Sequoia Century: Wie definiert man in der zweiten Hälfte der AI-Ära die "guten Fragen"? | WAVES - Neue Welle 2025
WAVES New Wave 2025 lädt Sie ein, gemeinsam in die „Neue Ära“ des chinesischen Risikokapitals zu gehen.
Dies ist die neue Ära des chinesischen Risikokapitals. Der gegenwärtige chinesische Risikokapitalmarkt ist sowohl der Wendepunkt des Zyklusbodens als auch die Phase der Vertiefung der strukturellen Transformation. In dem neuen Ökosystem, das von Politik geleitet und von Staatsvermögen und Kapital stark konzentriert ist, kann man nur die sicheren Chancen in der Unsicherheit erfassen, indem man sich an die Trends anpasst und flexibel reagiert.
Am 11. und 12. Juni im Liangzhu Cultural and Art Center in Hangzhou wird die 36Kr WAVES New Wave 2025 Konferenz unter dem Thema „Neue Ära“ stattfinden. Dabei werden Top-Anleger aus dem Risikokapitalbereich, Gründer von aufstrebenden Unternehmen sowie Wissenschaftler, Schöpfer und Wissenschaftler, die sich auf Technologie, Innovation und Geschäft konzentrieren, zusammenkommen, um über führende Themen wie die technologische Revolution von KI, die globale Welle und die Neubewertung von Werten zu diskutieren, ihre Vorstellungen von kommerziellem Ideal und der zukünftigen Welt zu entpacken und gemeinsam die „Neue Ära“ des chinesischen Risikokapitals zu suchen und hinzusteuern.

·
Am Vormittag des 12. Juni hielt Gong Yuan, ein Anleger von Sequoia China, auf der Gründerveranstaltung eine unabhängige Rede mit dem Thema „Wie definiert man in der zweiten Hälfte der KI-Ära „gute Fragen“?“ Hier ist der vollständige Text der Rede:
Hallo zusammen! Ich bin Gong Yuan von Sequoia China. Ich bin froh, von 36Kr und Dark Waves eingeladen zu werden und heute mit Ihnen teilen zu können. Das Thema, über das ich heute sprechen möchte, ist mit unserem kürzlich vorgestellten xbench verbunden. xbench ist der erste Benchmark-Test für Large Language Models und AI Agenten, der von einer Investmentgesellschaft vorgestellt wurde. Warum haben wir diesen Benchmark-Test vorgestellt? Ich möchte Ihnen heute die Geschichte dahinter erzählen.
·
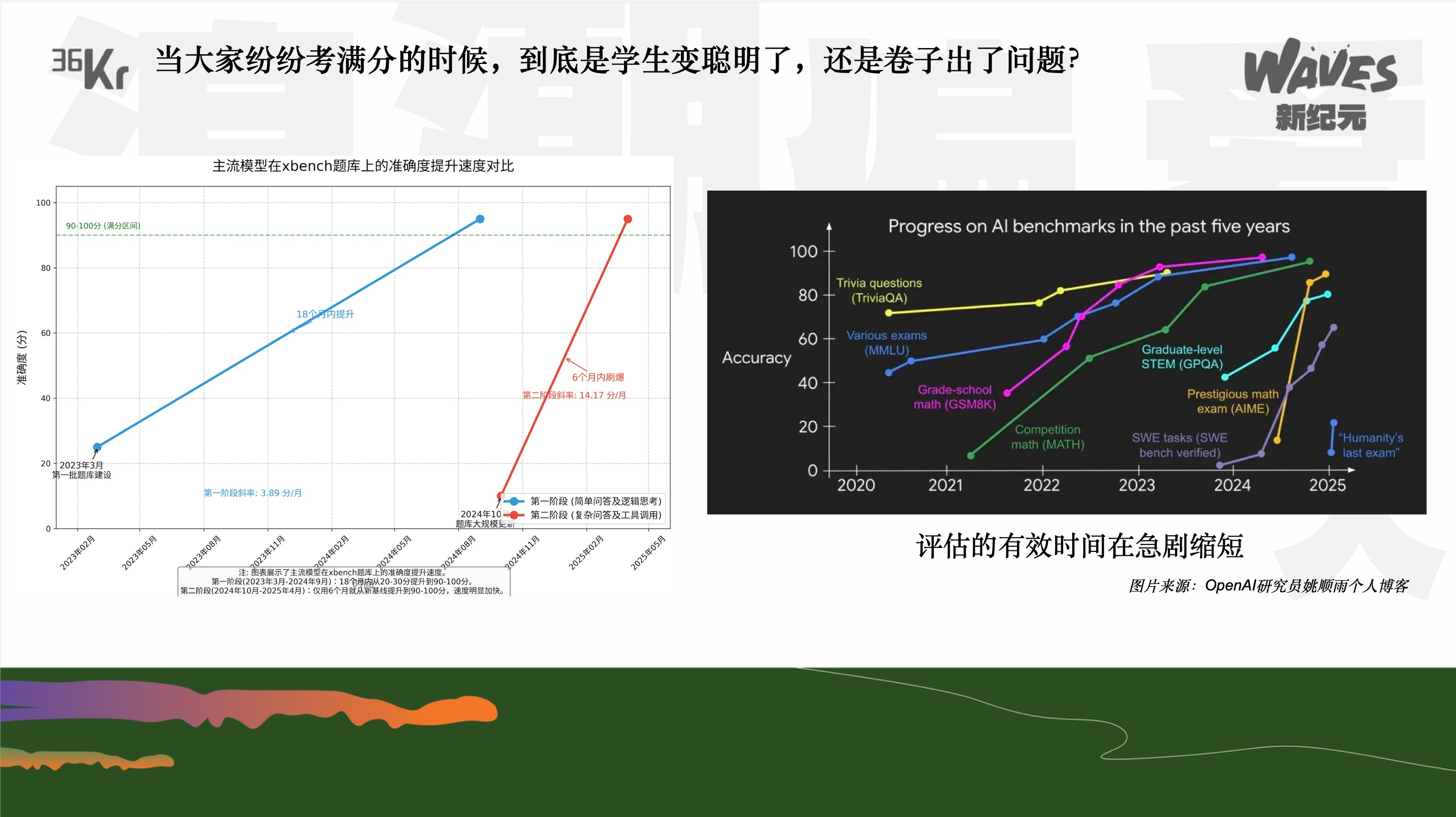
Diese beiden Bilder: Links ist das Benchmark, das Sequoia zuvor intern verwendet hat, mit zwei Aktualisierungen und der Geschwindigkeit, wie schnell es von Large Language Models auf 100 Punkte gebracht wurde. Das zweite Bild ist ein Bild aus einem bekannten Blog vor einiger Zeit, das die Zeit zeigt, die alle gängigen Benchmarks auf dem Markt benötigten, um von Large Language Models auf 100 Punkte gebracht zu werden. Man kann sehen, dass die Trends sehr ähnlich sind und ein Problem in der ersten Hälfte der KI-Ära aufzeigen: Wenn die verstärkte Lernmethode als effektiv bewiesen wird, wird jedes Mal, wenn ein neues Datensatz und ein neuer Teststandard auftaucht, das Large Language Model immer bis zum SOTA trainiert, und bald wird es einen neuen Benchmark geben, und das Large Language Model wird wieder SOTA. Dies führt zu einem endlosen Zyklus, was die Herausforderung ist, die wir in der ersten Hälfte gesehen haben.
Das führt uns zu der Frage, die wir stellen müssen: Wenn alle Large Language Models 100 Punkte erreichen, ist es wirklich, dass das Modell schlauer geworden ist, oder liegt das Problem am Test? Deshalb mussten wir uns in der dritten Aktualisierung des Tests diese Frage stellen.

·
Schauen wir uns an, was wir in den letzten zwei Jahren und mehr bei unseren drei Iterationen getan haben.
Zum ersten Mal, kurz nachdem ChatGPT herauskam, dachten wir, dass Large Language Models eine sehr wichtige Investitionschance und eine einmal in zehn Jahren oder sogar noch seltener auftretende große Welle sein könnten. Deshalb mussten wir intern einen neuen Standard und ein internes Werkzeug aufbauen, um die Entwicklung der Modelle in Echtzeit zu beobachten und bessere Investitionsentscheidungen für die damaligen Large Language Model-Projekte auf dem Markt zu treffen. Also haben wir so ein „Testpapier“, einen Benchmark, erstellt. Die Fragen in unserem ersten Benchmark waren sehr einfach, nur einfache Logik- und Mathematikfragen, wie z.B. „Was ist die Quadratwurzel einer Banane?“ Alles sehr einfache Logikfragen.
Sehr schnell wurde unser erster Benchmark auf 100 Punkte gebracht, und dann haben wir die zweite Aktualisierung vorgenommen. Ich erinnere mich, dass es kurz nachdem OpenAI o1 herauskam war. Wir haben die Fragen auf eine schwierigere Schwierigkeitsstufe gebracht. Man kann sehen, dass es für normale Menschen schwer ist, diese Fragen sofort zu beantworten. Aber die zweite Aktualisierung wurde noch schneller auf 100 Punkte gebracht. Beim ersten Mal haben wir vielleicht fast ein Jahr gebraucht, beim zweiten Mal vielleicht sechs Monate, und schon konnten die Large Language Models 100 Punkte erreichen.
Als wir im März dieses Jahres die dritte Aktualisierung vornahmen, begannen wir uns zu fragen, wie wir in der „zweiten Hälfte der KI-Ära“ gute Fragen stellen sollten?
Offensichtlich sind wir in ein ähnliches Denkmuster wie viele Forscher geraten. Wir sind im Rutsch, dass die Fragen immer schwieriger werden und die Modelle immer schlauer werden, immer weiter gegangen. Aber ist dieses Denkmuster wirklich richtig? Dies war die wichtigste Frage, die wir uns bei der dritten Aktualisierung stellten: Wollen Anleger und Gründer wirklich, dass die Modelle immer schlauer werden und immer schwierigere Fragen beantworten können? Hat ein immer schlaueres Investitionsmodell einen Investitionswert? Was ist die Beziehung dazwischen? Wir begannen uns ständig solche Fragen zu stellen.
Investitionen müssen in Produkte und Technologien mit wirtschaftlichem Nutzen gehen. Das heißt, Large Language Models und KI-Produkte müssen zu Unternehmen werden, die wirklich kommerziellen Wert schaffen können. Aber besteht ein proportionaler Zusammenhang oder eine vollständige Korrelation zwischen der Tatsache, dass die Modelle immer schlauer werden, und ihrem wirtschaftlichen Nutzen? Nehmen wir ein einfaches Beispiel: Für einen Programmierer hat das Schreiben von Programmen einen wirtschaftlichen Nutzen, und für ein Modell ist es eine relativ einfache Frage. Aber ein Large Language Model kann nicht auf einer Baustelle Bauarbeiten ausführen. Also besteht keine vollständige Übereinstimmung zwischen diesen beiden Dingen.
Deshalb haben die dritte Aktualisierung uns zu zwei wichtigen Dingen geführt: Erstens müssen wir das Denkmuster brechen und wirklich anhalten, um zu überlegen, was die Beziehung zwischen „schwierigere Fragen“ und „wirtschaftlicher Nutzen“ tatsächlich ist. Können wir einen Standard aufstellen, der uns ermöglicht, während des Investitionsprozesses einerseits die zunehmende Intelligenz und andererseits die zunehmende Nützlichkeit zu bewerten? Diese beiden Dinge könnten gleich wichtig sein. Zweitens, wie wir gesehen haben, werden unsere Fragen ständig auf 100 Punkte gebracht, und dann stellen wir schwierigere Fragen. Aber wie vergleichen wir zwei verschiedene Testpapiere? Es ist wie wenn ein Student 20 Punkte bei einem Doktoranden-Test und 100 Punkte bei einem Primarschul-Test bekommt. Wie können wir diese beiden Ergebnisse vergleichen, um seine echte Fähigkeitsentwicklung zu sehen? Dies ist unsere zweite Frage. Mit anderen Worten, wie können wir ein langfristiges Bewertungssystem aufbauen?
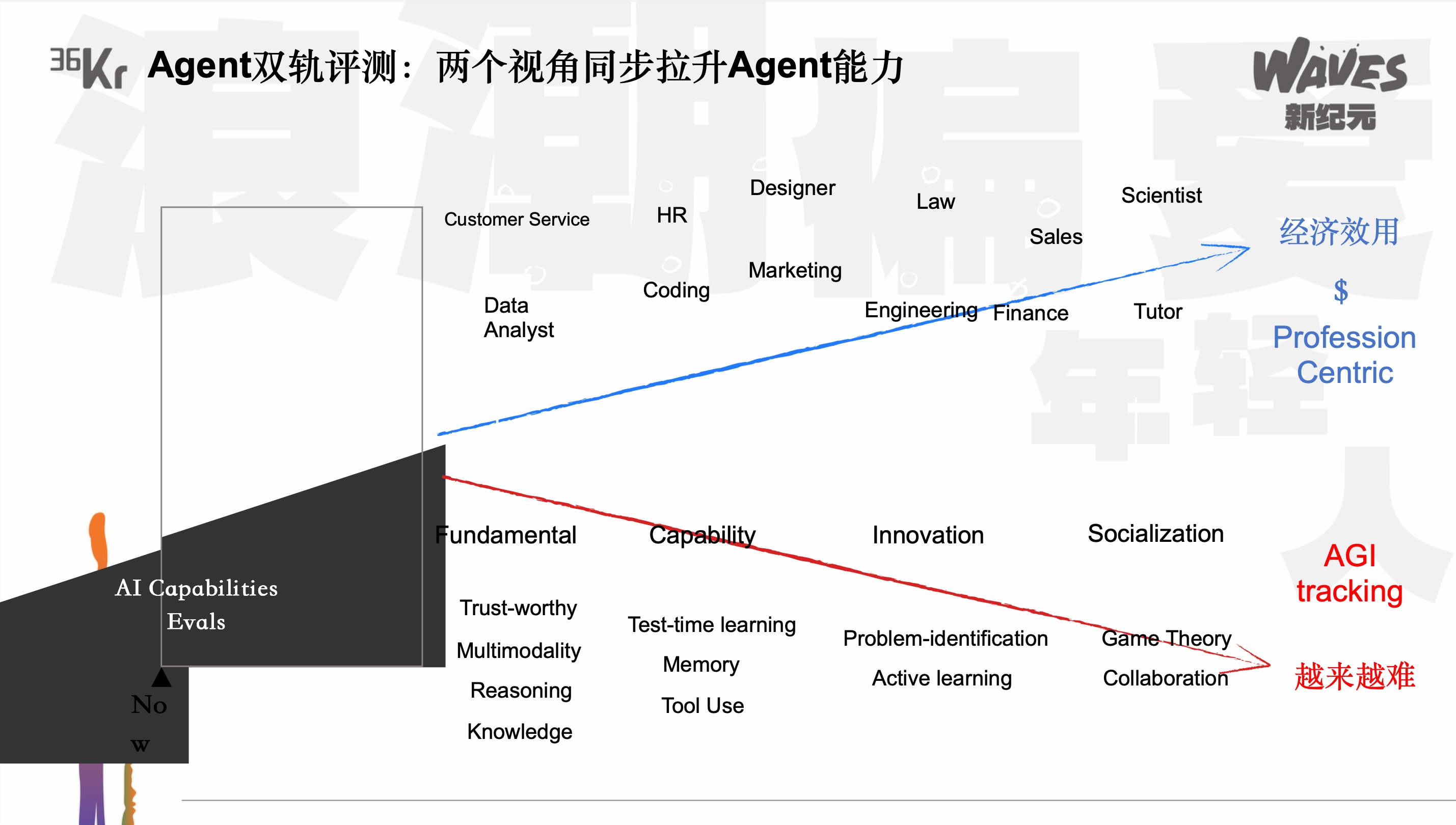
Ich möchte im Hinblick auf die erste Frage unsere Überlegungen und Logik näher erläutern. Nehmen wir als Beispiel die Suchfunktion, eine Teilfähigkeit von KI. Wenn KI in der Schule wäre und immer schwierigere Fragen beantworten würde, wo würde sich das zeigen? Das wäre unser AGI Track, bei dem es zuerst einfache Suchfragen beantwortet, dann tiefere Suchfragen und schließlich noch tiefere Suchfragen. Das ist ähnlich wie der Lernprozess in der Schule.

·
Aber wenn es in die reale Welt geht und Arbeit macht, ändert sich die Suchfunktion oder das Bewertungssystem für es. Wenn wir einen Mitarbeiter einstellen, wann und in welchem Berufsfeld wird die Suchfunktion benötigt?
Es wird an vielen Stellen benötigt. Zum Beispiel in der Personalvermittlung muss man nach Bewerbungen suchen. Das ist ein typisches Beispiel für die Suchfunktion. Für eine Marketingabteilung muss man Influencer suchen, mit ihnen Kontakt aufnehmen und Werbung schicken. Auch das ist eine Suchfunktion. Tatsächlich gibt es in vielen Berufsfeldern diese Suchfunktion, aber die Fragen und der Wert, die damit verbunden sind, sind unterschiedlich. Die Suchfragen werden zu Fragen, die wirklich mit der realen Produktivität und dem kommerziellen Wert zusammenhängen und deren tatsächlichen kommerziellen Wert berechnet werden kann. Sie ersetzen die Arbeit, die von Menschen wiederholt werden muss.
Wenn man diesen Gedanken verfolgt, kann man sehen, dass jede KI-Fähigkeit in zwei Tracks aufgeteilt werden kann: Unten ist der AGI Track, der die Lernfähigkeit bewertet. Oben ist der Profession-aligned Track, der den wirtschaftlichen Nutzen der KI in der realen Welt und in der Produktivitätsphase bewertet. Wir sagen als Scherz, dass der untere Track die Fähigkeit der KI misst, immer schlauer zu werden und ein Exzellenzstudent zu sein, während der obere Track ihre Fähigkeit misst, Arbeit zu leisten und Menschen zu helfen. Sie korrespondieren miteinander, denn jede Verbesserung der KI-Fähigkeit kann eine Anwendungsfläche eröffnen. Wir haben gerade ein sehr kleines Beispiel gegeben. Wenn die KI die Suchfunktion hat, kann sie möglicherweise HR- und Marketingarbeiten verrichten.
Was wird als nächstes mit der KI passieren? Wenn die KI jetzt multimodale Fähigkeiten hat, kann sie in der realen Welt möglicherweise wirtschaftlich wertvollere Arbeiten verrichten, wie z.B. die Erstellung und Bearbeitung von Videos. Wenn sie noch höhere Fähigkeiten hat, wie z.B. Transaktions- und Spieltheorie-Fähigkeiten, können wir sie möglicherweise in der realen Welt für höhere Transaktionen und Interaktionen mit Menschen einsetzen.
Man kann verstehen, dass der AGI Track eine Stufe für den wirtschaftlichen Nutzen ist. Wenn man einen unteren Track aktiviert, steigt die KI auf die nächste Stufe. Dies ist das Zwei-Schienen-Bewertungssystem, das wir in xbench eingeführt haben. Wir hoffen auch, dass dieses Bewertungssystem allen KI-Gründern und KI-Forschern helfen kann, die Kluft zwischen KI-Fähigkeiten und wirtschaftlichem Nutzen zu überbrücken.
·
Das zweite Thema, das wir erwähnt haben, ist die Langzeitbewertung. Wie können wir ein Bewertungssystem aufbauen, das langfristig funktioniert? Wir haben gerade ein Beispiel gegeben: Wenn ein Student 20 Punkte bei einem Doktoranden-Test und 100 Punkte bei einem Primarschul-Test bekommt, hat seine Fähigkeit zwar zugenommen, aber seine Punktzahl hat sich verändert. Wie können wir als Bewertende, Anleger oder Entwickler von Modellen und Agenten, die Steigung der Kurve spüren, um zu wissen, wie sich die Agenten in der Vergangenheit und in der Zukunft entwickelt haben? Nur wenn wir die Entwicklung der Steigung verstehen, können wir die KI wie einen Menschen in der realen Welt bewerten und den sogenannten TMF beurteilen.
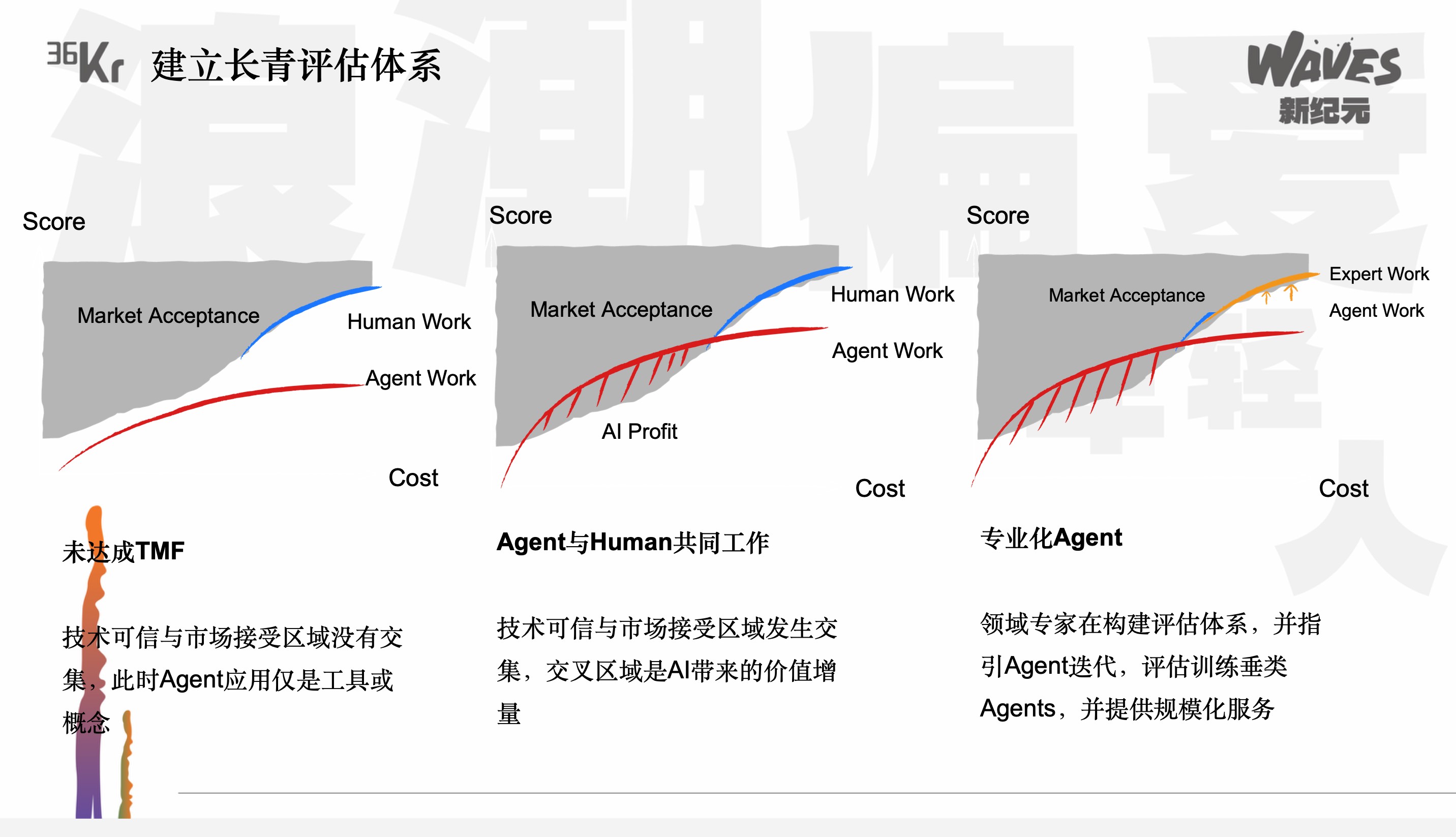
·
In der Vergangenheit war das Konzept des PMF weit verbreitet. Hier stellen wir jedoch vor, dass man in der neuen Ära den TMF bewerten sollte. Was bedeutet das? Wenn man die Fähigkeit der Agenten aus der Perspektive des stetigen Anstiegs bewertet, kann man sehen, dass diese Fähigkeit sich der menschlichen Fähigkeit immer mehr annähert und mit ihr in drei Phasen zusammenhängt. Bevor der TMF erreicht wird, bedeutet das, dass die Fähigkeit der Agenten hinter der menschlichen Fähigkeit zurückbleibt. Es ist eine Gesellschaft und Arbeit, die von Menschen dominiert wird. Danach gehen wir voraus, dass die Welt in Zukunft noch zwei Schritte durchlaufen wird. Der erste Schritt ist, dass der TMF erreicht wird, aber die Agenten können möglicherweise nur repetitive und einfache Arbeiten verrichten oder nur einen kleinen Teil einer langen Arbeit. Im weiteren Verlauf werden wir möglicherweise immer spezialisiertere Agenten sehen. Das Aufbauen eines stetigen Anstiegs und das Verfolgen der Veränderung der Agenten-Fähigkeit (Delta) kann uns helfen, den Investitionswendepunkt besser zu verstehen und Gründern zu helfen, zu wissen, wann sie in einen Marktsegment für Agenten eintreten sollten.

·
Dies ist das Bewertungsbild unserer ersten Ausgabe mit zwei Tracks. Hier sind die Top-Drei der vier Listen unserer ersten