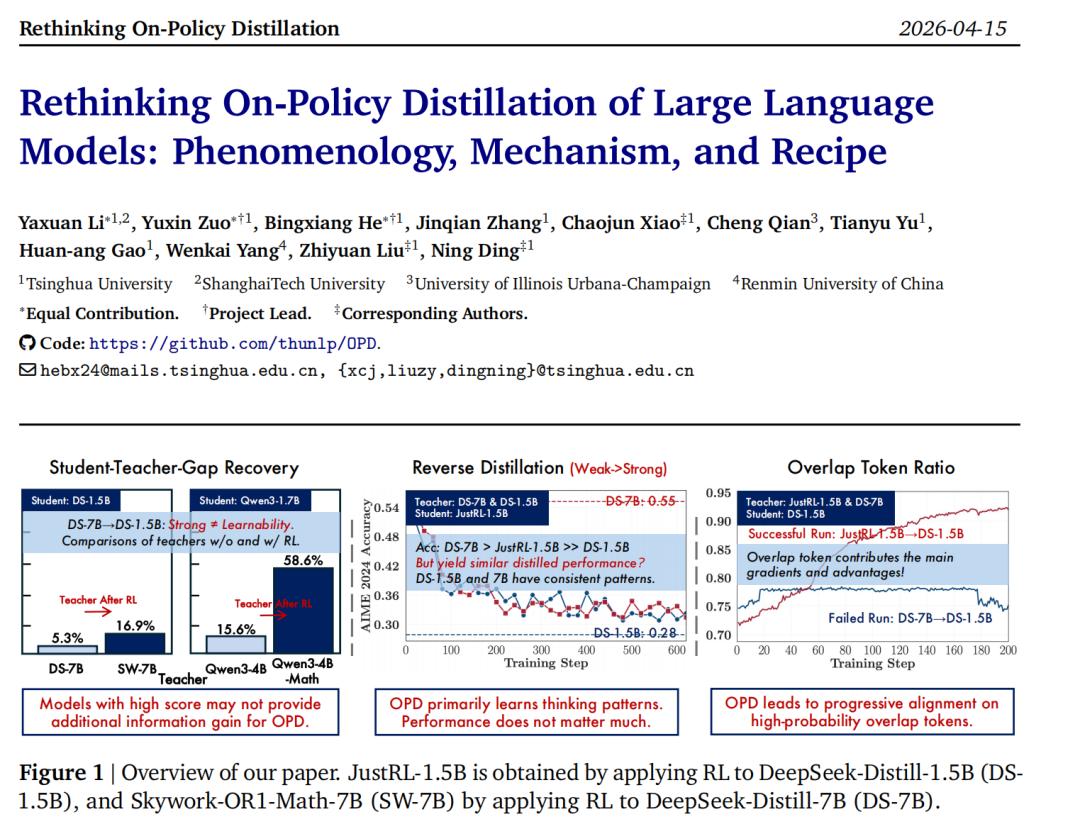
Die Forscher ließen das schwache Basismodell Qwen3-1.7B-Base von zwei Lehrermodellen mit ähnlicher Fähigkeit lernen: einem Qwen3-4B (Non-thinking) und einem Qwen3-4B-Base-GRPO, das nur mit GRPO trainiert wurde. Es stellte sich heraus, dass, da der Schüler auch ein Basismodell ist, sein Denkmodus näher an dem des mit GRPO verstärkten Basislehrers liegt (höhere anfängliche Überlappungsrate), und die endgültige Distillationseffektivität deutlich verbessert wurde. Wenn der Denkmodus in der frühen Phase fehlausgerichtet ist, ist es später schwer, dies vollständig auszugleichen.

Regel 2: Höhere Punktzahl ≠ neues Wissen (Higher scores ≠ new knowledge)
Wenn der Denkmodus von Lehrer und Schüler übereinstimmt und der Lehrer eine höhere Punktzahl hat, funktioniert die Distillation dann immer?
Die Forscher haben in beiden Familien, DeepSeek und Qwen, dasselbe Phänomen beobachtet: Ein größeres Lehrermodell aus derselben Pipeline und demselben Rezept bringt nur eine sehr begrenzte Verbesserung; im Gegenteil, ein Lehrer, der durch zusätzliches RL-Post-Training trainiert wurde, kann die Lücke zwischen Lehrer und Schüler besser schließen. Beispielsweise in der DeepSeek-Familie beträgt die Lückenreduktion des RL-trainierten Skywork-OR1-Math-7B 16,9%, während die des DeepSeek-R1-Distill-7B aus derselben Pipeline nur 5,3% beträgt; in der Qwen-Familie beträgt der Unterschied sogar 58,6% gegenüber 15,6%.
Dies zeigt, dass, wenn der Lehrer nur größer ist, aber aus derselben Pipeline, demselben Datensatz und demselben Rezept stammt, er im Auge des Schülers möglicherweise nur eine "andere Skalierung der gleichen Verteilung" ist und nicht viel neues, übertragbares Wissen bietet.

Das härteste Experiment: "Zurückdistillieren" des Schülers
Die Forscher haben ein extremes "Rückwärts-Distillationsexperiment" durchgeführt: Sie haben das JustRL-1.5B-Modell nach RL als Schüler genommen und es lernen lassen, von seinem eigenen Checkpoint R1-Distill-1.5B vor der RL zu lernen; gleichzeitig haben sie ein größeres und punktzahlstärkeres Modell derselben Familie, R1-Distill-7B, als Vergleich herangezogen.
Das Ergebnis war überraschend: Das Lernen vom 7B-Modell und vom 1.5B-Modell hatte fast denselben Effekt - beide führten dazu, dass die Fähigkeiten des Schülers auf das Niveau vor der RL zurückfielen, und die Abnahme-Kurven waren sehr ähnlich! Dies zeigt, dass das 7B-Modell zwar eine höhere Punktzahl hat, aber im Vergleich zum 1.5B-Modell nur den Vorteil der größeren Parameteranzahl bietet und dem Schüler keine zusätzlichen lernbaren Informationen gibt. Die OPD lernt nicht einfach "höhere Punktzahlen", sondern extrahiert und repliziert aktiv den Denkmodus des Lehrers.

Mechanismus: Was zeigt das Mikroskop auf Token-Level?
Was passiert auf Token-Level, wenn die OPD erfolgreich oder fehlschlägt?
Die Forscher haben die dynamischen Indikatoren während des gesamten Trainings überwacht und eine sehr klare Regel entdeckt: Erfolgreiche Distillation ist eine "zweiseitige Annäherung" von Token mit hoher Wahrscheinlichkeit.
Bei erfolgreicher OPD steigt die Überlappungsrate (Overlap Ratio) der ersten k vorhergesagten Token von Schüler und Lehrer von 72 % stetig auf über 91 % an, während die Entropie-Lücke (Entropy Gap) zwischen ihnen schnell schrumpft. Bei fehlgeschlagener OPD ändern sich diese Indikatoren von Anfang bis Ende kaum.

Die wichtigste Entdeckung ist: Der "Überlappungsbereich" ist alles.

Die Forscher haben das Distillationsziel aufgeteilt und ein Experiment durchgeführt. Sie haben festgestellt, dass die Token mit hoher Wahrscheinlichkeit, die sowohl von Lehrer als auch von Schüler bevorzugt werden, der Kernmotor der gesamten Optimierung sind und den Hauptgradienten und die Vorteile liefern. Wenn man nur die Verlustfunktion für diese Überlappungs-Token berechnet, nimmt die Distillationsleistung fast nicht ab! Die nicht überlappenden Token tragen fast nichts zur Optimierung bei.
Rezept: Zwei Wege, um fehlgeschlagene Distillation zu retten
Wenn man nur einen Lehrer mit unpassendem Denkmodus zur Verfügung hat, ist das nicht unbedingt aussichtslos. Basierend auf den oben genannten Phänomenen und Mechanismen haben die Forscher zwei "zielgerichtete" Rezepturen vorgeschlagen:
1. Off-Policy-Kaltstart (Cold Start) auf der Lehrer-Rollout
Da eine direkte On-Policy Distillation leicht zu einer Fehlausrichtung des Denkmodus führt, kann man zunächst eine Off-Policy-Ausrichtung erzwingen. Bevor man mit der OPD beginnt, lässt man den Schüler zunächst eine leichte SFT auf den von dem Lehrer erzeugten Rollouts durchführen. Dies erhöht direkt die anfängliche Überlappungsrate, und die anschließende OPD-Training kann reibungslos starten, und die endgültige konvergierte Leistung kann die reine OPD-Basislinie übertreffen.

2. Lehrer-ausgerichtete Prompts
Da die Strategie des Lehrers auf einer bestimmten Art von Post-Training-Prompts geformt wurde, sollte man die OPD so weit wie möglich an Prompts ausgesetzt werden, die der Trainingsverteilung des Lehrers näher sind, einschließlich der Ausrichtung auf Template-Ebene und Inhalts-Ebene. Die Studie hat gezeigt, dass dies tatsächlich die Genauigkeit und das Wachstum der Überlappung verbessern kann; aber der Preis dafür ist, dass die Entropie des Schülers schneller sinkt, daher ist es am besten, diese Prompts mit einem Teil von OOD-Prompts zu mischen, um ein vorzeitiges Entropiekollaps zu vermeiden.

Template-Ausrichtung

Inhalts-Ausrichtung
Diskussion und Reflexion: Kann die OPD unendlich skaliert werden?
Die kostenlosen dichten Belohnungssignale sind sicherlich verlockend, aber die Forscher haben festgestellt, dass die Qualität der Belohnungssignale mit zunehmender Trajektientiefe stark abnimmt.
In einer 15K-Token-Antwort haben die Forscher ein deutliches "Entropiekollaps von hinten nach vorne" beobachtet: Mit zunehmender Generierung weicht der Präfix des Schülers immer mehr von der vom Lehrer bekannten Verteilung ab, was dazu führt, dass die Belohnungen, die der Lehrer in der zweiten Hälfte gibt, reine Rauschen werden und somit das gesamte Training kollabiert. Dies zeigt, dass es derzeit schwierig ist, die OPD direkt auf lange Denkketten oder agentische Mehrfachrundenszenarien auszuweiten. Es besteht eine grundlegende Spannung zwischen dichter Überwachung und Überwachungszuverlässigkeit.

Außerdem bedeutet ein global nützliches Belohnungssignal nicht, dass es lokal effektiv optimiert werden kann. Die globalen Belohnungen, die von einem fehlgeschlagenen Lehrer gegeben werden, sind eigentlich nicht schwach, und die AUROC zur Unterscheidung zwischen richtigen und falschen Rollouts ist sogar ähnlich wie die eines erfolgreichen Lehrers. Dies zeigt, dass das Scheitern nicht daran liegt, dass das Belohnungssignal selbst keine Informationen enthält, sondern daran, dass die lokale Optimierungsgeometrie der Belohnungsproblematik fehlerhaft ist - global gibt es Informationen, lokal ist es jedoch flach.
