Ein Startup von ehemaligen Mitgliedern des Zhipu-Teams: Lenovo hat die Beteiligung an einem Unternehmen für Large Language Models (LLMs) für humanoide Roboter geleitet | Exklusivbericht von Yingke
Autor | Huang Nan
Redakteur | Yuan Silai
Hard Kr hat erfahren, dass Beijing BeingBeyond Technology Co., Ltd. (im Folgenden als "BeingBeyond" bezeichnet, englischer Name: BeingBeyond) kürzlich eine Finanzierung im Wert von mehreren Millionen Yuan abgeschlossen hat. Lenovo Star führte die Investition an, gefolgt von Xinglian Capital (Z Fund), Yanyuan Venture Capital und Binfu Capital. Potential Capital fungierte als exklusiver Finanzberater. Die Mittel werden für eine verstärkte Investition in die Kerntechnologie - Forschung und - Entwicklung eingesetzt, um die Iteration bestehender Modelle und die industrielle Verifizierung zu beschleunigen und so die technologischen Barrieren und die Produktwettbewerbsfähigkeit kontinuierlich zu erhöhen.
BeingBeyond wurde im Januar 2025 gegründet und konzentriert sich auf die Forschung, Entwicklung und Anwendung von allgemeinen Großen Modellen für humanoide Roboter. Der Gründer, Lu Zongqing, ist ein beurlaubter Assistentprofessor an der Fakultät für Informatik der Peking Universität. Er war der Direktor des Multimodal Interaction Research Center an der Peking Academy of Artificial Intelligence und verantwortlich für das erste Projekt eines allgemeinen intelligenten Agenten im Rahmen des Original Exploration Program der National Natural Science Foundation of China. Viele Kernmitglieder stammen von der Peking Academy of Artificial Intelligence und haben reiche technische Forschungs - und Entwicklungs - sowie Anwendungsimplementierungs - Erfahrungen in Bereichen wie Verstärkungslernen, Computervision, Roboterkontrolle und Multimodalität.
Derzeit sind die Datengröße und die Generalisierungsfähigkeit die Kernwidersprüche, die die Leistungserhöhung von eingebetteten Gehirnen einschränken. Einerseits müssen eingebettete intelligente Roboter für die Erzielung hochgradig anthropomorpher Handlungs - und Entscheidungsfähigkeiten auf massenhafte und vielfältige Daten für eine tiefe Schulung angewiesen sein. Diese Daten umfassen verschiedene Szenarien wie alltägliche triviale Operationen und Interaktionen in komplexen Umgebungen, und die Datengröße wächst exponentiell. Allerdings steht der Datensammelvorgang immer noch vor mehreren Schwellen wie Technologie und Ressourcen. Er ist auf eine große Menge an Arbeitskraft angewiesen, schwierig und die Speicherkosten steigen rapide mit dem Anstieg des Datenvolumens.
Andererseits sind Roboter auch bei massiver Datenunterstützung für die flexible Bewältigung neuer Aufgaben, neuer Objekte und neuer Störungen in unbekannten Umgebungen immer noch auf eine starke Generalisierungsfähigkeit angewiesen. Wenn bestehende Modelle jedoch signifikant unterschiedlichen Szenarien gegenüberstehen, ist ihre Leistung mäßig. Es ist schwierig, das erworbene Wissen effektiv auf neue Situationen zu übertragen, und ihre Anpassungsfähigkeit in der praktischen Anwendung ist schlecht.
Daher ist es zu einer Schlüsselfrage geworden, wie man die Generalisierungsfähigkeit bei begrenzter Datengröße verbessern kann, damit eingebettete Gehirne die Leistungsschranke durchbrechen und sich der praktischen Anwendung nähern können.
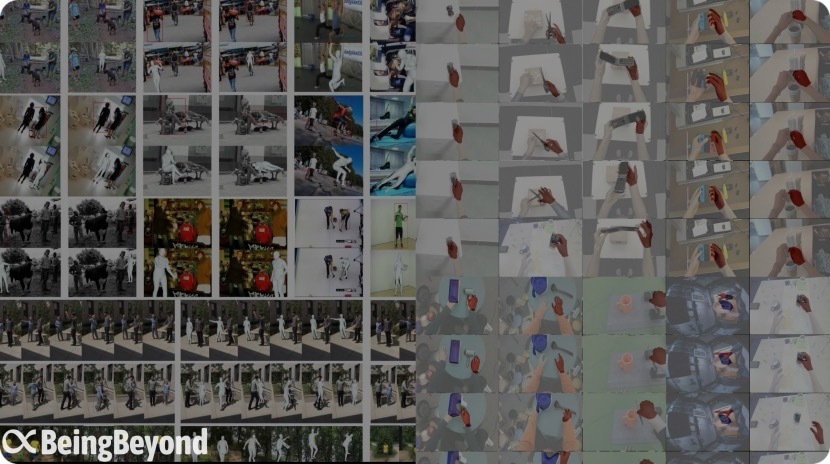
Die vortrainierten Daten, die von BeingBeyond verwendet werden (Quelle: Firma)
Für die beiden Kernfähigkeiten von humanoide Roboter, nämlich Operation und Bewegung, teilt BeingBeyond sein allgemeines Großmodellsystem in drei Schichten auf: das eingebettete multimodale Großsprachenmodell, das multimodale Positionsgroßmodell und das Bewegungsmodell, und hat ein selbstlernendes eingebettetes intelligentes Agentenframework aufgebaut.
Lu Zongqing sagte Hard Kr, dass sich die vortrainierten Daten von BeingBeyond von anderen Modellen unterscheiden. Sie stammen aus Videos von menschlichen Bewegungen und Handoperationen im Internet. Durch die Analyse der Handlungssequenzen in diesen natürlichen Szenarien wird eine Vortrainingsgrundlage für die Bewegungs - und Operationsfähigkeit des Roboters geschaffen. Dieser von öffentlichen Videodaten angetriebene Technologieweg durchbricht die starke Abhängigkeit traditioneller Lösungen von echten Roboterdaten und kann eine cross - modale Migration von "menschlicher Verhaltensdemonstration" zu "Roboterhandlungsgenerierung" erreichen.
Konkret hat BeingBeyond ein multimodales Positionsmodell vorgeschlagen. Durch die reichen Videoressourcen im Internet, einschließlich ganzkörperlicher menschlicher Bewegungen wie Gehen und Tanzen sowie feiner Handoperationsdaten aus erster Personensicht wie Greifen von Objekten und Gebrauch von Werkzeugen, kann es reichhaltige und vielfältige Handlungsproben für das Modell bereitstellen. Anhand dieser Video - Handlungsdaten kann das Modell die Manifestationsformen verschiedener Handlungen in verschiedenen Umgebungen lernen und kann auf der Grundlage von Echtzeitumgebungsinformationen und Aufgabenanforderungen generalisierte Ende - zu - Ende - Bewegungsoperationen erreichen.
In Bezug auf das eingebettete multimodale Großsprachenmodell hat BeingBeyond die Video Tokenizer - Technologie selbst entwickelt, die das Verständnis und die Schlussfolgerungsfähigkeit der raum - zeitlichen Umgebung betont, insbesondere die Analyse von Videoinhalten aus erster Personensicht. Durch die Dekonstruktion des kontinuierlichen Videostroms in visuelle Token - Einheiten mit sowohl Zeitreihe als auch räumlicher Semantik kann dieses Modell die sequentielle Logik von Handlungen genau erfassen, wie z. B. den kontinuierlichen Prozess des Ausstreckens der Hand, des Anhebens des Arms und des Greifens eines Objekts, und die physische Welt und das menschliche Verhalten auf der Grundlage räumlicher Merkmale wie der Position des Objekts und der relativen Position der Gliedmaßen verstehen.
Derzeit hat zwar die einfache Kombination von multimodalem Großsprachenmodell und Bewegungsoperationsstrategie bereits die Bedingungen für die kommerzielle Umsetzung, aber aufgrund der dynamischen Umweltveränderungen in realen Szenarien ist es schwierig, die Generalisierungsfähigkeit von Robotern anzupassen. Wie können humanoide Roboter die Fähigkeit des autonomen Lernens erlangen, ist das Schlüsselpunkt für ihre kommerzielle Umsetzung geworden.
Zu diesem Zweck hat BeingBeyond das Retriever - Actor - Critic - Framework vorgeschlagen. Durch die kollaborative Anwendung von RAG (Retrieval - Augmented Generation) von echten Interaktionsdaten und Verstärkungslernen kann es nicht nur die Antwortgenauigkeit des Modells und die Benutzererfahrung verbessern, sondern auch einen geschlossenen Kreis von "Datensammlung - Modelloptimierung - Effektfeedback" bilden, sodass der Roboter die Fähigkeit erhält, sich dynamisch an wechselnde Szenarien anzupassen und es wird ein praktikabler Technologieweg für seine großflächige Umsetzung bereitgestellt.

Vortraining + Nachtraining - Architektur (Quelle: Firma)
Lu Zongqing hat darauf hingewiesen, dass auf der Grundlage des Vortrainings von allgemeinen Bewegungsmodellen mit Internetvideos und dann durch spätere Anpassungsschulungen die Migration zu verschiedenen Roboterkörpern und Szenarien erreicht wird. Der Technologieweg von BeingBeyond kann den durch Hardwareiteration verursachten Datenverlust vermeiden und effektiv den Widerspruch zwischen der Knappheit von echten Roboterdaten und der Szenariogeneralisation lösen. Derzeit fördert das Unternehmen die Szenarioverifizierungskooperation mit führenden Robotermanufacturern, um die Anwendung und Umsetzung von eingebetteter Intelligenz in mehr Bereichen zu beschleunigen.
Ansichten der Investoren:
GAO Tianyao, Partner von Lenovo Star sagte, dass derzeit der Technologieweg von eingebetteten Großmodellen noch nicht konvergiert ist. Beispielsweise fehlt ein einheitliches Architekturparadigma. Der Technologieweg von BeingBeyond löst das Problem der begrenzten Quellen von Trainingsdaten. Gleichzeitig verbindet es auf modulare Weise die großen und kleinen Gehirne, um einen vollständigen Technologieframework aufzubauen. Im Vergleich zu ausländischen Teams mit ähnlichen Technologiewegen hat es Full - Stack - Technologiefähigkeiten. Mit eigenentwickelten Großmodellen wie multimodalen Großmodellen hat es eine starke Wettbewerbsfähigkeit bei der Lösung von Problemen wie Aufgaben - und Umgebungsgeneralisierung und Cross - Body von eingebetteten Großmodellen und erreicht allmählich die "Zero - Shot" - Generalisierung. Wir freuen uns auf die Umsetzung der Produkte von BeingBeyond in vielversprechenden Anwendungsbereichen und die Verwirklichung eines kommerziellen geschlossenen Kreises.
WANG Pu, Partner von Xinglian Capital (Z Fund) sagte: "Als Angel - Investor in BeingBeyond bin ich äußerst stolz, den Meilensteinbruch zu erleben, den Professor Lu Zongqing und sein Team auf dem Gebiet der allgemeinen humanoide Roboter erzielt haben. Vom Aufbau des ersten Millionenskalen - MotionLib - Datensatzes in der Branche bis zur Entwicklung des Ende - zu - Ende - Being - M0 - Handlungsgenerierungsmodells hat das Team nicht nur die Skaleneffekte von 'Big Data + Großmodell' in eingebetteter Intelligenz verifiziert, sondern auch einen technologischen geschlossenen Kreis für die Cross - Plattform - Handlungsmigration erreicht. Die Fähigkeit dieser Innovation, Textanweisungen in feine Roboterhandlungen umzuwandeln, bricht nicht nur die Grenzen traditioneller Methoden, sondern ebnet auch den Weg für Roboter, in tausende von Haushalten zu gelangen. Ich bin fest davon überzeugt, dass BeingBeyond weiterhin die Iteration der eingebetteten Intelligenz leiten wird - von der geschickten Operation bis zur ganzkörperlichen Bewegungssteuerung - und Roboter von dem Labor in den Alltag fördern wird. Wir werden uns mit BeingBeyond verbinden und gemeinsam mit allen einen neuen Zeitalter begrüßen, der von allgemeinen Robotern befähigt wird."