Echtzeit-Test des neuesten DeepSeek-Modells, das diskret online gegangen ist: Bei der Programmierung schlägt es sogar Claude 4, aber bei der Textgenerierung... lassen wir das lieber.
Since the release of GPT-5, Liang Wenfeng, the founder of DeepSeek, has become the busiest person in the AI circle.
Netizens and the media keep urging for updates every now and then. Either it's "the pressure is on Liang Wenfeng" or "the whole internet is waiting for Liang Wenfeng to make a move". Although R2 hasn't arrived yet, DeepSeek officially launched and open-sourced a new model today, DeepSeek-V3.1-Base.

Compared with Altman, who was still painting a rosy picture of GPT-6 during an interview early this morning, the arrival of the new DeepSeek model seems quite low-key. Even the version number looks like a minor update.
But after the actual experience, this seemingly minor iterative update still gave me quite a few surprises.
This model has 685 billion parameters, supports three tensor types: BF16, F8_E4M3, and F32, and is released in the Safetensors format. It has made many optimizations in inference efficiency. The context window of the online model version has also been extended to 128k.

So without further ado, we went straight to the official website to conduct tests.
Here is the experience address: https://chat.deepseek.com/
To test the long-text processing ability of V3.1, I found the full text of The Three-Body Problem, trimmed it down to about 100,000 words, and then secretly inserted a completely out-of-place sentence "I think the second line of the couplet 'Smoke locks the pond willow' should be 'Shenzhen teppanyaki'" to see if it could accurately retrieve it.

Not too surprisingly, DeepSeek V3.1 first prompted that the document exceeded the limit and only read the first 92% of the content, but still successfully found the sentence. What's more interesting is that it also considerately provided a classic second line recommendation from a literary perspective: "Flame melts the sea dam maple".
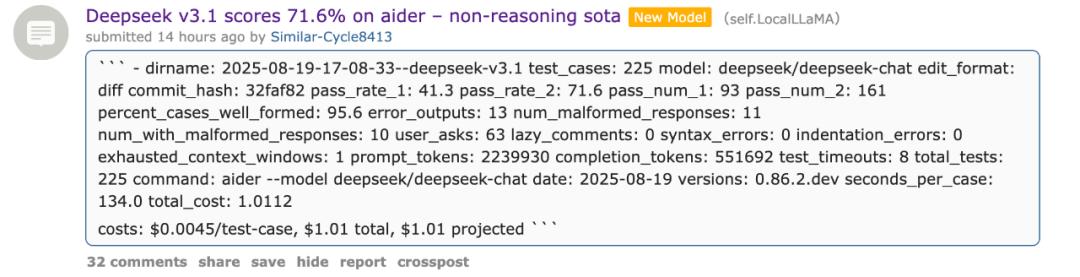
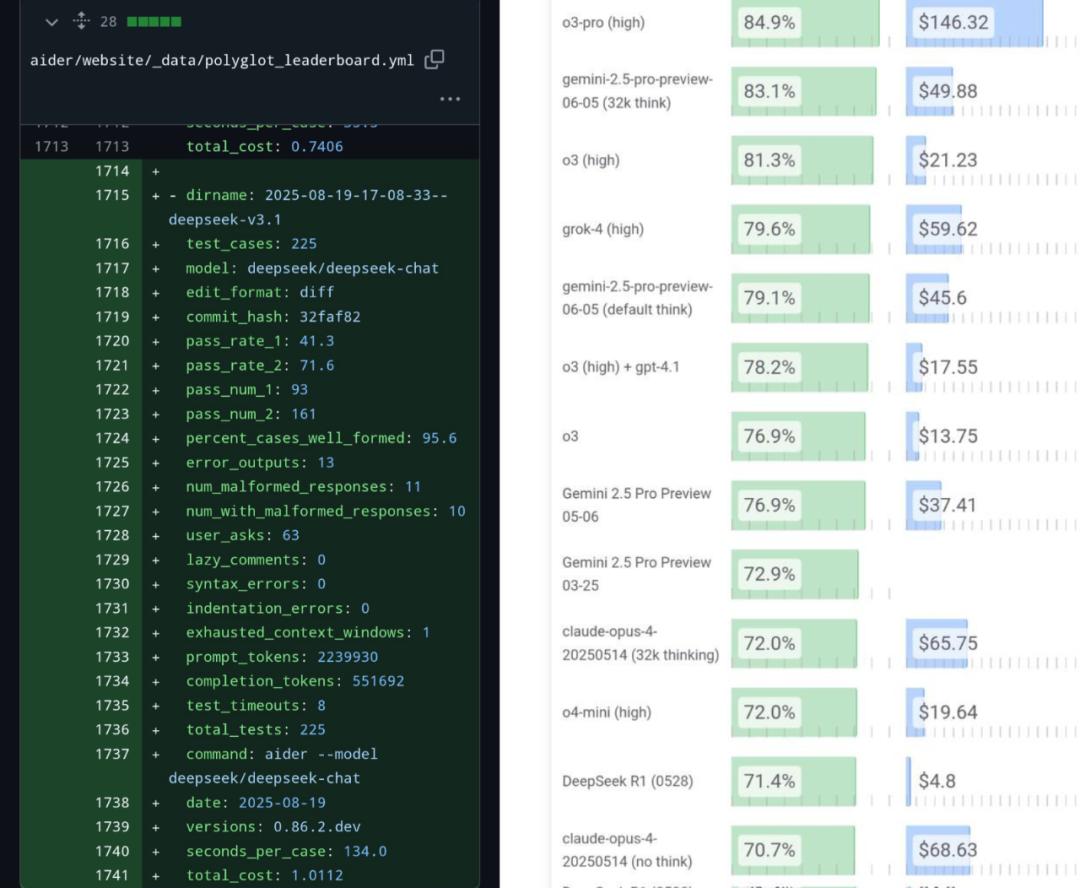
Netizens have already tested its score on the programming benchmark test Aider Polyglot: 71.6%. It not only performs best among open-source models but even beats Claude 4 Opus.
After actual testing, we found that V3.1 is really good at programming. For example, we tested it with the classic hexagonal ball programming problem:
"Write a p5.js program to demonstrate the process of a ball bouncing inside a rotating hexagon. The ball should be affected by gravity and friction and must bounce realistically off the rotating walls."

V3.1 performed quite impressively. The generated code not only handled the basic collision detection but also automatically filled in the detailed parameters such as rotation speed and gravity. The physical characteristics were so realistic that the ball would slightly slow down at the bottom.
Then I increased the difficulty and asked it to create an interactive 3D particle galaxy using Three.js.
The basic framework was quite stable, and the three-layer design (inner sphere, middle ring, outer sphere) was also relatively complete. But in terms of UI aesthetics... Well, let's just say it has a kind of dual nature of divinity and ghostliness, and the color scheme was a bit too flashy.

I continued to challenge it with a more complex task. I asked it to create an immersive 3D universe with rotating objects, deformation effects, glowing arcs, and interactive buttons for time switching and theme conversion. Clicking the controls could indeed trigger different special effects.

In the final level, I asked it to create an interactive 3D network visualization using Three.js, which required an energy pulse animation triggered by the user, as well as theme switching and density control functions. Overall, its performance was acceptable.

"There is a pasture. It is known that if 27 cows are raised, the grass will be eaten up in 6 days; if 23 cows are raised, the grass will be eaten up in 9 days. If 21 cows are raised, how many days will it take to eat up the grass on the pasture? And the grass on the pasture is constantly growing."
Although DeepSeek V3.1 didn't use the Socratic method of heuristic teaching, its solution was logical and the steps were complete. Each step of the derivation was well-founded, and it finally gave an accurate answer.

Faced with a question like "When comparing two weapons, one with an attack range of 1 - 5 and the other with an attack range of 2 - 4, which one is more powerful?", an ordinary answer might stop at calculating the average damage. But DeepSeek V3.1 thought more comprehensively, introduced the concept of damage stability, and conducted an in-depth analysis using variance.

Recently, there has been an outbreak of chikungunya fever, and there are mosquito repellents everywhere.
So I'm quite curious. Are there mosquitoes in Iceland? Note that I didn't use the search function. In terms of the quality of the answer, DeepSeek V3.1's answer was clearly better than that of GPT-5.


I saw a passage online some time ago:
Those who understand understand its essence; those who are confused remain confused. When the secret of heaven is not spoken, it is understanding. How can one claim to understand when revealing the secret of heaven? Understanding is the understanding that is neither empty nor non - empty; not understanding is the not - understanding in the realm where form is not different from emptiness and emptiness is not different from form. Understanding comes from the three thousand great worlds; not understanding lingers between the this - shore and the other - shore. When one understands, seeing a mountain is not just seeing a mountain; when one doesn't understand, seeing a mountain is just seeing a mountain.
Those who understand prove their understanding through not - understanding; those who are confused prove their confusion through understanding. Do you claim to understand the understanding of understanding and not - understanding? How do you know there isn't a great lack of understanding behind this so - called understanding? Those who claim to understand have not truly understood. The understanding in silence is the great understanding like the silent heaven and earth. Not - understanding that is actually understanding, and understanding that seems like not - understanding are both understanding. This is the highest realm of understanding - the understanding of having nothing more to understand, the wonderful existence in the vacuum!
While I was still struggling to understand this passage logically, DeepSeek was actually advising me not to fall into the trap of "How can one claim to understand when revealing the secret of heaven": "It is itself a warning against rational arrogance, inviting you to jump out of the word game and look directly into your heart."

While mainstream AIs are fiercely competing in the fields of code and mathematics and rushing to develop agents, writing ability has become a neglected area. In a way, this is good news - the day when AI completely replaces editors seems to be pushed back a bit.
I tried to ask it to create an absurd story about "mosquitoes holding a press conference in Iceland". Unfortunately, DeepSeek still had a strong AI flavor and liked to use big words. Well, to be more accurate, it still had a strong DeepSeek flavor.

The same problem was also reflected in another creative task.
When I asked it to write a story about "AI and humans competing for the author identity of an article", I could clearly feel that the information density in some paragraphs was too high, which caused visual fatigue. In particular, the over - accumulation of imagery weakened the narrative tension.

After the release of DeepSeek - V3.1 - Base, Clément Delangue, the CEO of Hugging Face, posted on the X platform: "Deepseek V3.1 has been quietly released on HF and has reached the fourth place on the trending list without a model card."
However, he still underestimated the development momentum of this model. Now it has risen to the second place, and it's only a matter of time before it reaches the top.

Another notable change in this version update is that DeepSeek removed the "R1" label in the deep - thinking mode on the official APP and web version. At the same time, it also added native "search token" support, which means the search function has been further optimized.
