Die "Actuarial-Ära" der KI hat offiziell begonnen, und NVIDIA hat den ersten Schuss abgegeben.
In the field of AI, small models are having their moment in the spotlight. From the new AI vision model released by Liquid AI, a subsidiary of MIT, that can fit into a smartwatch, to models that can run on Google smartphones, miniaturization and high efficiency have become prominent trends. Now, NVIDIA has also strongly joined this wave, bringing a brand - new small language model (SLM) —— Nemotron - Nano - 9B - v2. This model not only achieves the highest performance among its peers in selected benchmark tests but also has the unique ability to allow users to freely turn on and off AI "inference", opening up new possibilities for AI applications.
From Edge Toys to Production Workhorses: The Rise of "Small" Models
In the past three months, the "mini - army" in the AI circle has made successive breakthroughs, triggering a silent revolution. The vision model launched by Liquid AI, a subsidiary of MIT, is so small that it can easily fit into a smartwatch, taking the intelligent experience of wearable devices to a new level. Google has successfully integrated Gemini - Nano into the Pixel 8 phone, achieving a qualitative leap in mobile - end AI capabilities. Now, NVIDIA has entered the scene with the 9 - billion - parameter Nemotron - Nano - 9B - v2, deploying it on a single A10 GPU and once again reshaping people's perception of small models.
This is by no means just a "small and beautiful" technological showcase but an experiment in precisely balancing cost, efficiency, and controllability. As Oleksii Kuchiaev, the post - training supervisor of NVIDIA's AI models, said bluntly on X: "Reducing the parameters from 12 billion to 9 billion is specifically for the A10, which is the most common graphics card in enterprise deployments."
In a nutshell, the size of parameters is no longer the key performance indicator for measuring the quality of a model. Return on investment (ROI) is what really matters.
Making the Thinking Chain a Billable Feature
The "black - box thinking" of traditional large models has always been a pain point for enterprises. Once long - term inference is triggered, the token bill can get out of control like a runaway horse. Nemotron - Nano - 9B - v2 offers a simple, direct, and efficient solution:
By adding /think to the prompt, the model will activate its internal thinking chain and derive step by step like a human being. Adding /no_think will make it directly output the answer, skipping the intermediate steps. The system - level max_think_tokens function, similar to AWS's CPU credit mechanism, can set a budget for the thinking chain, precisely controlling costs.
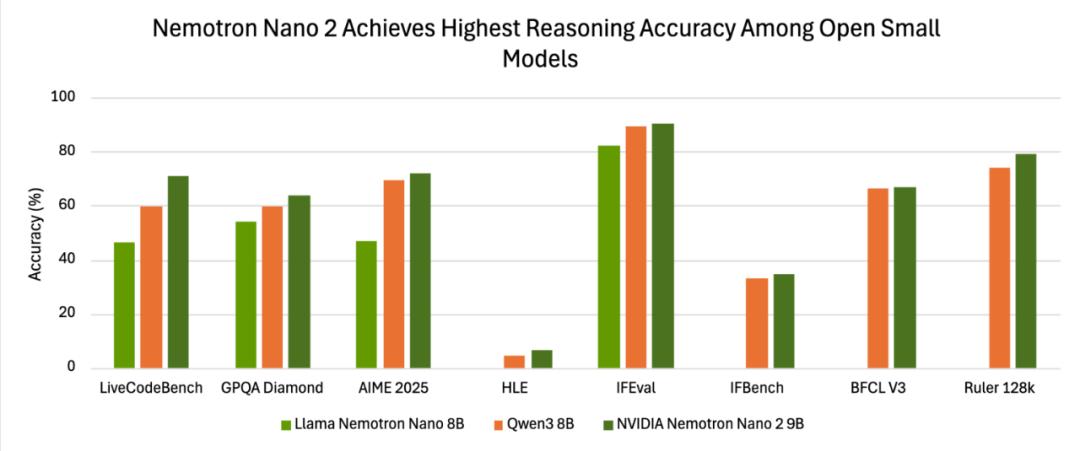
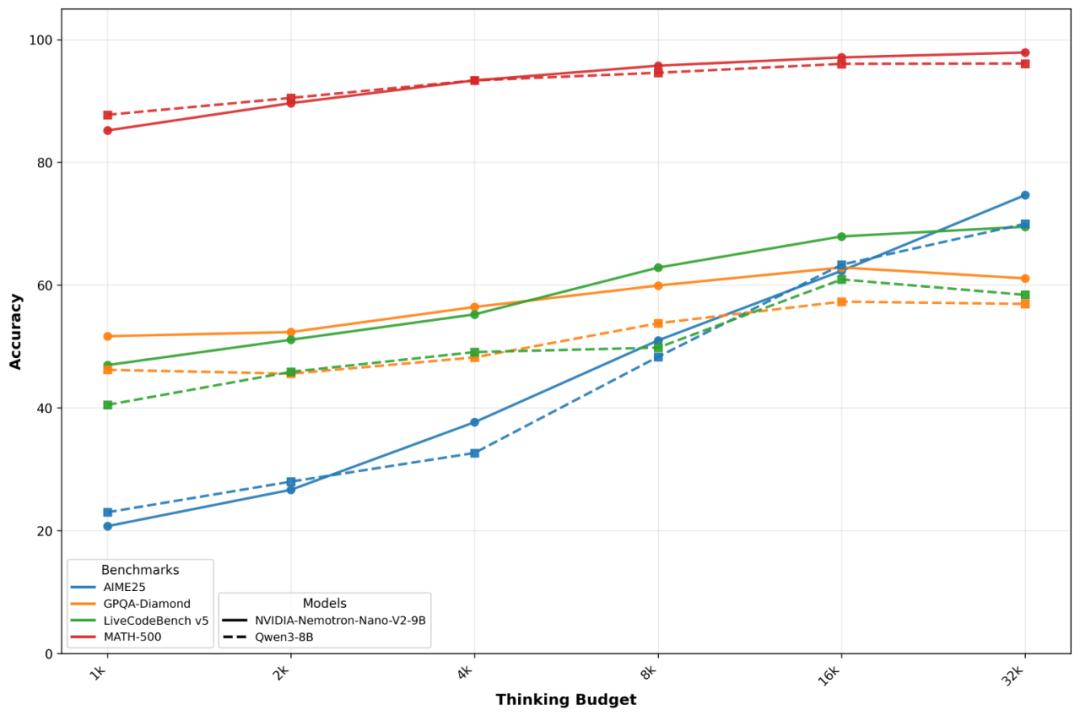
On - site testing (official report) data can better illustrate the point:
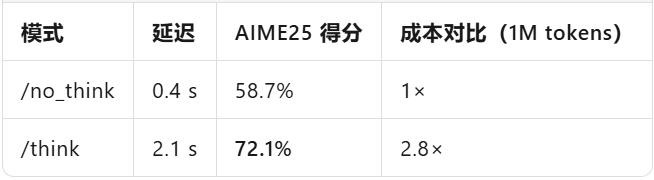
In a nutshell, turning "inference" from a default ability into an optional feature, enterprises can, for the first time, pay according to the depth of thinking, just like buying cloud storage.
The "Fuel - Saving" Patch for Transformer
Why can a 9B model perform as well as a 70B model in long contexts? The answer lies in the Mamba - Transformer hybrid architecture:
Replacing 70% of the attention layers with Mamba state - space layers results in a 40% reduction in video memory usage.
The relationship between sequence length and video memory is linear, rather than exponentially explosive.
In a 128k token test, the throughput is 2.3 times higher than that of a pure Transformer of the same size.
In a nutshell, Mamba doesn't replace Transformer but transforms it into a fuel - efficient hybrid engine.
The Commercial Nuclear Bomb: Loose Licensing + Zero - Threshold Commercial Use
NVIDIA's move in the licensing agreement this time can be called a "commercial nuclear bomb", achieving "three no - no's":
No cost: There are no royalties or revenue sharing, and enterprises don't need to pay additional fees for using the model. No negotiation: Enterprises can directly download and use it commercially, eliminating the cumbersome cooperation negotiation process. No legal anxiety: It only requires compliance with trustworthy AI safeguards and export regulations, reducing the legal risks for enterprises.
Compared with OpenAI's tiered licensing and Anthropic's usage limits, Nemotron - Nano - 9B - v2 has almost become the "AWS EC2 of the open - source world" —— it can be used immediately to generate revenue, greatly lowering the threshold for enterprises to use it.
Scenario Slicing: Who Benefits First?
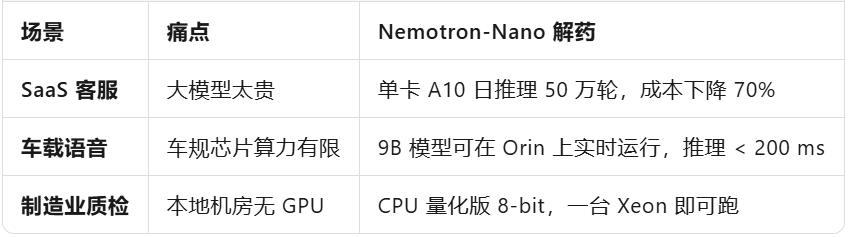
In a nutshell, any edge/private scenario now has an option that is "smart enough and affordable".
The "Actuarial Era" of AI Officially Begins
In the past four years, we have witnessed the magic of the scaling law: parameters × computing power = performance. Today, Nemotron - Nano - 9B - v2 tells us with its 9 - billion parameters that architecture × control × licensing = sustainable AI economy.
When Liquid AI fits a model into a watch and NVIDIA turns inference into an on - off switch, "small" is no longer a technical compromise but the optimal solution after careful calculation.
In the next financing roadshow, entrepreneurs may no longer say "We are better than GPT - 4" but will confidently claim: "We achieve 90% of the results with 1/10 of the computing power and still make a profit." This marks the official start of the "actuarial era" of AI.
This article is from the WeChat official account "Shanzi", written by Rayking629 and published by 36Kr with authorization.